

大型預訓練語言模型其中一個重要的特點是上下文學習(In-Context Learning,ICL)能力,即透過一些示範性的輸入-標籤對,就可以在不更新參數的情況下對新輸入的標籤進行預測。
性能雖然上去了,但大模型的ICL能力到底從何而來仍然是一個開放的問題。
為了更好地理解ICL的工作原理,清華大學、北京大學和微軟的研究人員共同發表了一篇論文,將語言模型解釋為元優化器(meta- optimizer),並將ICL理解為一種隱性的(implicit)微調。

論文連結:https://arxiv.org/abs/2212.10559
#從理論上講,這篇文章弄清楚了Transformer注意力中存在一個基於梯度下降優化的對偶形式(dual form),並在此基礎上,對ICL的理解如下。 GPT首先根據示範實例產生元梯度,然後將這些元梯度應用於原始的GPT,並建立ICL模型。
在實驗中,研究人員綜合比較了ICL和基於真實任務的明確微調的行為,以提供支持該理解的經驗證據。
結果證明,ICL在預測層面、表徵層面和注意力行為層面的表現與明確微調類似。
此外,受到元優化理解的啟發,透過與基於動量的梯度下降演算法的類比,文中還設計了一個基於動量的注意力,比普通的注意力有更好的表現,從另一個方面再次支持了該理解的正確性,也展現了利用該理解對模型做進一步設計的潛力。
研究人員首先對Transformer中的線性注意力機制進行了定性分析,以找出它與基於梯度下降的最佳化之間的對偶形式。然後將ICL與顯式微調進行比較,並在這兩種最佳化形式之間建立連結。
Transformer注意力就是元優化
#設X是整個query的輸入表徵,X'是範例的表徵,q是查詢向量,則在ICL設定下,模型中一個head的注意力結果如下:
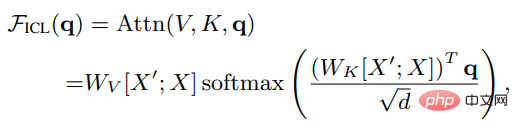
可以看到,移除縮放因子根號d和softmax後,標準的注意力機制可以近似為:
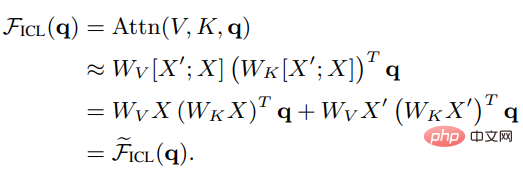
#將Wzsl設為Zero-Shot Learning(ZSL)的初始參數後,Transformer注意力可以轉換為下面的對偶形式:
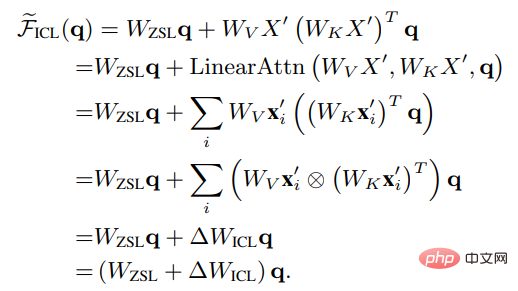
#可以看到,ICL可以解釋為一個元最佳化(meta -optimization)的過程:
1. 將基於Transformer的預訓練語言模型作為一個元優化器;
2. 透過正向計算,根據示範樣例計算元梯度;
3. 透過注意力機制,將元梯度應用於原始語言模型上,建立一個ICL模型。
為了比較ICL的元優化和顯式優化,研究人員設計了一個具體的微調設定作為比較的基線:考慮到ICL只直接作用在註意力的key和value,所以微調也只更新key和value投影的參數。
同樣在非嚴謹形式下的線性注意力中,微調後的head注意力結果可以被表述為:
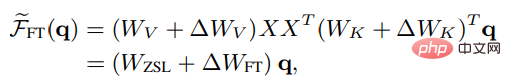
為了與ICL進行更公平的比較,實驗中進一步將微調設定限制如下:
#1. 將訓練範例指定為ICL的示範範例;
2. 只對每個例子進行一步訓練,其順序與ICL的示範順序相同;
3. 用ICL所用的模板對每個訓練樣例進行格式化,並使用因果語言建模目標進行微調。
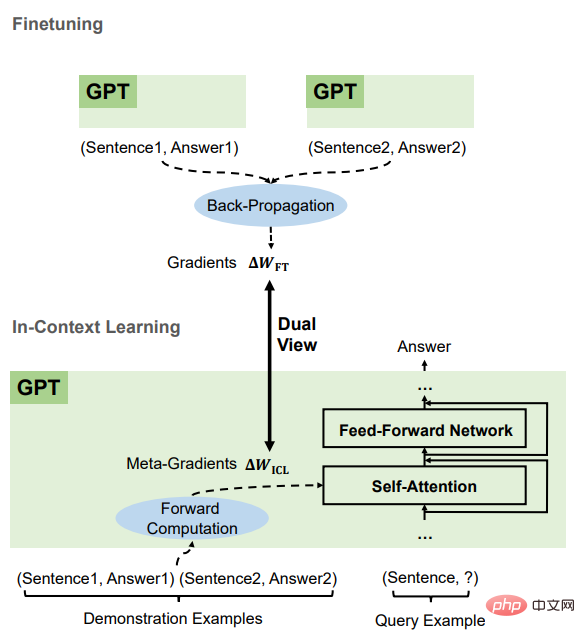
比較後可以發現,ICL與微調有許多共同的屬性,主要包括四個面向。
都是梯度下降
#可以發現ICL和微調都對Wzsl進行了更新,即梯度下降,唯一的區別是,ICL透過正向計算產生元梯度,而finetuning則透過反向傳播獲得真正的梯度。
相同的訓練資訊
ICL的元梯度是根據示範範例獲得的,微調的梯度也是從相同的訓練樣本中得到的,也就是說,ICL和微調共享相同的訓練資訊來源。
訓練範例的因果順序相同
#ICL和微調共享訓練範例的因果順序,ICL用的是decoder-only Transformers,因此示例中的後續token不會影響到前面的token;而對於微調,由於訓練示例的順序相同,並且只訓練一個epoch,所以也可以保證後面的樣本對前面的樣本沒有影響。
都作用於注意力
#與zero-shot學習相比,ICL和微調的直接影響都僅限於注意力中key和value的計算。對於ICL來說,模型參數是不變的,它將範例資訊編碼為額外的key和value以改變注意力行為;對於微調中引入的限制,訓練資訊也只能作用到注意力key和value的投影矩陣中。
基於ICL和微調之間的這些共同特性,研究人員認為將ICL理解為一種隱性微調是合理的。
任務與資料集
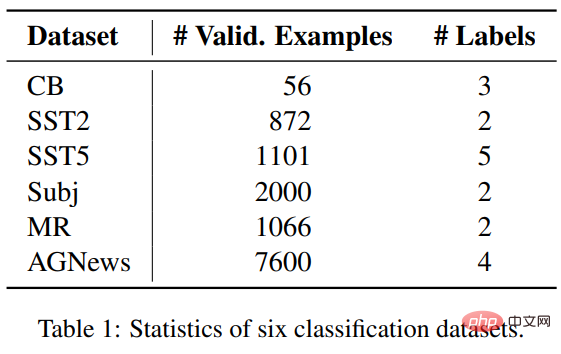
研究人員選擇了橫跨三個分類任務的六個資料集來對比ICL和微調,包括SST2、SST-5、MR和Subj四個用於情感分類的資料集;AGNews是一個主題分類資料集;CB用於自然語言推理。
實驗設定
模型部分使用了兩個類似GPT的預訓練語言模型,由fairseq發布,其參數量分別為1.3B和2.7B.
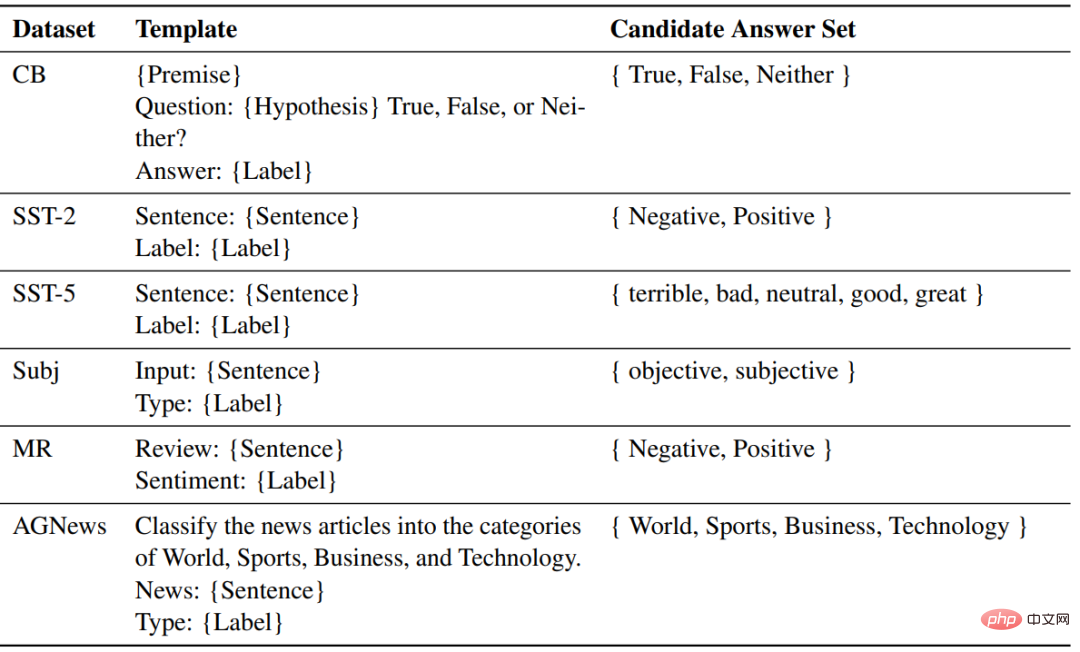
對於每個任務,使用相同的模板來對ZSL、ICL和微調的樣本進行格式化。
結果
#準確度
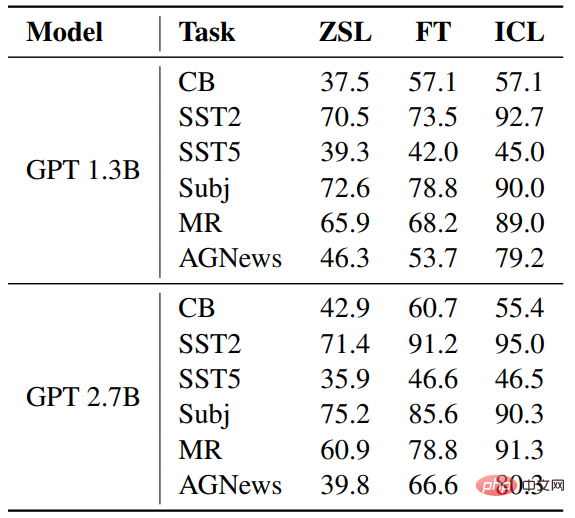
與ZSL相比,ICL和微調都取得了相當大的改進,這意味著它們的最佳化,對這些下游任務都有幫助。此外,ICL在少數情況下比微調更好。
Rec2FTP(Recall to Finetuning Predictions)
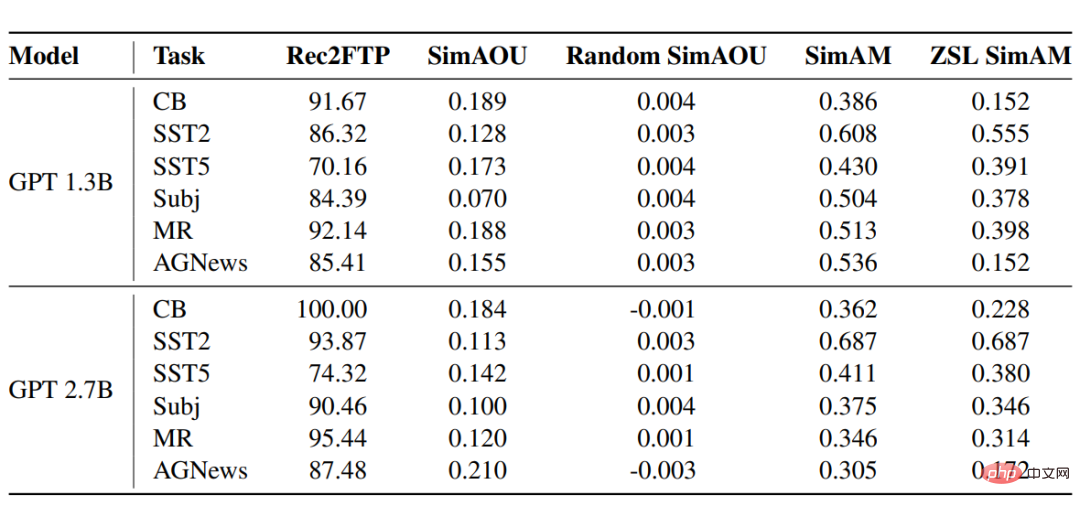
#GPT模型在六個資料集上的得分結果顯示,平均而言,ICL可以正確預測87.64%的例子,而微調可以修正ZSL。在預測層面,ICL可以涵蓋大部分正確的行為進行微調。
SimAOU(Similarity of Attention Output Updates)
從結果可以發現,ICL更新與微調更新的相似度遠高於隨機更新,也意味著在表示層面上,ICL傾向於以與微調變化相同的方向改變注意力結果。
SimAM(Similarity of Attention Map)
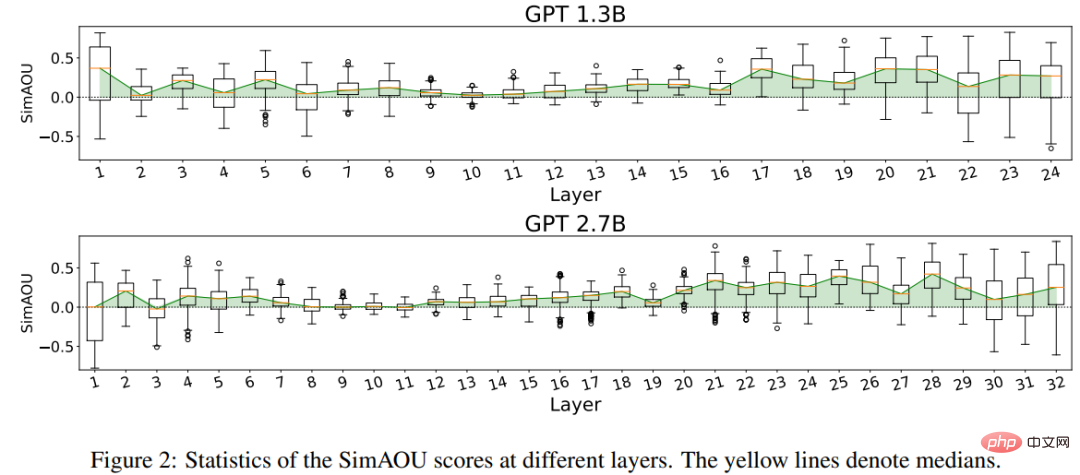
以上是清北微軟深挖GPT,把上下文學習整明白了!和微調基本一致,只是參數沒變而已的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















