

很喜歡有些網友的一句話:
「這孩子實在不行,咱再要一個吧。」
Google還真這麼做了。
養了七年的TensorFlow終於還是被Meta的PyTorch幹趴下了,在某種程度上。
Google眼見不對,趕緊又要了一個--「JAX”,一款全新的機器學習框架。

最近超級火辣的DALL·E Mini都知道吧,它的模型就是基於JAX進行程式設計的,從而充分地利用了GoogleTPU帶來的優勢。
2015年,Google開發的機器學習框架-TensorFlow問世。
當時,TensorFlow只是Google Brain的一個小專案。
誰也沒想到,剛一問世,TensorFlow就變得非常火爆。
優步、愛彼迎這種大公司在用,NASA這種國家機構也在用。而且還都是用在他們各自最複雜的項目上。
而截止到2020年11月,TensorFlow的下載次數已經達到了1.6億次。
不過,Google好像並沒有十分在乎這麼多使用者的感受。
奇奇怪怪的介面和頻繁的更新都讓TensorFlow對使用者越來越不友好,而且越來越難以操作。
甚至,就連Google內部,也覺得這個框架在走下坡。
其實Google如此頻繁的更新也實屬無奈,畢竟只有這樣才能追得上機器學習領域快速地迭代。
於是,越來越多的人加入了這個項目,導致整個團隊慢慢失去了重點。
而原本讓TensorFlow成為首選工具的那些閃光點,也被埋沒在了茫茫多的要素裡,不再受人重視。
這種現像被Insider形容為一種「貓鼠遊戲」。公司就像是一隻貓,不斷迭代出現的新需求就像是一隻老鼠。貓要時時保持警惕,隨時撲向老鼠。

這種困局對最先打入某一市場的公司來說是避不開的。
舉個例子,就搜尋引擎來說,Google並不是第一家。所以Google能夠從前輩(AltaVista、Yahoo等等)的失敗中總結經驗,應用在自身的發展上。
可惜到了TensorFlow這裡,Google是被困住的那一個。
正是因為上面這些原因,原先給Google賣命的開發者,慢慢對老東家失去了信心。
昔日無處不在的TensorFlow漸漸隕落,敗給了Meta的後起之秀——PyTorch。

2017年,PyTorch的測試版開源。
2018年,Facebook的人工智慧研究實驗室發布了PyTorch的完整版本。
值得一提的是,PyTorch和TensorFlow都是基於Python開發的,而Meta則更注重維護開源社區,甚至不惜大量投入資源。
而且,Meta關注到了Google的問題所在,認為不能重蹈覆轍。他們專注於一小部分功能,並把這些功能做到最好。
Meta並沒有步上谷歌的後塵。這款首先在Facebook開發出來的框架,慢慢成為了業界標竿。
一家機器學習新創公司的研究工程師表示,「我們基本上都用PyTorch。它的社群和開源做得是最出色的。不僅有問必答,給的例子也很實用。」

面對這種局面,Google的開發者、硬體專家、雲端供應商,以及任何和Google機器學習相關的人員在接受採訪時都說了一樣的話,他們認為TensorFlow失掉了開發者的心。
經歷了一系列的明爭暗鬥,Meta最終佔了上風。
有專家表示,Google未來持續引領機器學習的機會正慢慢流失。
PyTorch逐漸成為了尋常開發者和研究人員的首選工具。
從Stack Overflow提供的互動資料來看,在開發者論壇上有關PyTorch的提問越來越多,而關於TensorFlow的最近幾年一直處於停滯狀態。
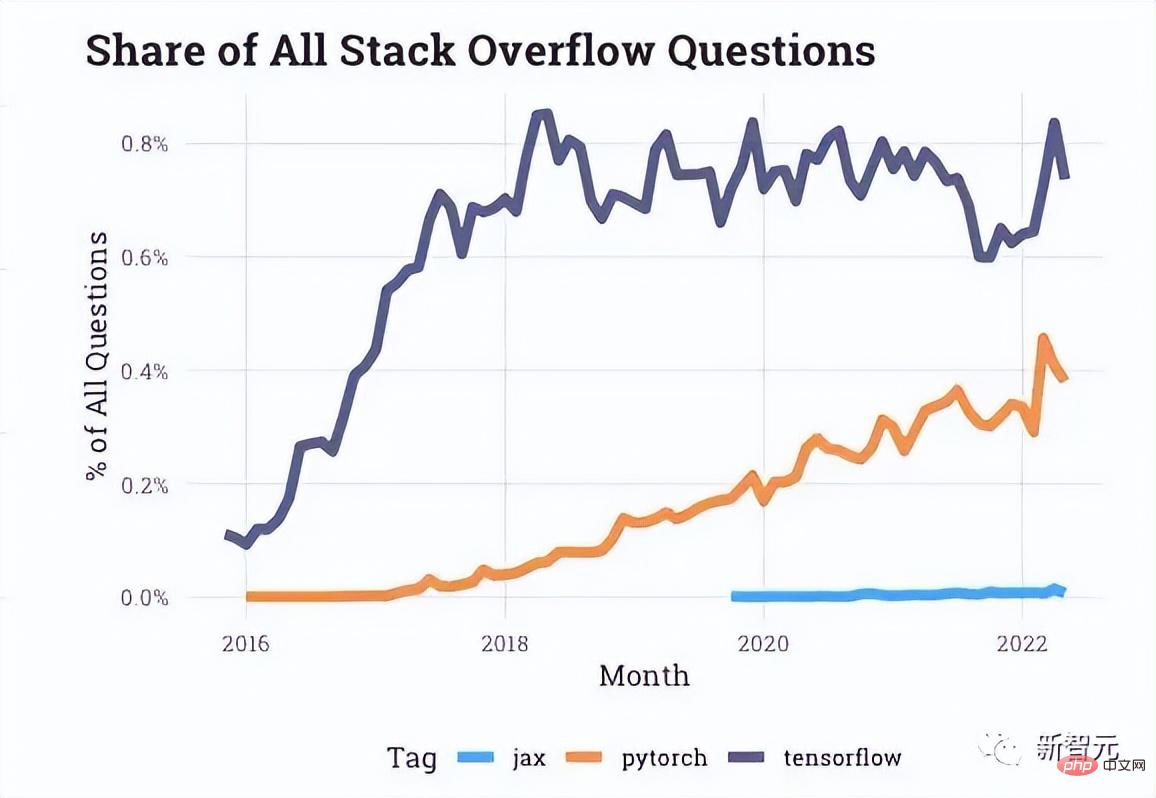
就連文章開始提到的優步等等公司也轉向PyTorch了。
甚至,PyTorch後來的每一次更新,都像是在打TensorFlow的臉。
就在TensorFlow和PyTorch打得熱火朝天的時候,Google內部的一個「小型黑馬研究團隊」開始致力於開發一個全新的框架,可以更便捷地利用TPU。

2018年,一篇題為《Compiling machine learning programs via high-level tracing》的論文,讓JAX專案浮出水面,作者是Roy Frostig、Matthew James Johnson和Chris Leary。

從左至右依序是這三位大神
#而後,PyTorch原始作者之一的Adam Paszke,也在2020年初全職加入了JAX團隊。

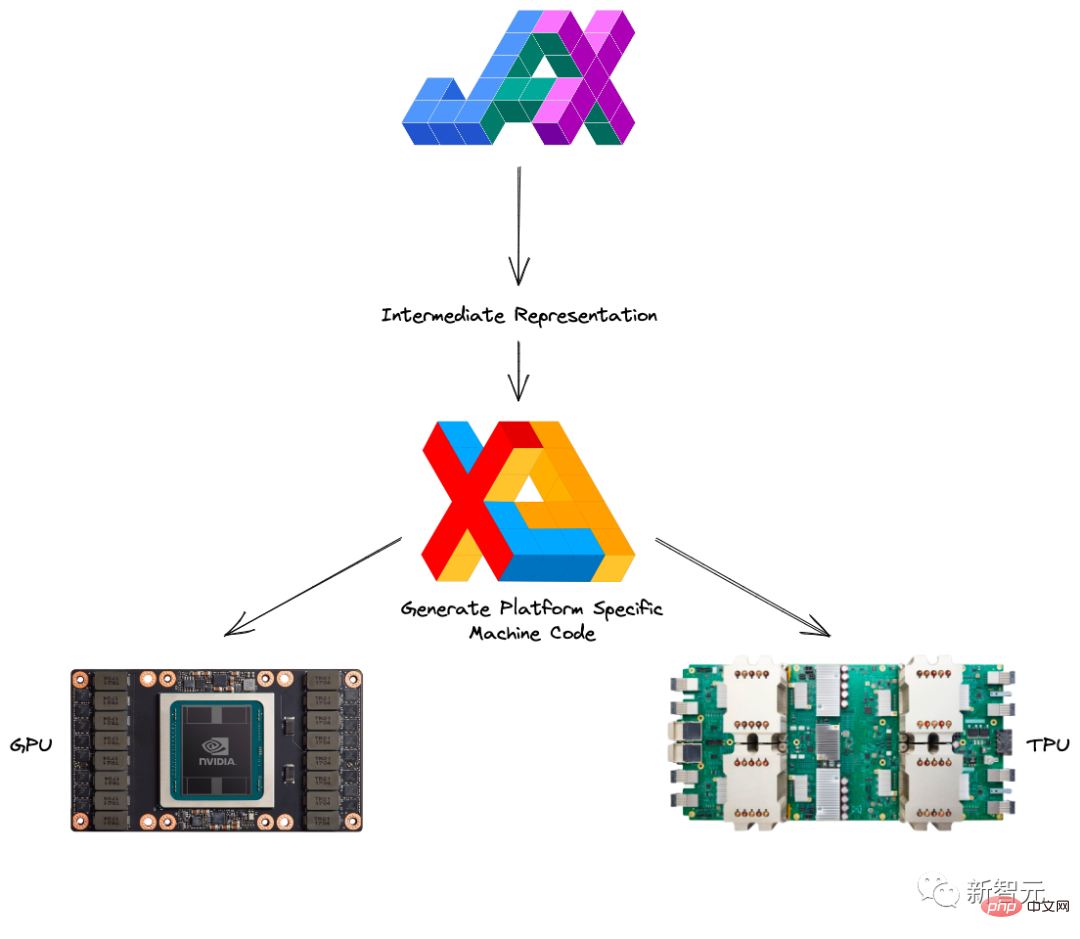
JAX提供了一個更直接的方法來處理機器學習中最複雜的問題之一:多核心處理器調度問題。
根據所應用的情況,JAX會自動地將若干個晶片組合而成一個小團體,而不是讓一個去單打獨鬥。
如此帶來的好處就是,讓盡可能多的TPU片刻間就能得到回應,從而燃燒我們的「煉丹小宇宙」。
最終,相較於臃腫的TensorFlow,JAX解決了Google內部的一個心頭大患:如何快速存取TPU。
下面簡單介紹一下構成JAX的Autograd和XLA。
Autograd主要應用於基於梯度的最佳化,可以自動區分Python和Numpy程式碼。
它既可以用來處理Python的一個子集,包括循環、遞歸和閉包,也可以對導數的導數進行求導。
此外,Autograd支援梯度的反向傳播,這也就這意味著它可以有效地獲取標量值函數相對於數組值參數的梯度,以及前向模式微分,並且兩者可以任意組合。
XLA(Accelerated Linear Algebra)可以加速TensorFlow模型而無需更改原始程式碼。
當一個程式執行時,所有的操作都由執行器單獨執行。每個操作都有一個預先編譯的GPU核心實現,執行器會分派到該核心實現。
舉個栗子:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">def</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">model_fn</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">x</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">y</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">z</span>):<br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">return</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">tf</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">reduce_sum</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">x</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">+</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">y</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">*</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">z</span>)
在沒有XLA的情況下運行,該部分會啟動三個內核:一個用於乘法,一個用於加法,一個用於減法。
而XLA可以透過將加法、乘法和減法「融合」到單一GPU核心中,從而實現最佳化。
這種融合操作不會將由記憶體產生的中間值寫入y*z記憶體x y*z;相反,它將這些中間計算的結果直接「串流」給用戶,同時將它們完全保存在GPU中。
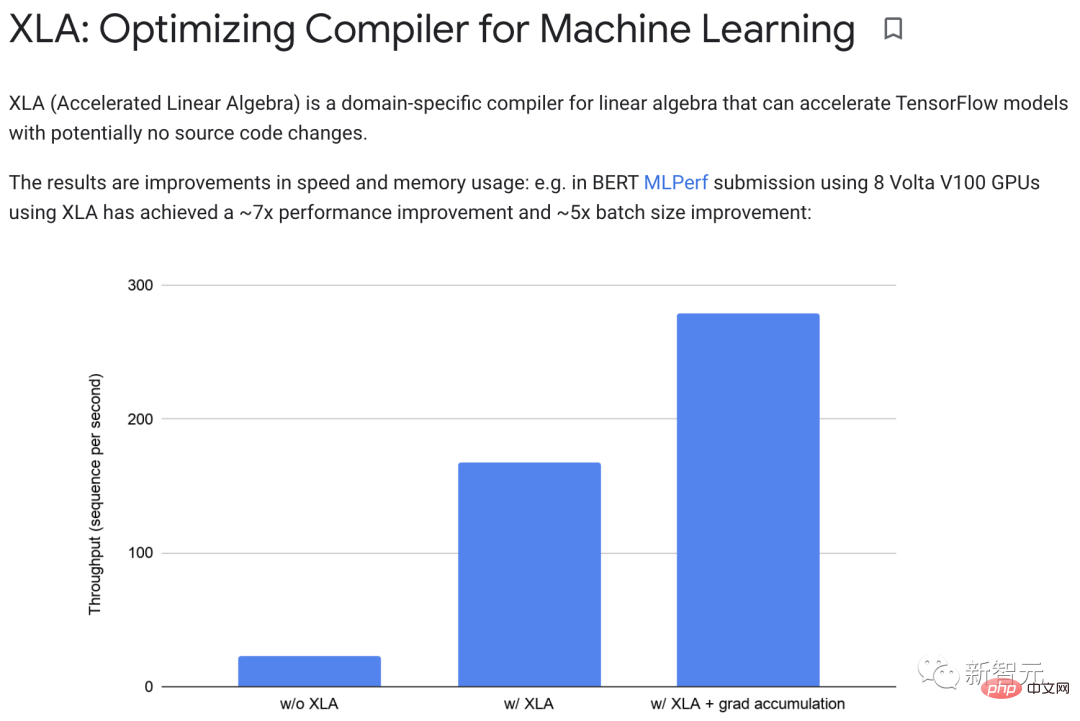
在實務上,XLA可以實現約7倍的效能改進和約5倍的batch大小改進。
此外,XLA和Autograd可以任意組合,甚至可以利用pmap方法一次使用多個GPU或TPU核心進行程式設計。
而將JAX與Autograd和Numpy結合的話,就可以獲得一個面向CPU、GPU和TPU的易於程式設計且高效能的機器學習系統了。
顯然,Google這次吸取了教訓,除了在自家全面鋪平以外,在推進開源生態的建設方面,也是格外地積極。
2020年DeepMind正式投入JAX的懷抱,而這也宣告了谷歌親自下場,自此之後各種開源的庫層出不窮。


「縱觀整場「明爭暗鬥」,賈揚清表示,在批評TensorFlow的過程中,AI系統認為Pythonic的科研就是全部需求。
但一方面純Python無法實現高效率的軟硬協同設計,另一方面上層分散式系統仍需要高效率的抽象。
而JAX正是在尋找更好的平衡,Google這種願意顛覆自己的pragmatism非常值得學習。

causact R軟體包和相關貝葉斯分析教科書的作者表示,自己很高興看到Google從TF過渡到JAX,一個更乾淨的解決方案。

作為新秀,Jax雖然可以藉鏡PyTorch和TensorFlow這兩位老前輩的優點,但有的時候後發可能也會帶來劣勢。

首先,JAX還太「年輕」,作為實驗性的框架,遠遠沒有達到一個成熟的Google產品的標準。
除了各種隱藏的bug以外,JAX在某些問題上仍然要依賴其他框架。
拿載入和預處理資料來說,就需要用TensorFlow或PyTorch來處理大部分的設定。
顯然,這和理想的「一站式」框架還相去甚遠。

其次,JAX主要針對TPU進行了高度的最佳化,但是到了GPU和CPU上,就要差很多了。
一方面,Google在2018年至2021年組織和策略的混亂,導致在對GPU進行支援上的研發的資金不足,以及對相關問題的處理優先順序靠後。
同時,大概是過於專注於讓自家的TPU能在AI加速上分得更多的蛋糕,和英偉達的合作自然十分匱乏,更不用說完善對GPU的支持這種細節問題了。
另一方面,Google自己的內部研究,不用想肯定都集中在TPU上,這就導致Google失去了對GPU使用的良好回饋迴路。
此外,更長的偵錯時間、並未與Windows相容、未追蹤副作用的風險等等,都增加了Jax的使用門檻以及友善程度。
現在,PyTorch已經快6歲了,但完全沒有TensorFlow當年顯現出的頹勢。
如此看來,想要後來者居上的話,Jax還有很長一段路要走。
以上是被PyTorch打爆! Google拋棄TensorFlow,押寶JAX的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















