

ChatGPT,這款近期發布的文本生成工具,已經在研究界引起了熱烈的討論。它能寫出學生作文、總結研究論文、回答問題、產生可用的電腦程式碼,甚至足以通過醫學考試、MBA 考試、司法考試……
其中一個關鍵的問題是:ChatGPT 可以被命名為研究論文的作者嗎?
現在,來自全球最大預印本發布平台 arXiv 官方的明確回答是:「不能」。
在ChatGPT 之前,研究者們早就在使用聊天機器人作為研究助手,幫助組織自己的思維,產生對自身工作的回饋,協助編寫程式碼以及對研究文獻進行摘要。
這些輔助工作似乎可以被認可,但說到「署名」,又完全是另外一回事。 「顯然,一個電腦程式不能為一篇論文的內容負責。它也不能同意arXiv 的條款和條件。」
有一些預印本和已發表的文章已經將正式的作者身分賦予ChatGPT。為了解決這個問題,arXiv 為作者採用了一項關於使用生成式 AI 語言工具的新政策。
官方聲明如下:
arXiv 認識到,科學工作者使用各種工具來進行他們所報告的科學工作以及準備報告本身,包括從簡單的工具到非常複雜的工具。
社群對這些工具的適當性的看法可能是不同的,而且不斷變化;人工智慧驅動的語言工具引發了重點的辯論。我們注意到,工具可能會產生有用和有幫助的結果,但也可能產生錯誤或誤導性的結果;因此,了解使用了哪些工具與評估和解釋科學作品有關。
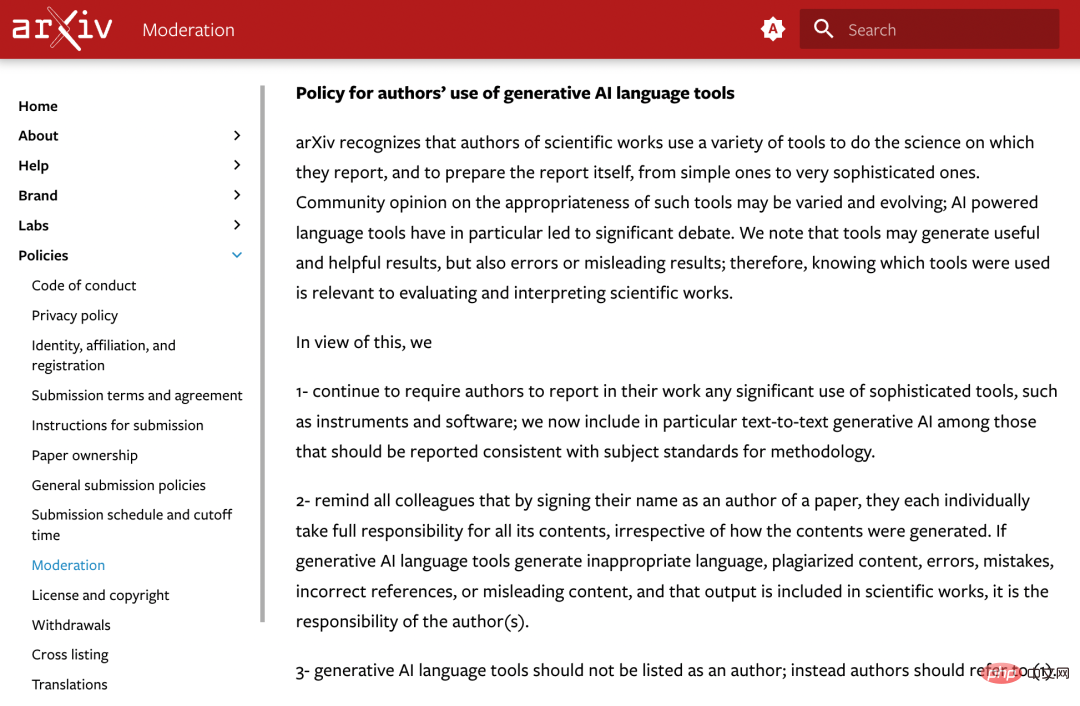
基於此,arXiv 決定:
1. 繼續要求作者在他們的工作中報告任何複雜工具的使用情況,如儀器和軟體;我們現在特別將「文本到文本的生成式人工智慧」納入應報告的符合方法論主題標準的工具中。
2. 提醒所有同事,只要在論文中籤上自己的名字,他們每個人都要對論文的所有內容承擔全部責任,無論這些內容是如何產生的。如果生成式人工智慧語言工具產生了不恰當的語言、抄襲的內容、錯誤的內容、不正確的參考文獻或誤導性的內容,並且該輸出被納入科學成果中,這就是作者的責任。
3. 生成式人工智慧語言工具不應該被列為作者,可參考 1。
幾天前,《自然》雜誌就公開表示,已經與所有Springer Nature 期刊共同製定了兩條原則,並且這些原則已被添加到現有的作者指南中:
首先,任何大型語言模型工具都不會被接受為研究論文的署名作者。這是因為任何作者的歸屬權都伴隨著對工作的責任,而 AI 工具不能承擔這種責任。
第二,使用大型語言模型工具的研究人員應該在方法或致謝部分記錄這種使用。如果論文不包括這些部分,可以用引言或其他適當的部分來記錄對大型語言模型的使用。
這些規定和 arXiv 最新發布的原則十分相似,看起來,學術出版領域的組織們似乎達成了某種共識。
ChatGPT 的能力縱然強大,但其在學校作業、論文發表等領域的濫用引發了人們廣泛的擔憂。
機器學習會議ICML 就表示過:「ChatGPT 接受公共資料的訓練,這些資料通常是在未經同意的情況下收集的,這會帶來一系列的責任歸屬問題。”
因此,學界開始探索偵測 ChatGPT 等大型語言模型(LLM)產生文字的方法和工具。未來,偵測內容是否由 AI 產生或許將成為「審稿中的重要一環」。
以上是根據arXiv的正式規定,使用ChatGPT等工具作為作者是不被允許的的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















