

近日,自然語言處理領域頂級會議 EMNLP 2022 在阿聯酋首都阿布達比舉行。

今年的大會共有投稿4190 篇,最終829 篇論文被接收(715 篇長論文,114 篇論文),整體接收率為20%,與往年差異不大。
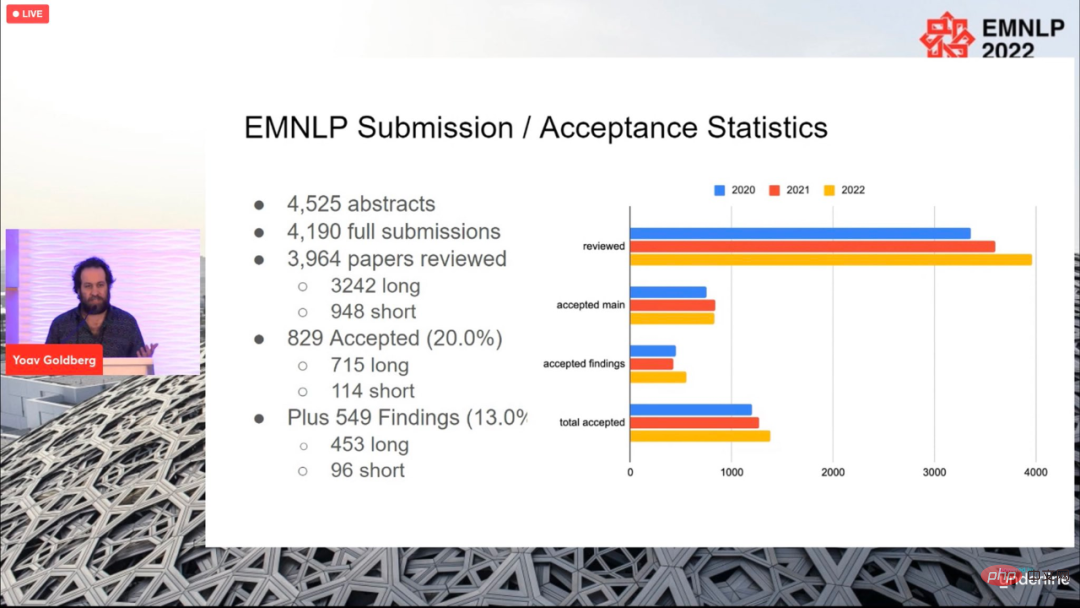
大會於當地時間12 月11 日落幕,同時也公佈了本屆論文獎項,包括最佳長論文(1 篇)、最佳短論文(1 篇)、最佳Demo 論文(1 篇)。

#論文:Abstract Visual Reasoning with Tangram Shapes
#論文摘要:#在這篇論文中,研究者介紹了「KiloGram」,一個用於研究人類和機器的抽象視覺推理的資源庫。 KiloGram 在兩個方面大大改進了現有資源。首先,研究者策劃並數位化了 1016 個形狀,創造了一個比現有工作中使用的集合大兩個數量級的集合。這個集合大大增加了對整個命名變化範圍的覆蓋,提供了一個關於人類命名行為的更全面的視角。第二,該集合不是把每個七巧板當作一個單一的整體形狀,而是當成由原始的拼圖碎片構成的向量圖形。這種分解能夠對整個形狀和它們的部分進行推理。研究者利用這個新的數位化七巧板圖形集合來收集大量的文本描述數據,反映了命名行為的高度多樣性。
研究者利用眾包來擴展註釋過程,為每個形狀收集多個註釋,從而代表它所引起的註釋的分佈,而不是單一的樣本。最終總共收集了 13404 個註釋,每個註釋都描述了一個完整的物件及其分割的部分。
KiloGram 的潛力是廣泛的。研究者用該資源評估了最近的多模態模型的抽象視覺推理能力,並觀察到預訓練的權重表現出有限的抽象推理能力,而這一能力隨著微調的進行而得到極大的改善。他們也觀察到,明確的描述部分有助於人類和模型的抽象推理,特別是在對語言和視覺輸入進行聯合編碼時。
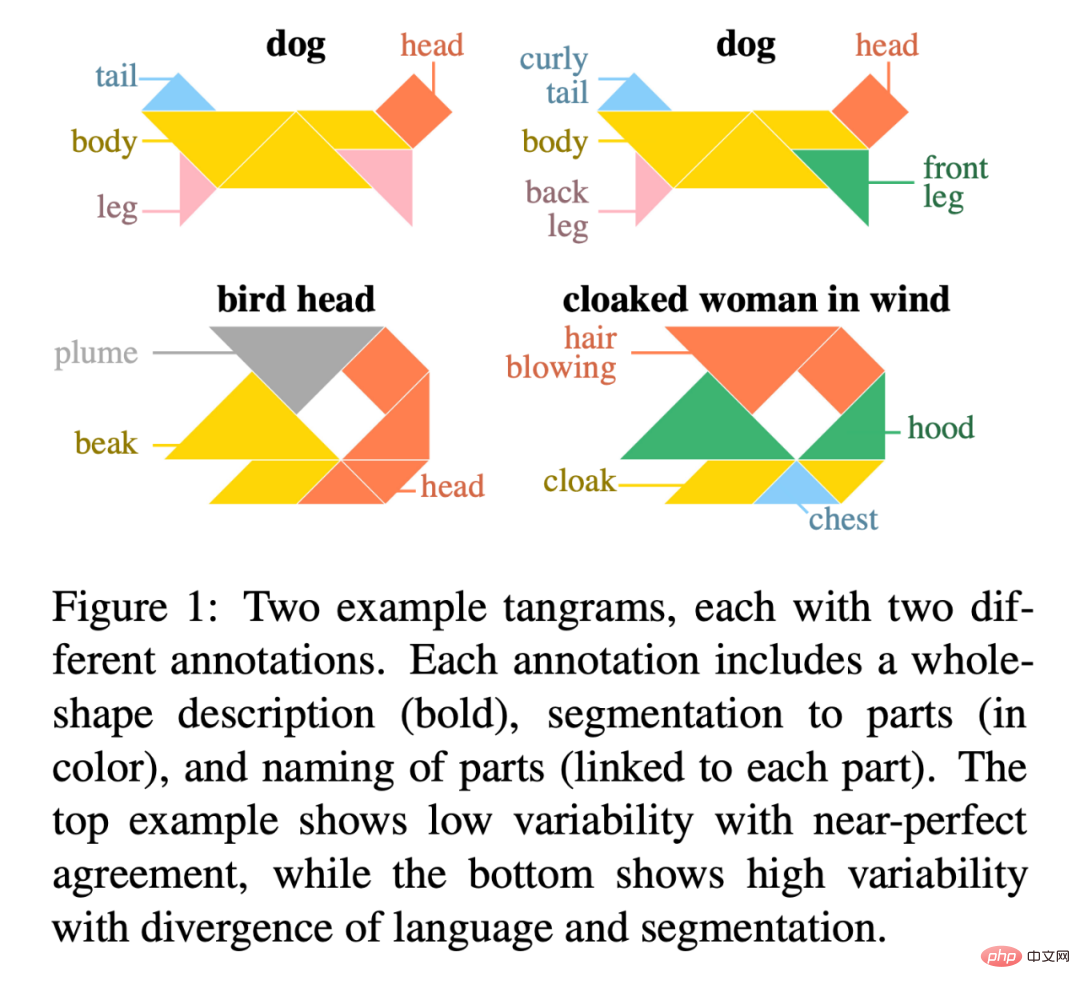
圖 1 是兩個七巧板的例子,每個七巧板都有兩個不同的註解。每個註釋都包括整個形狀的描述(黑體),對部分的分割(彩色),以及各部分的命名(與每個部分相連)。上面的例子顯示了接近完美一致的低可變性,而下面的例子顯示了語言和分割的分歧的高可變性。
##KiloGram 位址:https://lil.nlp .cornell.edu/kilogram
本次大會的最佳長論文提名由Kayo Yin 和Graham Neubig 兩位研究者獲得。
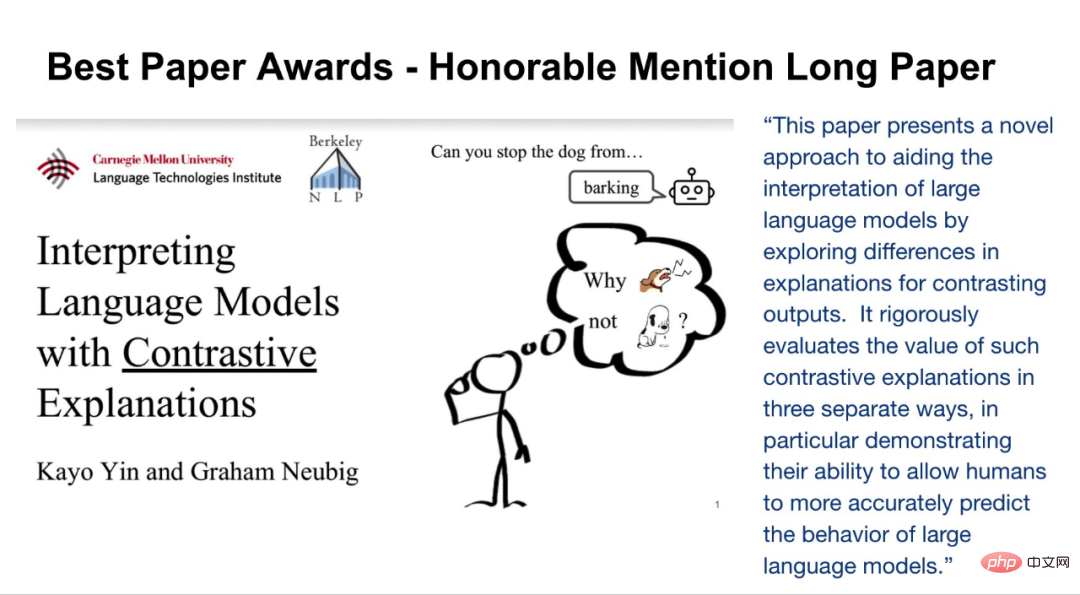
論文:Interpreting Language Models with Contrastive Explanations
#論文摘要:模型的可解釋性方法經常被用來解釋NLP 模型在文字分類等任務上的決策,這些任務的輸出空間相對較小。然而,當應用於語言生成時,輸出空間往往由數以萬計的 token 組成,這些方法無法提供翔實的解釋。語言模型必須考慮各種特徵來預測一個 token,例如它的詞性、數字、時態或語義。由於現有的解釋方法將所有這些特徵的證據合併成一個單一的解釋,這對於人類的理解來說可解釋性較差。
為了區分語言建模中的不同決策,研究者探討了專注於對比性解釋的語言模型。他們尋找到突出的輸入 token,解釋為什麼模型預測了一個 token 而不是另一個 token。研究證明了在驗證主要的語法現象方面,對比性解釋比非對比性解釋要好得多,而且它們大大改善了人類觀察者的對比性模型可模擬性。研究者也確定了模型使用類似證據的對比性決策組,並且能夠描述模型在各種語言生成決策中使用哪些輸入 token。
程式碼位址:https://github.com/kayoyin/interpret-lm

論文:Topic-Regularized Authorship Representation Learning
#論文摘要:在這項研究中,研究者提出了Authorship Representation Regularization,一個可以提高交叉主題表現的蒸餾框架,也可以處理未見過的author。這種方法可以應用於任何 authorship 表徵模型。實驗結果顯示,在交叉主題設定中,4/6 的表現得到了提升。同時,研究者分析表明,在具有大量主題的資料集中,跨主題設定的訓練分片存在主題資訊外洩問題,從而削弱了其評估跨主題屬性的能力。

#論文:Evaluate & Evaluation on the Hub: Better Best Practices for Data and Model Measurements
論文摘要:評估是機器學習(ML) 的關鍵部分,該研究在Hub 上引入了Evaluate 和Evaluation——一組有助於評估ML 中的模型和資料集的工具。 Evaluate 是一個函式庫,用於比較不同的模型和資料集,支援各種指標。 Evaluate 庫旨在支援評估的可複現性、記錄評估過程,並擴大評估範圍以涵蓋模型性能的更多方面。它包括針對各種領域和場景的 50 多個高效規範實現、互動式文檔,並可輕鬆共享實現和評估結果。
計畫網址:https://github.com/huggingface/evaluate
此外,研究者也推出了Evaluation on the Hub,該平台可以在Hugging Face Hub 上免費對超過75000 個模型和11000 個資料集進行大規模評估,只需單擊一個按鈕即可。
以上是EMNLP 2022大會正式落幕最佳長論文最佳短文等獎項公佈的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















