

圖優化在降低 AI 模型的訓練和推理使用的時間和資源方面起著重要作用。圖優化的一個重要功能是模型中將可以融合的算子進行融合,透過降低記憶體佔用和減少資料在低速記憶體中的搬運來提高運算效率。然而,實現一套能夠提供各種算子融合的後端方案難度很大,導致在實際硬體上 AI 模型能夠使用的算子融合非常有限。
Composable Kernel (CK)函式庫旨在提供一套在 AMD GPU 上的算子融合的後端方案。 CK 使用通用程式語言 HIP C ,完全開源。其設計理念包括:
CK 引入了兩個概念以提高後端開發者的生產力:
1. 開創性的引入「張量座標變換」(Tensor Coordinate Transformation)降低AI 算符的編寫複雜度。研究開創性地定義了一組可重複使用的Tensor Coordinate Transformation 基礎模組,並且用它們把複雜的AI 算子(例如卷積,group normalization reduction,Depth2Space,等等)以數學嚴謹的方式重新表達成了最基本的AI 算子(GEMM,2D reduction,tensor transfer,等等)。這項技術可以讓為基礎 AI 算符編寫的演算法直接被用到所有與之對應的複雜的 AI 算符上,而無需重寫演算法。
2. 基於Tile 的程式設計範式:開發算子融合的後端演算法可以被看成先將每一個融合前的算符(獨立算子)拆解成許多「小塊」 的資料操作,然後再把這些「小塊」 操作組合成融合的算子。每一個這樣的 「小塊」 操作都對應一個原始的獨立算子,但是被操作的資料只是原始張量的一部分(tile),因此這樣的 「小塊」 操作稱為 Tile Tensor Operator。 CK 函式庫包含一組針對 Tile Tensor Operator 的高度最佳化的實現,CK 裡所有的 AI 獨立算子和融合算子都是用它們實現的。目前,這些 Tile Tensor Operators 包括 Tile GEMM,Tile Reduction 和 Tile Tensor Transfer。每一個 Tile Tensor Operator 都有針對 GPU thread block,warp 和 thread 的實作。
Tensor Coordinate Transformation 和 Tile Tensor Operator 共同組成了 CK 的可重複使用的基礎模組。
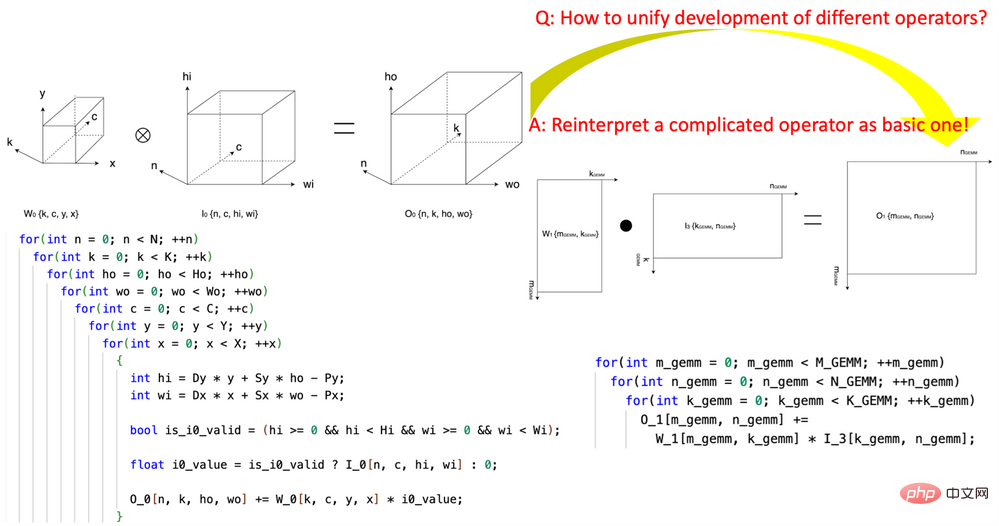
圖1,使用CK 的Tensor Coordinate Transformation 基礎模組將convolution 算符表達成GEMM 算符
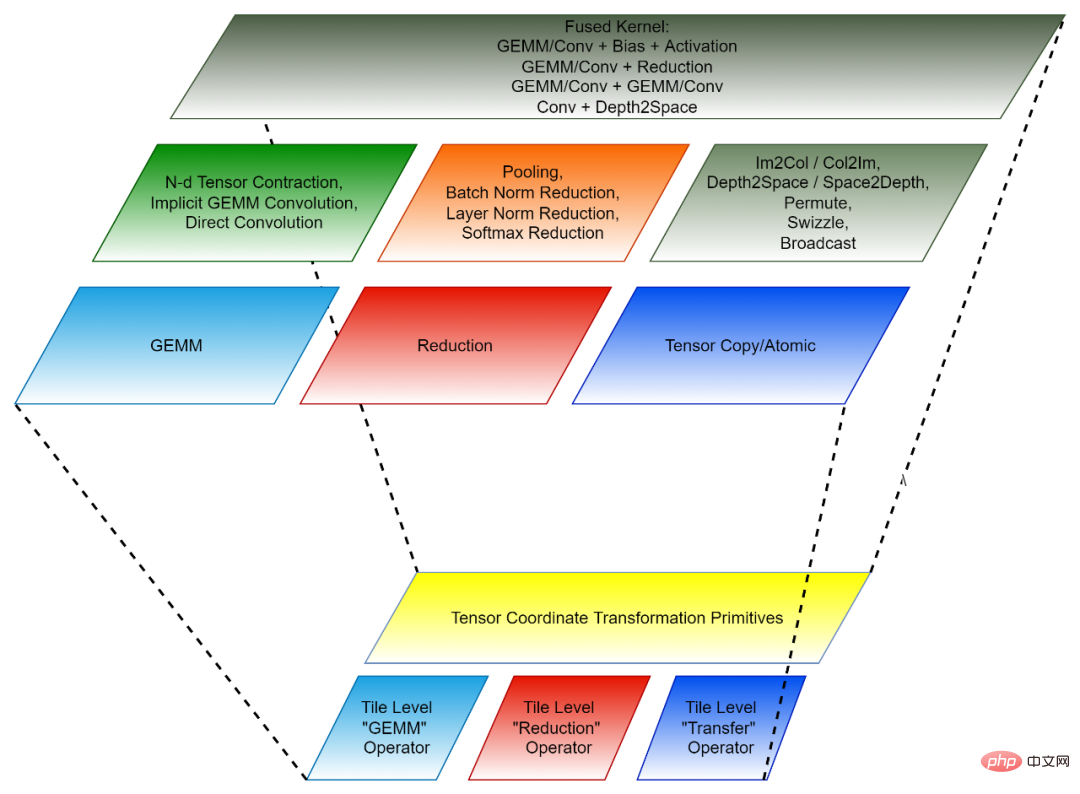
圖2,CK 的組成(下:可重複使用的基礎模組;上:獨立算子與融合算子)
CK 函式庫結構分為四層,從下到上分別是:Templated Tile Operator,Templated Kernel and Invoker, Instantiated Kernel and Invoker 與Client API【3】。每一層對應不同的開發者。
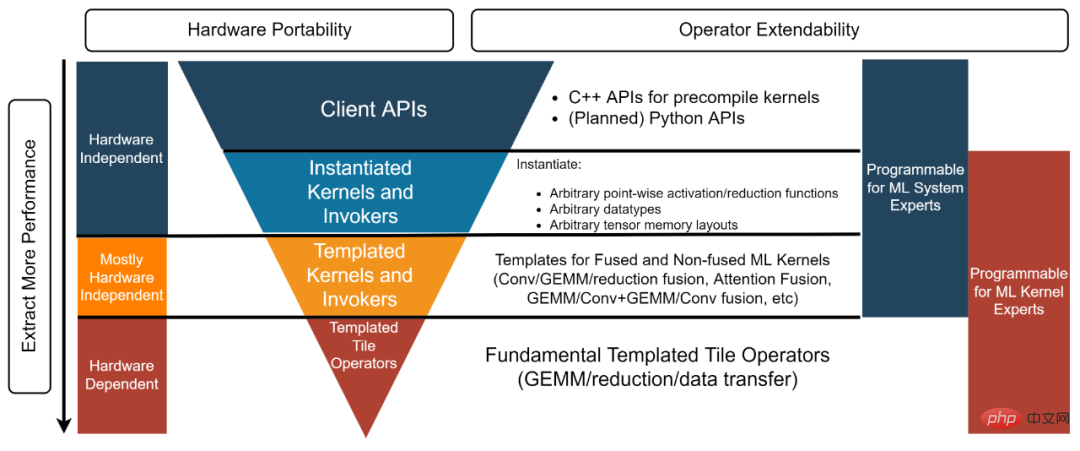
圖3,CK 函式庫四層結構
Meta 的AITemplate 【7】(AIT)是一個統一AMD 和Nvidia GPU 的AI 推理系統。 AITemplate 使用 CK 作為其 AMD GPU 上的後端,它使用的是 CK 的 Templated Kernel and Invoker 層。
AITemplate CK 在 AMD Instinct™ MI250 上取得了多個重要 AI 模型最先進的推理效能。 CK 裡大多數先進的融合算子的定義,都是在 AITemplate 團隊的遠見下推動的。許多融合算子的演算法也是由 CK 和 AITemplate 團隊共同設計。
本文比較了幾個端對端模型在 AMD Instinct MI250 和同級產品【8】的效能表現。本文中所有 AMD Instinct MI250 的 AI 模型的效能數據都是用 AITemplate【9】 CK【10】取得的。
ResNet-50
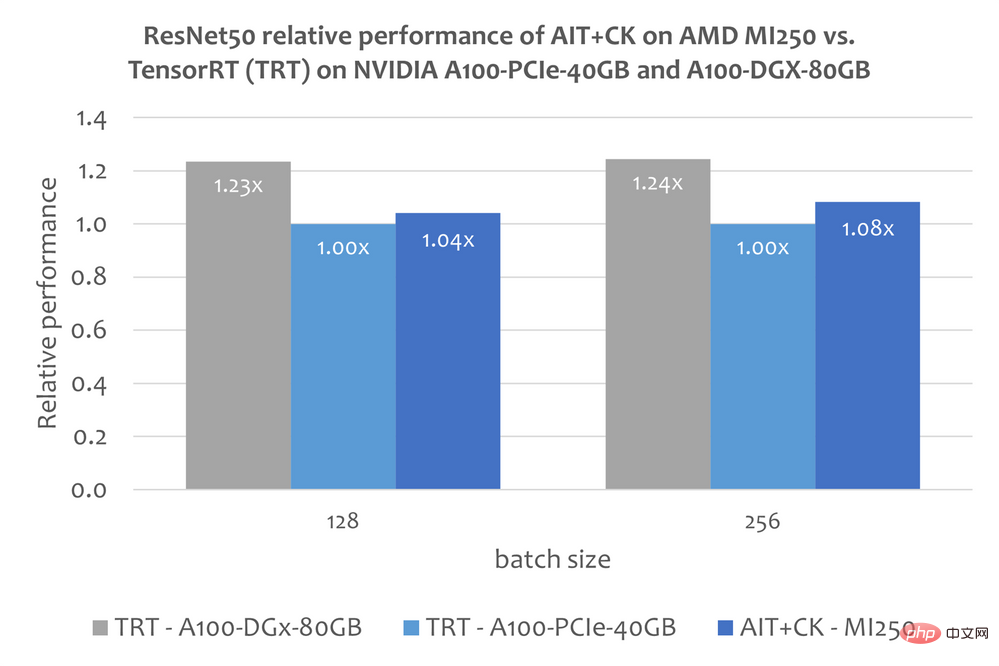
下圖顯示了AMD Instinct MI250 上的AIT CK 與A100-PCIe-40GB 和A100-DGX-80GB 上的TensorRT v8.5.0.12 【11】(TRT)的效能比較。結果顯示 AMD Instinct MI250 上的 AIT CK 取得了相比於 A100-PCIe-40GB 上的 TRT 1.08 倍的加速。
BERT
#一個基於 CK 實現的 Batched GEMM Softmax GEMM 融合算子模版,可以完全消除掉中間結果在 GPU 運算單元(Compute Unit)與 HBM 之間的搬運。透過使用這個融合算子模版,attention layer 許多原本是頻寬瓶頸(bandwidth bound)的問題變成了計算瓶頸(compute bound)的問題,這樣可以更好發揮 GPU 的運算能力。這個 CK 的實作深受 FlashAttention 【12】的啟發,並比原始的 FlashAttention 的實作減少了更多的資料搬運。
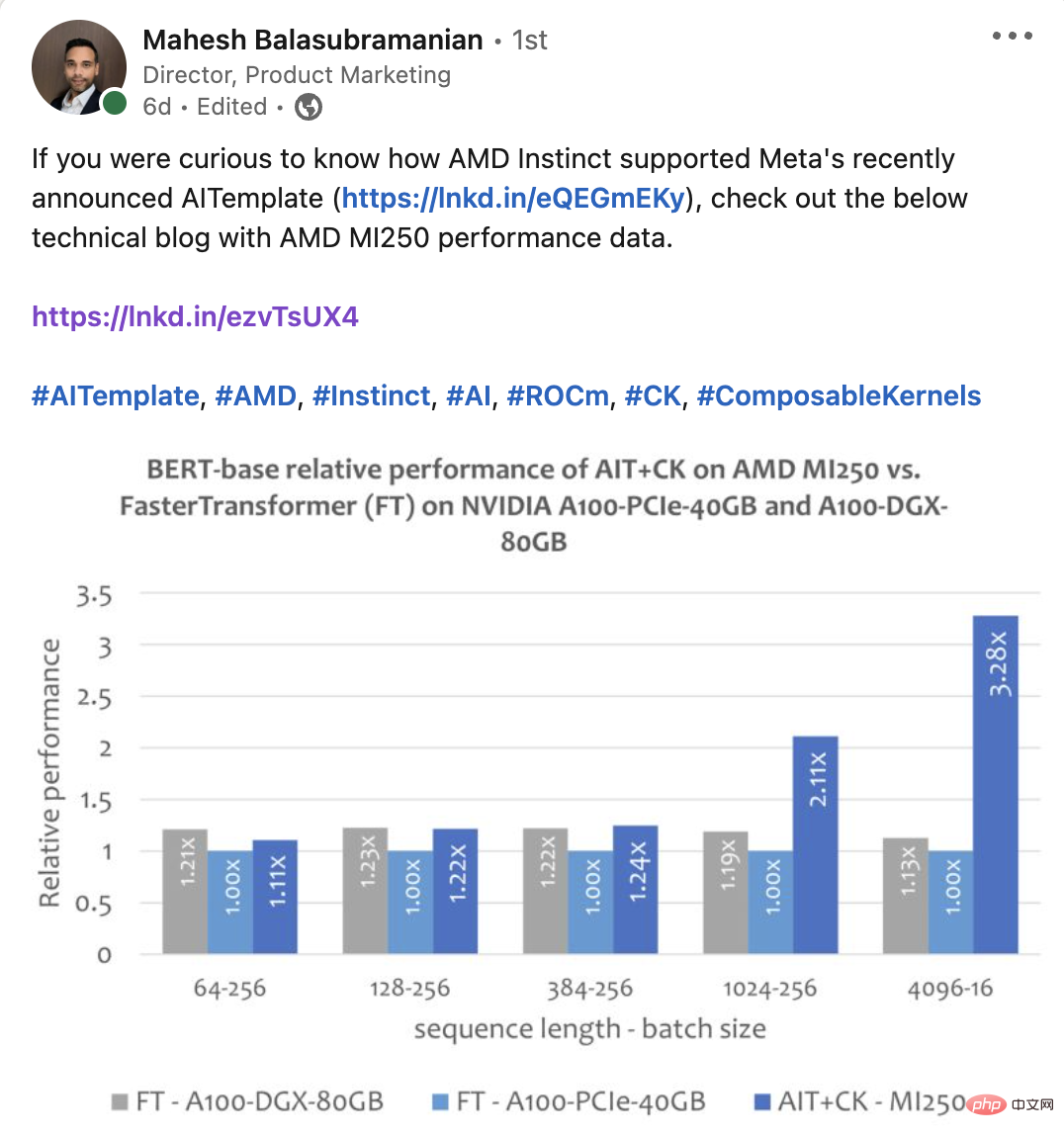
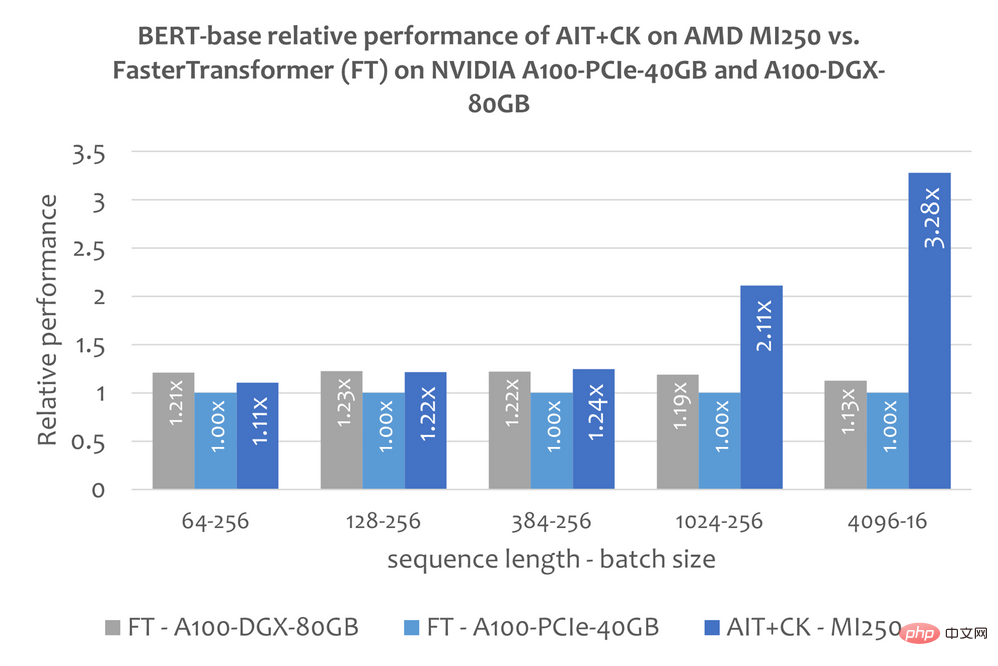
下圖顯示了AMD Instinct MI250 上的AIT CK 與A100-PCIe-40GB 和A100-DGX-80GB 上的FasterTransformer v5.1.1 bug fix 【13】(FT)的Bert Base 模型(uncased)的效能比較。當 Sequence 是 4096 時,FT 在 A100-PCIe-40GB 和 A100-DGX-80GB 上會在 Batch 32 時 GPU 記憶體溢位。因此,在 Sequence 是 4096 時,本文只顯示 Batch 16 的結果。結果顯示 AMD Instinct MI250 上的 AIT CK 取得了相比於 A100-PCIe-40GB 上的 FT 3.28 倍,以及相比於 A100-DGX-80GB 上的 FT 2.91 倍的加速。
Vision Transformer (VIT)
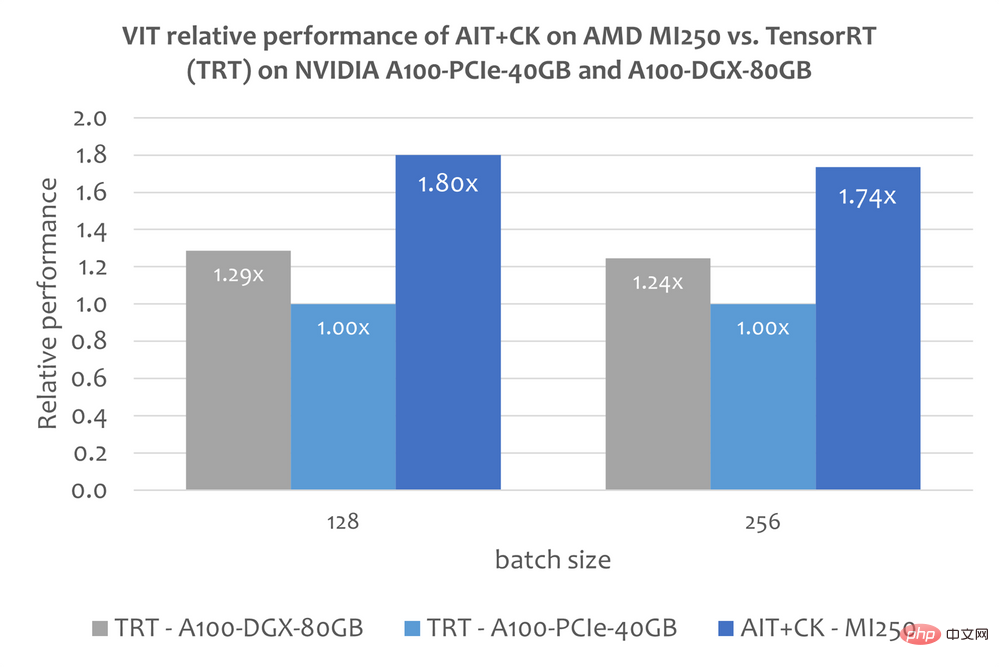
下圖顯示了AMD Instinct MI250 上的AIT CK 與A100-PCIe-40GB 和A100-DGX-80GB 上的TensorRT v8.5.0.12(TRT)的Vision Transformer Base (224x224 圖)的表現比較。結果顯示 AMD Instinct MI250 上的 AIT CK 取得了相比於 A100-PCIe-40GB 上的 TRT 1.8 倍,以及相比於 A100-DGX-80GB 上的 TRT 1.4 倍的加速。
Stable Diffusion
端對端的Stable Diffusion
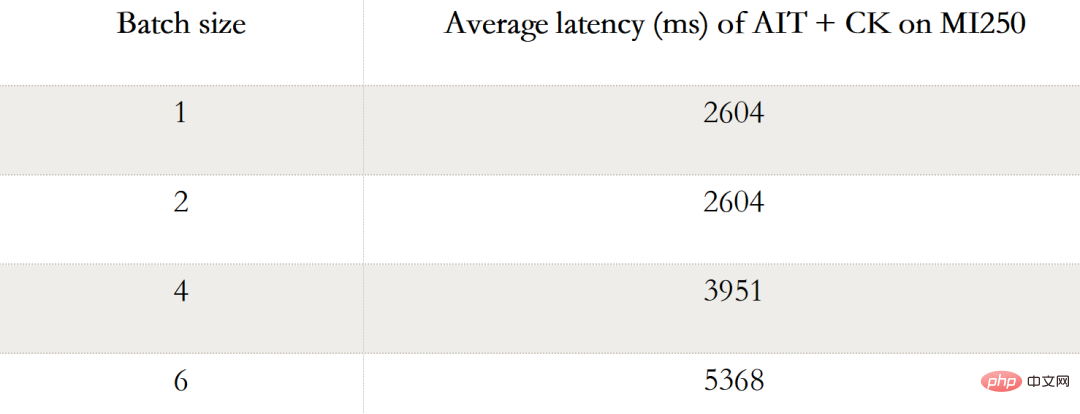
#下表顯示AIT CK 在AMD Instinct MI250 上Stable Diffusion 端對端(Batch 1,2,4, 6)的效能資料。當 Batch 是 1 時,在 MI250 上只有一個 GCD 被使用,而在 Batch 2,4,6 時,兩個 GCD 都被使用了。
Stable Diffusion 中的UNet
不過本文還沒有關於使用TensorRT 運行Stable Diffusion 端到端模型的公開的資訊。但這篇文章「Make stable diffusion 25% faster using TensorRT」 【14】說明瞭如何使用 TensorRT 加速 Stable Diffusion 中的 UNet 模型。 UNet 是 Stable Diffusion 中最重要、最花時間的部分,因此 UNet 的效能大致反應了 Stable Diffusion 的效能。
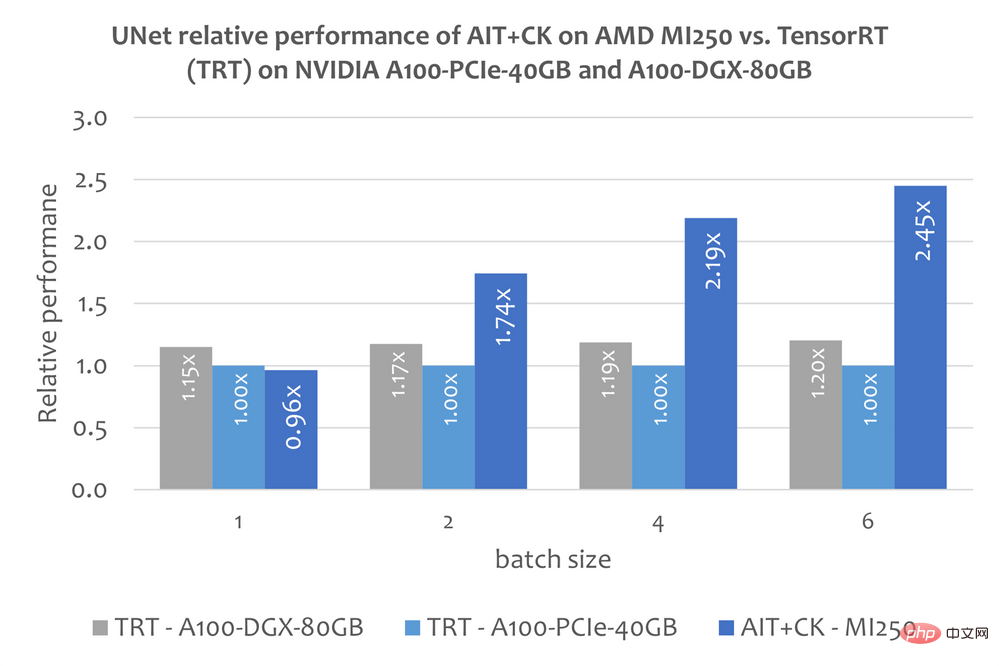
下圖顯示了AMD Instinct MI250 上的AIT CK 與A100-PCIe-40GB 和A100-DGX-80GB 上的TensorRT v8.5.0.12(TRT)的UNet 的性能比較。結果顯示 AMD Instinct MI250 上的 AIT CK 取得了相比於 A100-PCIe-40GB 上的 TRT 2.45 倍,以及相比於 A100-DGX-80GB 上的 TRT 2.03 倍的加速。
更多資訊
ROCm webpage: AMD ROCm™ Open Software Platform | AMD
ROCm Information Portal: AMD Documentation - Portal
AMD Instinct Accelerators: AMD Instinct™ Accelerators | AMD
AMD Infinity Hub: AMD Infinity Hub | AMD
#Endnotes:
#1. Chao Liu is PMTS Software Development Engineer at AMD. Jing Zhang is SMTS Software Development Engineer at AMD. Their postings are their own opinions and may not represent AMD's positions, strategies, or opinions. Links to third party s expence party svence provided for. Links to third party slylicence party s. stated, AMD is not responsible for the contents of such linked sites and no endorsement is implied. GD-5
2.CPU 的CK 處於早期開發階段。
#3. C目前API,Python API 正在規劃中。
##4.GEMM 的CK「客戶端API」範例新增新增FastGeLU融合運算符。 https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491...
5.CK“模板化內核”範例GEMM 的「Invoker」和「Invoker」新增 新增 FastGeLU 熔斷運算子。 https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8b95056672491...
##項目#6」使用的範例Tile Operator」原語用於編寫 GEMM 管道。 https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8b95056672491...
4eta#1 。 https://github.com/facebookincubator/AITemplate
##8.MI200-71:由AMD MLSE 10.23.22 使用進行的測試AITemplate https://github.com/ROCmSoftwarePlatform/AITemplate,提交f940d9b) 可組合內核https://github.com/ROCmSoftwarePlatform/composable_kernel,提交40942b9),ROCm™5.3 在2 個AMD EPYC 713在器伺服器(4 個)上運行採用AMD Infinity Fabric™ 技術的AMD Instinct MI250 OAM (128 GB HBM2e) 560W GPU 與TensorRT v8.5.0.12 和FasterTransformer(v5.1.1 錯誤修復)以及以及CUDA® 11.8 在2 個EPYC 7742 64 核心處理器伺服器上運行4x Nvidia A100-PCIe-40GB (250W) GPU 和TensorRT v8.5.0.12 和FasterTransformer(v5.1.1 錯誤修復),帶有CUDA® 11.8,在2xAMD EPYC 處理器伺服器上運行,具有8x NVIDIA A100 SXM 80GB (400W)圖形處理器。伺服器製造商可能會改變配置,從而產生不同的結果。效能可能會因使用最新驅動程式和最佳化等因素而有所不同。
9.https://github.com/ROCmSoftwarePlatform/AITemplate/tree/f940d9b7ac8b976fba127e2c269dc5b368f30e4e
10.https://github.com/ROCmSoftwarePlatform/composable_kernel/tree/40942b909801dd721769834fc61ad201b5795...
##11.TensorRT GitHub 儲存庫。 https://github.com/NVIDIA/TensorRT
##12.FlashAttention:具有IO 感知的快速、記憶體高效的精確注意力。 https://arxiv.org/abs/2205.14135
13.FasterTransformer GitHub 儲存庫。 https://github.com/NVIDIA/FasterTransformer
14.使用 TensorRT 將穩定擴散速度提高 25%。 https://www.photoroom.com/tech/stable-diffusion-25-percent-faster-and-save-seconds/
# 15 .在 AMD 期間#########
以上是透過客製化算子融合提高AI端到端效能的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















