

Transformer 作為 NLP 預訓練模型架構,能夠有效的在大型未標記的資料上進行學習,研究已經證明,Transformer 是自 BERT 以來 NLP 任務的核心架構。
最近的工作表明,狀態空間模型(SSM)是長範圍序列建模有利的競爭架構。 SSM 在語音生成和 Long Range Arena 基準上取得了 SOTA 成果,甚至優於 Transformer 架構。除了提高準確率之外,基於 SSM 的 routing 層也不會隨著序列長度的增長而呈現二次複雜性。
本文中,來自康乃爾大學、 DeepMind 等機構的研究者提出了雙向門控SSM (BiGS),用於無需注意力的預訓練,其主要是將SSM routing 與基於乘法門控(multiplicative gating)的架構結合。研究發現 SSM 本身在 NLP 的預訓練中表現不佳,但整合到乘法門控架構後,下游準確率便會提高。
實驗表明,在受控設定下對相同資料進行訓練,BiGS 能夠與 BERT 模型的效能相符。透過在更長的實例上進行額外預訓練,在將輸入序列擴展到 4096 時,模型還能保持線性時間。分析表明,乘法門控是必要的,它修復了 SSM 模型在變長文字輸入上的一些特定問題。

論文網址:https://arxiv.org/pdf/2212.10544.pdf
SSM 透過以下微分方程式將連續輸入u (t) 與輸出y (t) 連結起來:
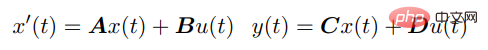
對於離散序列,SSM 參數被離散化,其過程可以近似為:
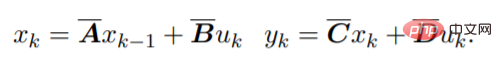
這個方程可以解釋為一個線性RNN,其中x_k 是一個隱藏狀態。 y 也可以用卷積計算:
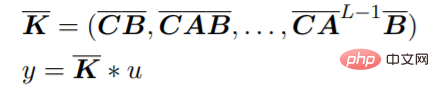
#Gu 等人展示了一種在神經網路中使用SSM 的有效方法,他們開發了參數化A 的方法,稱為HiPPO,其產生了一個穩定而有效率的架構,稱為S4。這保留了 SSM 對長期序列建模的能力,同時比 RNN 訓練更有效。最近,研究人員提出了 S4 的簡化對角化版本,它透過對原始參數更簡單的近似實現了類似的結果。在高層次上,基於 SSM 的 routing 為神經網路中的序列建模提供了一種替代方法,而無需二次計算的注意力成本。
預訓練模型架構
#SSM 能取代預訓練中的注意力嗎?為了回答這個問題,研究考慮了兩種不同的架構,如圖 1 所示的堆疊架構(STACK)和乘法門控架構(GATED)。
具有自註意力的堆疊架構相當於 BERT /transformer 模型,門控架構是門控單元的雙向改編,最近也被用於單向 SSM。帶有乘法門控的 2 個序列區塊(即前向和後向 SSM)夾在前饋層中。為了進行公平比較,門控架構的大小保持與堆疊架構相當。
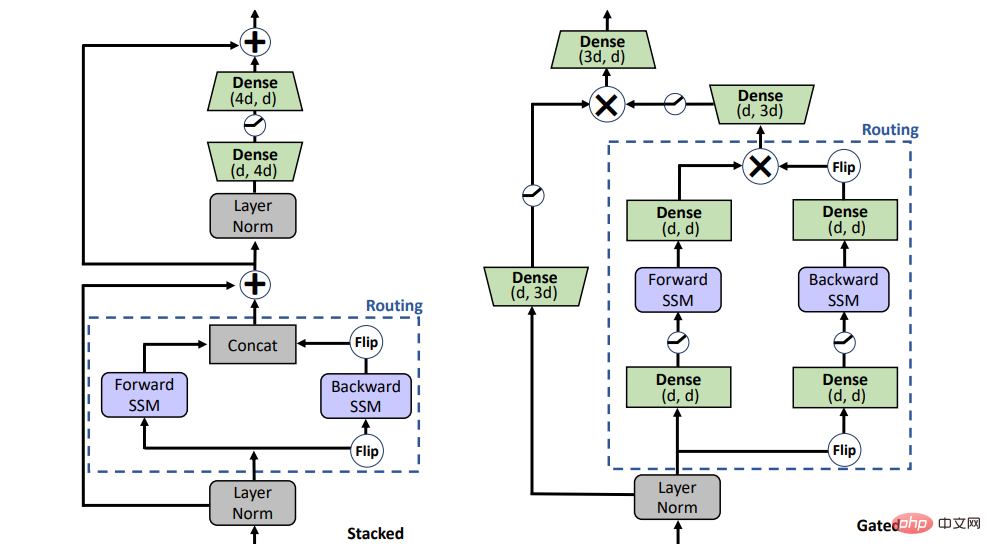
圖 1:模型變數。 STACK 是標準 transformer 架構,GATED 為基於閘控單元。對於 Routing 組件(虛線),研究同時考慮雙向 SSM(如圖所示)和標準自註意力。閘控(X)表示逐元素乘法。
預訓練
#表 1 顯示了 GLUE 基準測試中不同預訓練模型的主要結果。 BiGS 在 token 擴展上複製了 BERT 的準確率。這一結果表明,在這樣的計算預算下,SSM 可以複製預訓練 transformer 模型的準確率。這些結果明顯優於其他基於非注意力的預訓練模型。想要達到這個準確率,乘法門控是必要的。在沒有門控的情況下,堆疊 SSM 的結果明顯更差。為了檢查這種優勢是否主要來自於門控的使用,本文使用 GATE 架構訓練了一個基於注意力的模型;然而,結果顯示模型的效果實際上低於 BERT。
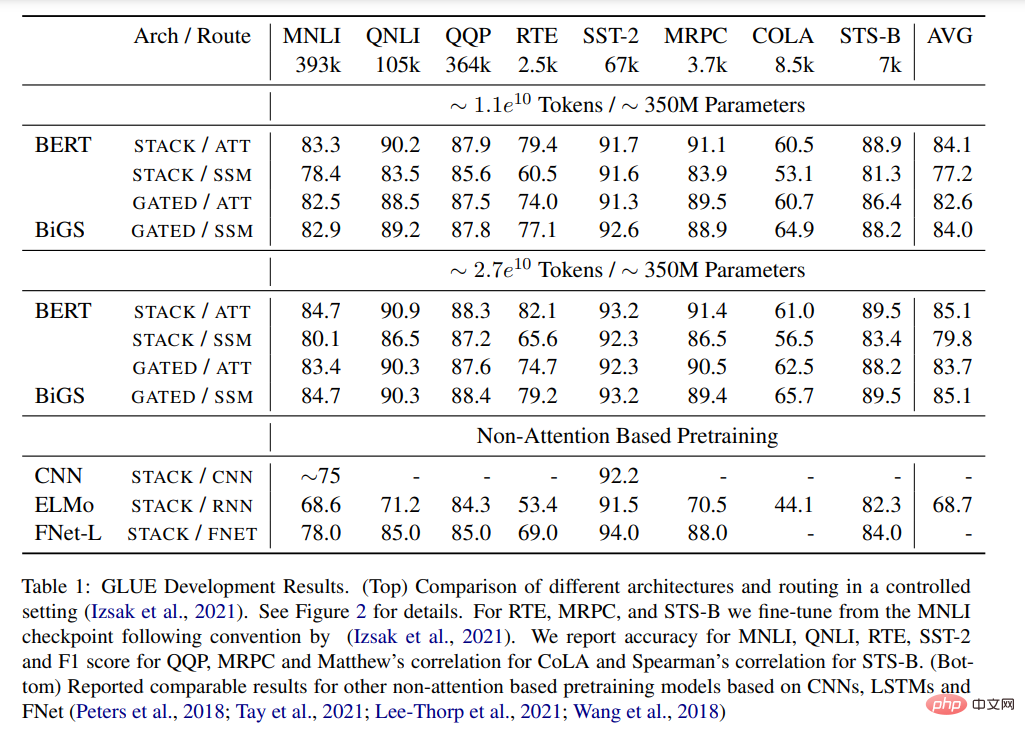
表 1:GLUE 結果。 (Top)在控制設定下,不同架構和 routing 的比較。請參閱圖 2 以了解詳細資訊。 (Bottom) 報告了基於 CNN、LSTM 和 FNet 的其他非注意力預訓練模型的可比較結果。
Long-Form 任務
#表2 結果顯示,可以將SSM 與Longformer EncoderDecoder (LED) 和BART 進行比較,但是,結果顯示它在遠端任務中表現得也不錯,甚至更勝一籌。與其他兩種方法相比,SSM 的預訓練資料少得多。即使 SSM 不需要在這些長度上進行近似,長格式也依舊很重要。
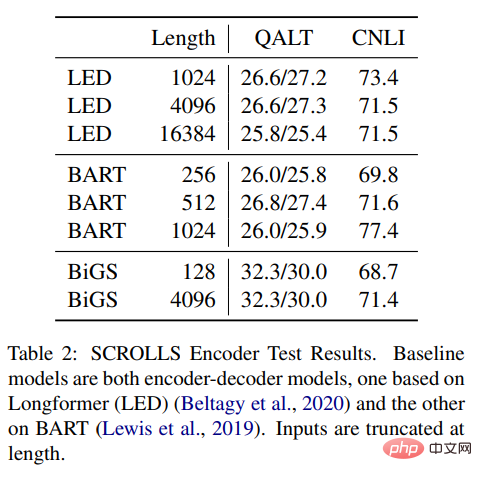
表 2:SCROLLS Encoder 測試結果。基準模型都是編碼器 —— 解碼器模型,一個基於 Longformer (LED),另一個基於 BART。輸入的長度有截斷。
更多內容請查看原始論文。
以上是預訓練無需注意力,擴展到4096個token不成問題,與BERT相當的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















