

近兩年,「大力(算力)出奇蹟」的大模型成為人工智慧領域多數研究者的追求趨勢。然而,背後龐大的運算成本與資源耗費問題也弊端漸顯,一部分科學家開始對大模型投以嚴肅的目光,並積極尋求解決之道。新的研究表明,要實現 AI 模型的優秀性能,並不一定要依靠堆算力與堆規模。
深度學習火熱十年,不得不說,其機會與瓶頸在這十年的研究與實踐中已吸引了大量的目光與討論。
其中,瓶頸維度,最引人注意的莫過於深度學習的黑盒子特性(缺乏可解釋性)與「大力出奇蹟」(模型參數越來越大,算力需求越來越大,計算成本也越來越高)。此外,還有模型的穩定性不足、安全漏洞等等問題。
而本質上,這些問題部分是由深度神經網路的「開環」系統性質所引起。要破除深度學習的B 面“魔咒”,單靠擴大模型規模與堆算力或許遠遠不夠,而是要追根溯源,從構成人工智能係統的基本原理,從一個新的視角(如閉環)理解“智能”。
7月12日,人工智慧領域的三位知名華人科學家馬毅、曹穎與沈向洋便聯名在arXiv上發表了一篇文章,「On the Principles of Parsimony and Self-Consistency for the Emergence of Intelligence”,提出了一個理解深度網路的新框架:壓縮閉環轉錄(compressive closed-loop transcription)。
這個框架包含兩個原理:簡約性(parsimony)與自洽性/自一致性(self-consistency),分別對應AI 模型學習過程中的“學習什麼”與“如何學習”,被認為是構成人工/自然智慧的兩大基礎,在國內外的人工智慧研究領域引起了廣泛關注。

論文連結:
https://arxiv.org/pdf/2207.04630.pdf
#三位科學家認為,真正的智能必須具備兩個特徵,一是可解釋性,二是可計算性。
然而,在過去十年,人工智慧的進步主要基於使用「蠻力」訓練模型的深度學習方法,在這種情況下,雖然AI 模型也能獲得功能模組來進行感知與決策,但學習到的特徵表示往往是隱式的,難以解釋。
此外,單靠堆疊算力來訓練模型,也使得AI 模型的規模不斷增大,計算成本不斷增加,且在落地應用中出現了許多問題,如神經崩潰導致學習到的表徵缺乏多樣性,模式崩潰導致訓練缺乏穩定性,模型對適應性和對災難性遺忘的敏感度不佳等等。
三位科學家認為,之所以出現上述問題,是因為當前的深度網路中,用於分類的判別模型和用於採樣或重播的生成模型的訓練在大部分情況下是分開的。此類模型通常是開環系統,需要透過監督或自我監督進行端到端的訓練。而維納等人早就發現,這樣的開環系統不能自動修正預測中的錯誤,也無法適應環境的變化。
因此,他們主張在控制系統中引入“閉環回饋”,讓系統能夠學習自行修正錯誤。在這次的研究中,他們也發現:用判別模型和生成模型組成一個完整的閉環系統,系統就可以自主學習(無需外部監督),並且更有高效,穩定,適應性也強。


圖註:左右到右分別為沈向洋(港中深校長講席教授,美國國家工程院外籍院士,原微軟全球執行副總裁) 、曹穎(美國國家科學院院士,加州大學柏克萊分校教授)與馬毅(加州大學柏克萊分校教授)。
#在這篇工作中,三位科學家提出了解釋人工智慧構成的兩個基本原理,分別是簡約性與自洽性(也稱為「自一致性」),並以視覺圖像資料建模為例,從簡約性和自洽性的第一原理推導出了壓縮閉環轉錄框架。
所謂簡約性,就是「學習什麼」。智慧的簡約性原理,要求系統透過計算有效的方式來獲得緊湊和結構化的表示。也就是說,智慧系統可以使用任何描述世界的結構化模型,只要它們能夠簡單有效地模擬現實感官資料中的有用結構。系統應該能夠準確有效地評估學習模型的好壞,並且使用的衡量標準是基礎、通用、易於計算和最佳化的。
以視覺資料建模為例,簡約原理試圖找到一個(非線性)變換f 來實現以下目標:
壓縮:將高維度感官資料x映射到低維表示z;
線性化:將分佈在非線性子流形上的每一類物件映射到線性子空間;
刮痕(scarification):將不同的類別映射到具有獨立或最大不連貫基礎的子空間。
也就是將可能位於高維度空間中的一系列低維子流形上的真實世界資料分別轉換為獨立的低維線性子空間系列。這種模型稱為「線性判別表示」(linear discriminative representation,LDR),壓縮過程如圖2 所示:
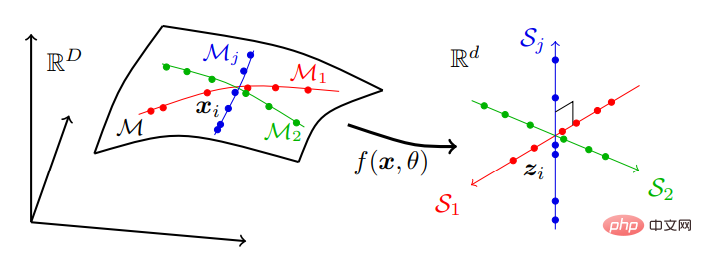
圖2:尋求線性和判別表示,將通常分佈在許多非線性低維子流形上的高維感官資料對應到與子流形具有相同維度的獨立線性子空間集。
在 LDR 模型系列中,存在著測量簡約性的內在測量。也就是說,給定一個 LDR,我們可以計算所有子空間上的所有特徵所跨越的總「體積」以及每個類別的特徵所跨越的「體積」總和。然後,這兩個體積之間的比率給出了一個自然的衡量標準,表明 LDR 模型有多好(往往越大越好)。
根據資訊理論,分佈的體積可以透過其速率失真來衡量。
馬毅團隊在2022年的一個工作「ReduNet: A White-box Deep Network from the Principle of Maximizing Rate Reduction」表明,如果使用高斯的率失真函數並選擇一個通用的深度網路(如ResNet)來對映射f(x, θ) 進行建模,透過最大限度地降低編碼率。

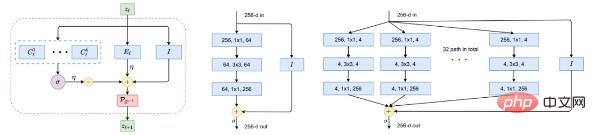
圖 5:非線性映射 f 的建構塊。圖左:ReduNet 的一層,作為投影梯度上升的迭代,它精確地由擴展或壓縮線性算子、非線性 softmax、跳過連接和歸一化組成。圖中和圖右:分別是一層 ResNet 和 ResNeXt。
敏銳的讀者可能已經認識到,這樣的圖表與ResNet(圖5 中間)等流行的「久經考驗」的深層網絡非常相似,包括ResNeXt 中的平行列(圖5 右)和專家混合(MoE)。
從展開最佳化方案的角度來看,這為一類深度神經網路提供了有力的解釋。甚至在現代深度網路興起之前,用於尋求稀疏性的迭代最佳化方案,例如 ISTA 或 FISTA 就已被解釋為可學習的深度網路。
透過實驗,他們證明,壓縮可以誕生一種有建設性的方式來推導深度神經網絡,包括它的架構和參數,作為一個完全可解釋的白盒:它的層對促進簡約的原理性目標進行迭代和增量優化。因此,對於如此獲得的深度網絡,ReduNets,從資料 X 作為輸入開始,每一層的算子和參數都以完全向前展開的方式建構和初始化。
這與深度學習中的流行做法非常不同:從隨機建構和初始化的網路開始,然後透過反向傳播進行全域調整。人們普遍認為,由於需要對稱突觸和複雜的回饋形式,大腦不太可能利用反向傳播作為其學習機制。在這裡,前向展開最佳化只依賴可以硬連線的相鄰層之間的操作,因此更容易實現和利用。
#一旦我們意識到深度網路本身的作用是進行(基於梯度的)迭代優化以壓縮、線性化和稀疏化數據,那麼就很容易理解過去十年人工神經網路的“進化”,尤其有幫助於解釋為什麼只有少數AI 系統透過人工選擇流程脫穎而出:從MLP 到CNN 到ResNet 到Transformer。
相比之下,網路結構的隨機搜索,例如神經架構搜索,並沒有產生能夠有效執行一般任務的網路架構。他們猜想,成功的架構在模擬資料壓縮的迭代最佳化方案方面變得越來越有效和靈活。前面提到的 ReduNet 和 ResNet/ResNeXt 之間的相似性可以例證。當然,還有許多其他例子。
自洽性是關於“如何學習”,即自主智慧系統透過最小化被觀察者和再生者之間的內在差異來尋求最自洽的模型來觀察外在世界。
僅憑簡約原則並不能確保學習模型能夠捕捉到感知外部世界資料中的所有重要資訊。
例如,透過最小化交叉熵將每個類別映射到一維「one-hot」向量,可以被視為一種簡約的形式。它可能會學習到一個好的分類器,但學習到的特徵會崩潰為單例,稱為「神經崩潰」。如此學習來的特徵不包含足夠的資訊來重新產生原始資料。即使我們考慮更一般的 LDR 模型類別,單獨的降速目標也不會自動確定環境特徵空間的正確維度。如果特徵空間維度太低,學習到的模型會欠擬合資料;如果太高,模型可能會過度擬合。
在他們看來,知覺的目標是學習一切可預測的知覺內容。智慧系統應該能夠從壓縮表示中重新產生觀察到的資料的分佈,生成後,無論它盡再大的努力,它本身也無法區分這個分佈。
論文強調,自洽和簡約這兩個原理是高度互補的,應該始終一起使用。僅靠自洽不能確保壓縮或效率方面的增益。
在數學和計算上,使用過度參數化的模型擬合任何訓練資料或透過在具有相同維度的領域之間建立一對一映射來確保一致性,而不需要學習資料分佈中的內在結構是很容易的。只有透過壓縮,智慧系統才能被迫在高維感知資料中發現內在的低維結構,並以最緊湊的方式在特徵空間中轉換和表示這些結構,以便將來使用。
此外,只有透過壓縮,我們才能容易地理解過度參數化的原因,例如,像DNN 通常透過數百個通道進行特徵提升,如果其純粹目的是在高在維特徵空間中進行壓縮,則不會導致過度擬合:提升有助於減少資料中的非線性,從而使其更容易壓縮和線性化。後續層的作用是執行壓縮(和線性化),通常層數越多,壓縮效果越好。
在壓縮到諸如 LDR 之類的結構化表示的特殊情況下,論文將一類自動編碼(具體見原論文)稱為「轉錄」(transcription)。這裡的困難在於如何使目標在計算上易於處理,從而在物理上可以實現。
速率降低 ΔR 給出了退化分佈之間的明確首要距離測量。但它僅適用於子空間或高斯的混合,而不適用於一般分佈!而我們只能期望內部結構化表示 z 的分佈是子空間或高斯的混合,而不是原始資料 x。
這導致了一個關於學習「自洽」表示的相當深刻的問題:為了驗證外部世界的內部模型是否正確,自主系統真的需要測量資料空間中的差異嗎?
答案是否定的。
關鍵是要意識到,要比較x 和x^,智能體只需要透過相同的映射f 比較它們各自的內部特徵z = f(x) 和z^ = f(x^),來使z 緊湊和結構化。
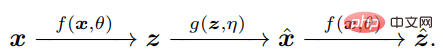
測量z 空間中的分佈差異實際上是定義明確且有效的:可以說,在自然智能中,學習內部測量差異是有獨立自主系統的大腦唯一可以做的事情。
這有效地產生了一個「閉環」回饋系統,整個過程如圖 6 所示。
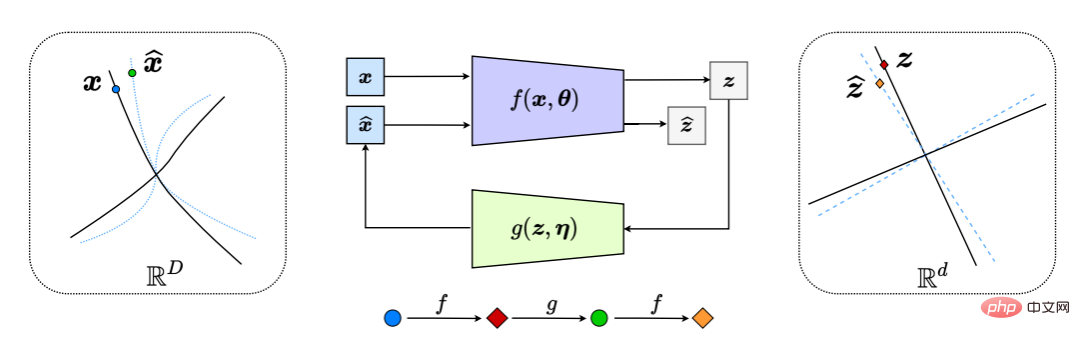
圖 6:非線性資料子流形到 LDR 的壓縮閉環轉錄(透過在內部比較和最小化 z 和 z^ 的差異)。這導致了編碼器/感測器f 和解碼器/控制器g 之間的自然追逃博弈,使解碼的x^(藍色虛線)的分佈追逐並匹配觀察到的數據x(黑色實線)的分佈。
人們可以將單獨學習 DNN 分類器 f 或生成器 g 的流行做法解釋為學習閉環系統的開放式部分(圖 6)。這種目前流行的做法與開環控制非常相似,控制領域早已知道它存在問題且成本高昂:訓練這樣的部分需要對期望的輸出(如類標籤)進行監督;如果資料分佈、系統參數或任務發生變化,這種開環系統的部署本質上是缺乏穩定性、穩健性或自適應性的。例如,在有監督的環境中訓練的深度分類網絡,如果重新訓練來處理具有新資料類別的新任務,通常會出現災難性的遺忘。
相較之下,閉環系統本質上較為穩定且自適應。事實上,Hinton 等人在1995年就已經提出了這一點。判別和生成部分需要分別作為完整學習過程的「喚醒」和「睡眠」階段結合。
然而,光是閉環是不夠的。
論文主張任何智能體都需要一種內在博弈機制,以便能夠透過自我批判進行自我學習!這當中遵循的是博弈作為一種普遍有效的學習方式的概念:反覆應用當前模型或策略來對抗對抗性批評,從而根據透過閉環收到的反饋不斷改進模型或策略!
在這樣的框架內,編碼器f 承擔雙重角色:除了透過最大化速率降低ΔR(Z) 來學習資料x 的表示z(如2.1 節中所做的那樣),它還應該作為反饋“感測器”,主動檢測數據x 和生成的x^ 之間的差異。解碼器g 也承擔雙重角色:它是控制器,與f 所檢測到的x 和xˆ 之間的差異聯繫起來;同時又是解碼器,嘗試將整體的編碼率最小化來實現目標(讓步於給定的準確度)。
因此,最優的「簡約」和「自洽」表示元組(z, f, g) 可以解釋為f(θ) 和g(η) 之間的零和賽局的平衡點,而不是基於組合速率降低的效用:
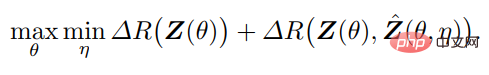
以上討論是兩個原理在有監督情況下的表現。
但論文強調,他們所提出的壓縮閉環轉錄框架能夠透過自我監督和自我批評來進行自我學習!
此外,由於速率降低已經為學習結構找到顯式(子空間類型)表示,使得過去的知識在學習新任務/資料時更容易保留,可以作為保持自一致性的先驗(記憶) 。
最近的實證研究表明,這可以產生第一個具有固定記憶體的自包含神經系統,可以在不遭受災難性遺忘的情況下逐步學習良好的 LDR 表示。對於這樣一個閉環系統,遺忘(如果有的話)是相當優雅的。
#此外,當再次將舊類別的圖像提供給系統進行審查時,可以進一步鞏固學習到的表示——這一特徵與人類記憶的特徵非常相似。從某種意義上說,這種受約束的閉環公式基本上確保了視覺記憶的形成可以是貝葉斯和自適應的——假設這些特徵對大腦來說是理想的話。
如圖8 所示,如此學習的自動編碼不僅表現出良好的樣本一致性,而且學習到的特徵還表現出清晰且有意義的局部低維度(薄)結構。

圖8:圖左:在CIFAR-10 資料集(有10 個類別的50,000 張影像)的無監督設定中學習的自動編碼的x 與相應解碼的x^ 之間的比較。圖右:10 個類別的無監督學習特徵的 t-SNE,以及幾個鄰域及其相關影像的可視化。注意可視化特徵中的局部薄(接近一維)結構,從數百維的特徵空間投影。
更令人驚訝的是,即使在訓練期間沒有提供任何類別信息,子空間或特徵相關的區塊對角結構也開始出現在為類別學習的特徵中(圖9)!因此,所學特徵的結構類似於在靈長類大腦中觀察到的類別選擇區域。
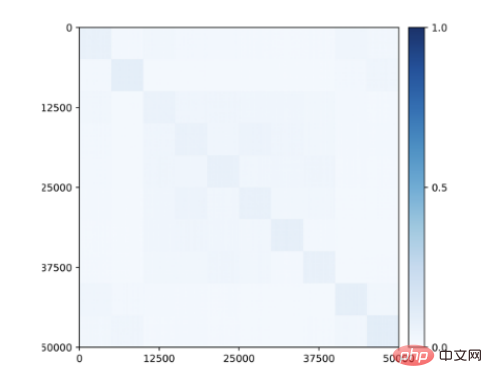
圖 9:透過閉環轉錄,屬於 10 個類別 (CIFAR-10) 的 50,000 張影像的無監督學習特徵之間的相關性。與類別一致的塊對角結構在沒有任何監督的情況下出現。
論文總結,簡約性和自洽性揭示了深度網路的角色是成為外部觀察和內部表徵之間非線性映射的模型。
此外,論文強調,閉環壓縮結構在自然界中無所不在,適用於所有智慧生物,這可以見於大腦(壓縮感覺訊息)、脊髓迴路(壓縮肌肉運動)、DNA(壓縮蛋白質的功能資訊)等等生物範例。因此,他們認為, 壓縮閉環轉錄可能是所有智慧行為背後的通用學習引擎。它使智慧生物和系統能夠從看似複雜和無組織的輸入中發現和提煉低維結構,並將它們轉換為緊湊和有組織的內部結構,以便記憶和利用。
為了說明這個框架的通用性,論文研究了另外兩個任務:3D 感知和決策(LeCun 認為這是自主智慧系統的兩個關鍵模組)。本文整理,僅介紹 3D 感知中電腦視覺與電腦圖形的閉環。
David Marr 在其頗具影響力的著作《視覺》一書中提出的3D 視覺經典範式提倡「分而治之」的方法,將3D 感知任務劃分為幾個模組化過程:從低階2D 處理(如邊緣偵測、輪廓草圖)、中級2.5D 解析(如分組、分割、圖形和地面),以及進階3D 重建(如姿勢、形狀)和識別(如物件),而相反,壓縮閉環轉錄框架提倡「聯合建構」思想。
感知是壓縮閉迴路轉錄?更準確地說,世界上物體的形狀、外觀甚至動態的 3D 表示應該是我們的大腦內部開發的最緊湊和結構化的表示,以相應地解釋所有感知到的視覺觀察。如果是這樣,那麼這兩個原理表明緊湊和結構化的 3D 表示就是要尋找的內部模型。這意味著我們可以並且應該在一個閉環計算框架內統一計算機視覺和計算機圖形,如下圖所示:
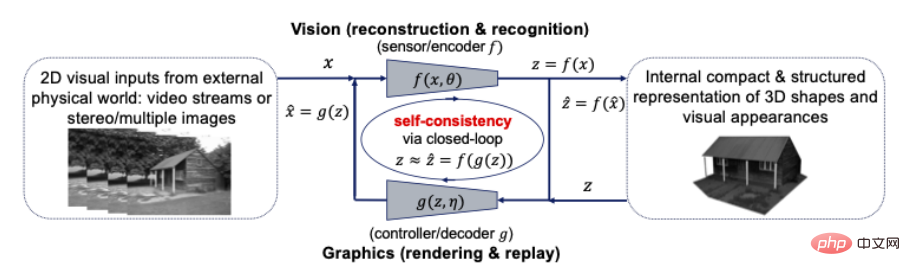
#圖10:計算機視覺和圖形之間的閉環關係,用於視覺輸入的緊湊和結構化3D 模型
電腦視覺通常被解釋為為所有 2D 視覺輸入重建和識別內部 3D 模型的前向過程,而電腦圖形學表示其對內部 3D 模型進行渲染和動畫處理的逆過程。將這兩個過程直接組合成一個閉環系統可能會帶來巨大的計算和實踐好處:幾何形狀、視覺外觀和動力學中的所有豐富結構(例如稀疏性和平滑度)可以一起用於統一的3D模型, 最緊湊,且與所有視覺輸入一致。
電腦視覺中的辨識技術可以幫助電腦圖形學在形狀和外觀空間中建立緊湊模型,並為創建逼真的 3D 內容提供新的方法。另一方面,電腦圖形學中的 3D 建模和模擬技術可以預測、學習和驗證電腦視覺演算法分析的真實物件和場景的屬性和行為。視覺和圖形社群長期以來一直在實踐「綜合分析」的方法。
外觀和形狀的統一表示?基於圖像的渲染,其中,透過從一組給定圖像中學習來生成新視圖,可以被視為早期嘗試用簡約和自洽的原理縮小視覺和圖形之間的差距。特別是,全光採樣表明,可以用所需的最少影像數量(簡約性)來實現抗鋸齒影像(自洽性)。
人們會期望基本的智能原理對大腦的設計產生重大影響。簡約和自洽原理為靈長類視覺系統的幾個實驗觀察提供了新的思路。更重要的是,它們揭示了未來實驗中要尋找的目標。
作者團隊已經證明,僅尋求內部簡約和預測性表示就足以實現“自監督”,允許結構自動出現在透過壓縮閉環轉錄學習的最終表示中。
例如,圖 9 顯示無監督資料轉錄學習自動區分不同類別的特徵,為在大腦中觀察到的類別選擇性表示提供了解釋。這些特徵也為靈長類大腦中稀疏編碼和子空間編碼的廣泛觀察提供了合理的解釋。此外,除了視覺數據建模,最近的神經科學研究表明,大腦中出現的其他結構化表示(例如「位置細胞」)也可能是以最壓縮的方式編碼空間訊息的結果。
可以說,最大編碼率降低(MCR2) 原理在精神上類似於認知科學中的「自由能最小化原理」(free energy minimization principle),後者試圖透過能量最小化為貝葉斯推理提供框架。但與自由能的一般概念不同,速率降低在計算上易於處理且可直接優化,因為它可以以封閉的形式表示。此外,這兩個原理的相互作用表明,正確模型(類)的自主學習應該透過對這種效用的閉環最大化博弈來完成,而不是單獨進行最小化。因此,他們相信,壓縮閉環轉錄框架為如何實際實施貝葉斯推理提供了一個新的視角。
這個框架也被他們認為闡明了大腦使用的整體學習架構,可以透過展開優化方案來建構前饋段,且不需要透過反向傳播從隨機網路中學習。此外,框架存在一個互補的生成部分,可以形成一個閉環回饋系統來指導學習。
最後,框架揭示了許多對「預測編碼」大腦機制感興趣的神經科學家所尋求的難以捉摸的「預測錯誤」信號,這是一種與壓縮閉環轉錄產生共振的計算方案:為了讓計算更容易,應在表示的最後階段測量傳入和產生的觀測值之間的差異。
馬毅等人的工作認為,壓縮閉環轉錄與Hinton等人在1995年提出的框架相比,在計算上更易於處理和可擴展。而且,循環的學習非線性編碼/解碼映射(通常表現為深度網絡),本質上在外部無組織的原始感官數據(如視覺、聽覺等)和內部緊湊和結構化表示之間提供了一個重要的「接口」。
#不過,他們也指出,這兩個原則不一定能解釋智能的所有面向。高級語意、符號或邏輯推理的出現和發展背後的電腦制仍然難以捉摸。直到今天,關於這種高階符號智能是可以從持續學習中產生還是必須進行硬編碼,仍然存在爭議。
在三位科學家看來,諸如子空間之類的結構化內部表示是高級語義或符號概念出現的必要中間步驟——每個子空間對應一個離散的(物件)類別。如此抽象的離散概念之間的其他統計、因果或邏輯關係可以進一步簡化建模為緊湊和結構化(例如稀疏)圖,每個節點代表一個子空間/類別。可以透過自動編碼來學習圖形以確保自一致性。
他們推測,只有在個體智能體學習的緊湊和結構化表示之上,高級智能(具有可共享的符號知識)的出現和發展才有可能。因此,他們建議,應該透過智慧系統之間有效的資訊交流或知識遷移來探索高級智慧出現的新原理(如果高級智慧存在的話)。
此外,更高層次的智慧應該與我們在本文中提出的兩個原理有兩個共同點:
只有具備可解釋和可計算性,我們才能無需依賴當前昂貴且耗時的「試錯」方法來推進人工智慧的進步,能夠描述完成這些任務所需的最少數據和計算資源,而不是簡單地提倡「越大越好」的蠻力方法。智慧不應該是最足智多謀的人的特權,在一套正確的原則下,任何人都應該能夠設計和構建下一代智能係統,無論大小,其自主性、能力和效率最終都可以模仿甚至超過動物和人類。
論文連結:
https://arxiv.org/pdf/2207.04630.pdf
以上是不盲追大模型与堆算力!沈向洋、曹颖与马毅提出理解 AI 的两个基本原理:简约性与自一致性的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















