

使用Catboost從RNN、ARIMA和Prophet模型中擷取訊號進行預測。
整合各種弱學習器可以提高預測精度,但是如果我們的模型已經很強大了,集成學習往往也能夠起到錦上添花的作用。流行的機器學習庫scikit-learn提供了一個StackingRegressor,可以用於時間序列任務。但是StackingRegressor有一個限制;它只接受其他scikit-learn模型類別和api。所以像ARIMA這樣在scikit-learn中不可用的模型,或是來自深度神經網路的模型都無法使用。在這篇文章中,我將展示如何堆疊我們能看到的模型的預測。

我們將使用到下面的套件:
pip install --upgrade scalecast conda install tensorflow conda install shap conda install -c conda-forge cmdstanpy pip install prophet
資料集每小時一次,分為訓練集(700個觀測值)和測試集(48個觀測值)。下面程式碼是讀取資料並將其儲存在Forecaster物件中:
import pandas as pd import numpy as np from scalecast.Forecaster import Forecaster from scalecast.util import metrics import matplotlib.pyplot as plt import seaborn as sns def read_data(idx = 'H1', cis = True, metrics = ['smape']): info = pd.read_csv( 'M4-info.csv', index_col=0, parse_dates=['StartingDate'], dayfirst=True, ) train = pd.read_csv( f'Hourly-train.csv', index_col=0, ).loc[idx] test = pd.read_csv( f'Hourly-test.csv', index_col=0, ).loc[idx] y = train.values sd = info.loc[idx,'StartingDate'] fcst_horizon = info.loc[idx,'Horizon'] cd = pd.date_range( start = sd, freq = 'H', periods = len(y), ) f = Forecaster( y = y, # observed values current_dates = cd, # current dates future_dates = fcst_horizon, # forecast length test_length = fcst_horizon, # test-set length cis = cis, # whether to evaluate intervals for each model metrics = metrics, # what metrics to evaluate ) return f, test.values f, test_set = read_data() f # display the Forecaster object
結果是這樣的:
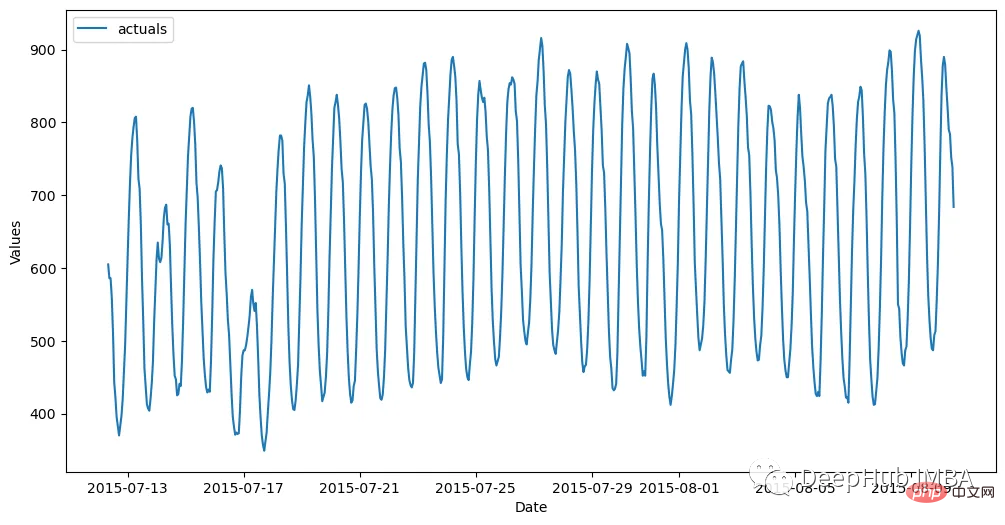
在我們開始建立模型之前,我們需要從中產生最簡單的預測,naive方法就是向前傳播最近24個觀測值。
f.set_estimator('naive')
f.manual_forecast(seasonal=True)然後使用ARIMA、LSTM和Prophet作為基準。
Autoregressive Integrated Moving Average 是一種流行而簡單的時間序列技術,它利用序列的滯後和誤差以線性方式預測其未來。透過EDA,我們確定這個系列是高度季節性的。所以最後選擇了應用order (5,1,4) x(1,1,1,24)的季節性ARIMA模型。
f.set_estimator('arima')
f.manual_forecast(
order = (5,1,4),
seasonal_order = (1,1,1,24),
call_me = 'manual_arima',
)如果說ARIMA是時間序列模型中比較簡單的一種,那麼LSTM就是比較先進的方法之一。它是一種具有許多參數的深度學習技術,其中包括一種在順序資料中發現長期和短期模式的機制,這在理論上使其成為時間序列的理想選擇。這裡使用tensorflow建立這個模型
f.set_estimator('rnn')
f.manual_forecast(
lags = 48,
layers_struct=[
('LSTM',{'units':100,'activation':'tanh'}),
('LSTM',{'units':100,'activation':'tanh'}),
('LSTM',{'units':100,'activation':'tanh'}),
],
optimizer = 'Adam',
epochs = 15,
plot_loss = True,
validation_split=0.2,
call_me = 'rnn_tanh_activation',
)
f.manual_forecast(
lags = 48,
layers_struct=[
('LSTM',{'units':100,'activation':'relu'}),
('LSTM',{'units':100,'activation':'relu'}),
('LSTM',{'units':100,'activation':'relu'}),
],
optimizer = 'Adam',
epochs = 15,
plot_loss = True,
validation_split=0.2,
call_me = 'rnn_relu_activation',
)#儘管它非常受歡迎,但有人聲稱它的準確性並不令人印象深刻,主要是因為它趨勢的推論有時很不切實際,而且它沒有透過自迴歸建模來考慮局部模式。但是它也有自己的特點。 1,它會自動將節日效果應用到模型身上,並且還考慮了幾種類型的季節性。可以以使用者所需的最低需求來完成這一切,所以我喜歡把它用作訊號,而不是最終的預測結果。
f.set_estimator('prophet')
f.manual_forecast()現在我們已經為每個模型產生了預測,讓我們看看它們在驗證集上的表現如何,驗證集是我們訓練集中的最後48個觀察結果。
results = f.export(determine_best_by='TestSetSMAPE') ms = results['model_summaries'] ms[ [ 'ModelNickname', 'TestSetLength', 'TestSetSMAPE', 'InSampleSMAPE', ] ]
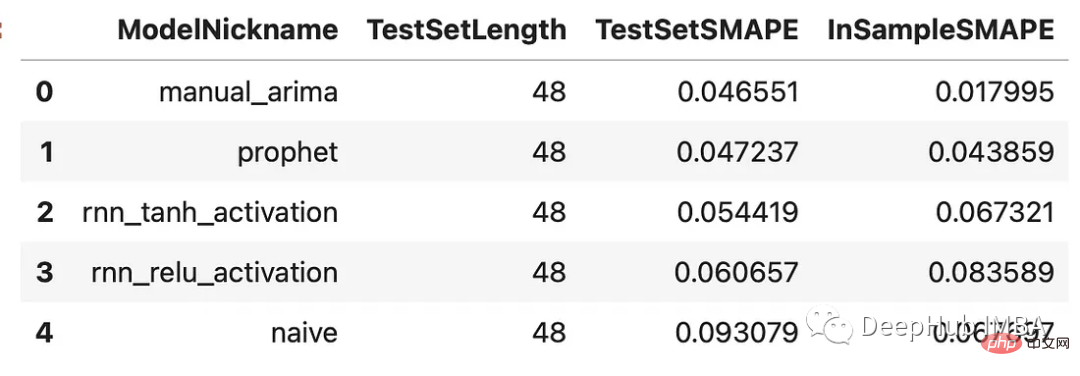
每個模型的表現都優於naive方法。 ARIMA模型表現最好,百分比誤差為4.7%,其次是Prophet模型。讓我們看看所有的預測與驗證集的關係:
f.plot(order_by="TestSetSMAPE",ci=True) plt.show()

所有這些模型在這個時間序列上的表現都很合理,它們之間沒有很大的偏差。下面讓我們把它們堆起來!
每個堆疊模型都需要一個最終估計器,它將過濾其他模型的各種估計,創建一組新的預測。我們將把先前結果與Catboost估計器疊在一起。 Catboost是一個強大的程序,希望它能從每個已經應用的模型中充實出最好的訊號。
f.add_signals(
f.history.keys(), # add signals from all previously evaluated models
)
f.add_ar_terms(48)
f.set_estimator('catboost')上面的程式碼將來自每個評估模型的預測加入到Forecaster物件中。它稱這些預測為「訊號」。它們的處理方式與儲存在同一物件中的任何其他協變數相同。這裡也加入了最後 48 個系列的滯後作為 Catboost 模型可以用來進行預測的附加迴歸變數。現在讓我們呼叫三種 Catboost 模型:一種使用所有可用訊號和滯後,一種僅使用訊號,一種僅使用滯後。
f.manual_forecast(
Xvars='all',
call_me='catboost_all_reg',
verbose = False,
)
f.manual_forecast(
Xvars=[x for x in f.get_regressor_names() if x.startswith('AR')],
call_me = 'catboost_lags_only',
verbose = False,
)
f.manual_forecast(
Xvars=[x for x in f.get_regressor_names() if not x.startswith('AR')],
call_me = 'catboost_signals_only',
verbose = False,
)下面可以比較所有模型的結果。我們將研究兩個測量:SMAPE和平均絕對比例誤差(MASE)。這是實際M4比賽中使用的兩個指標。
test_results = pd.DataFrame(index = f.history.keys(),columns = ['smape','mase'])
for k, v in f.history.items():
test_results.loc[k,['smape','mase']] = [
metrics.smape(test_set,v['Forecast']),
metrics.mase(test_set,v['Forecast'],m=24,obs=f.y),
]
test_results.sort_values('smape')
可以看到,通过组合来自不同类型模型的信号生成了两个优于其他估计器的估计器:使用所有信号训练的Catboost模型和只使用信号的Catboost模型。这两种方法的样本误差都在2.8%左右。下面是对比图:
fig, ax = plt.subplots(figsize=(12,6)) f.plot( models = ['catboost_all_reg','catboost_signals_only'], ci=True, ax = ax ) sns.lineplot( x = f.future_dates, y = test_set, ax = ax, label = 'held out actuals', color = 'darkblue', alpha = .75, ) plt.show()

为了完善分析,我们可以使用shapley评分来确定哪些信号是最重要的。Shapley评分被认为是确定给定机器学习模型中输入的预测能力的最先进的方法之一。得分越高,意味着输入在特定模型中越重要。
f.export_feature_importance('catboost_all_reg')
上面的图只显示了前几个最重要的预测因子,但我们可以从中看出,ARIMA信号是最重要的,其次是序列的第一个滞后,然后是Prophet。RNN模型的得分也高于许多滞后模型。如果我们想在未来训练一个更轻量的模型,这可能是一个很好的起点。
在这篇文章中,我展示了在时间序列上下文中集成模型的力量,以及如何使用不同的模型在时间序列上获得更高的精度。这里我们使用scalecast包,这个包的功能还是很强大的,如果你喜欢,可以去它的主页看看:https://github.com/mikekeith52/scalecast
本文的数据集是M4的时序竞赛:https://github.com/Mcompetitions/M4-methods
使用代码在这里:https://scalecast-examples.readthedocs.io/en/latest/misc/stacking/custom_stacking.html
以上是整合時間序列模型提高預測精度的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















