

1000億個神經元,每個神經元有8000個左右的突觸,大腦的複雜結構為人工智慧研究帶來啟發。
當前,多數深度學習模型的架構,便是一種受生物大腦神經元啟發的人工神經網路。
#生成式AI大爆發,可以看到深度學習演算法在生成、總結、翻譯和分類文本的能力越來越強大。
然而,這些語言模型仍然無法與人類的語言能力相符。
恰恰預測編碼理論(Predictive coding)為此差異提供了初步的解釋:
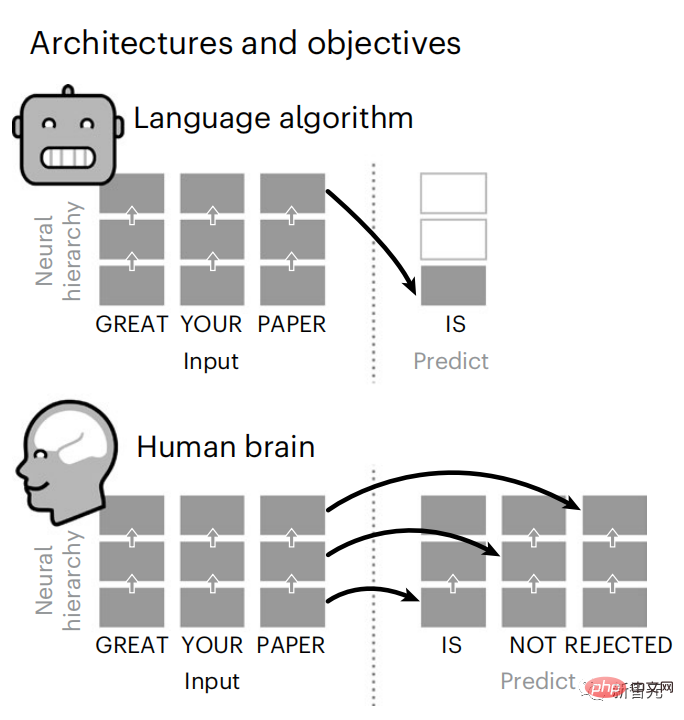
雖然語言模型可以預測附近的詞,但人腦會不斷預測跨越多個時間尺度的表徵層次。
為了驗證這個假設,Meta AI的科學家分析了304位聽完短篇故事的人的大腦功能磁振造影訊號。
結論是,分層預測編碼在語言處理中發揮至關重要的作用。
同時,研究說明了神經科學和人工智慧之間的協同作用如何能夠揭示人類認知的計算基礎。
最新研究已發表在Nature子刊Nature Human Behavior。

論文網址://m.sbmmt.com/link/7eab47bf3a57db8e440e5a788467c37f
#值得一提的是,實驗過程中用上了GPT-2,說不定未來這項研究能夠啟發到OpenAI未開源的模型。
到時候ChatGPT豈不是更強了。
大腦預測編碼分層
不到3年的時間,深度學習在文本生成、翻譯等方面取得重大進展,要歸功於一個訓練有素的演算法:根據附近語境預測單字。
值得注意的是,這些模型的活化已被證明可以線性地映射到大腦對語音和文字的反應。
此外,此映射主要取決於演算法預測未來單字的能力,因此表明這一目標足以使它們收斂到類似大腦的計算。
然而,這些演算法和大腦之間仍然存在著差距:儘管有大量的訓練數據,但目前的語言模型在長篇故事生成、總結和連貫對話以及資訊檢索方面遇到挑戰。
因演算法無法捕捉一些句法結構和語義屬性,而且對語言的理解也很膚淺。
###例如,演算法傾向於將動詞錯誤地分配給嵌套短語中的主詞。 ##################「the keys that the man holds ARE here」##################同樣,當文本當產生只針對下一個字的預測進行最佳化時,深度語言模型會產生平淡無奇、不連貫的序列,或會陷入無限重複的循環。 ##########目前,預測編碼理論為這個缺陷提供了一個潛在的解釋:
雖然深層語言模型主要是為了預測下一個詞,但這個框架表明,人腦可以在多個時間尺度和皮質層次的表徵上進行預測。
先前研究證明了大腦中的語音預測,即一個單字或音素,與功能性磁振造影( fMRI),腦電圖,腦磁圖和皮質電圖相關聯。
為預測下一個單字或音素而訓練的模型,可以將其輸出簡化為一個數字,即下一個符號的機率。
然而,預測表徵的性質和時間範圍在很大程度上是未知的。
在這項研究中,研究人員提取了304個人的fMRI訊號,讓每個人聽約26分鐘的短篇小說(Y) ,並且輸入相同內容激活語言演算法(X)。
然後,透過「大腦分數」量化X和Y之間的相似性,即最佳線性映射W後的皮爾遜相關係數(R) 。
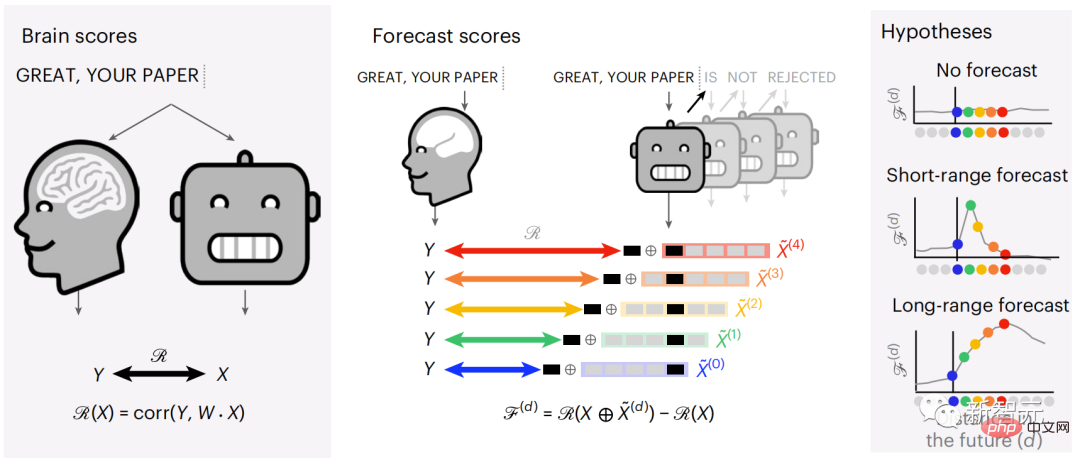
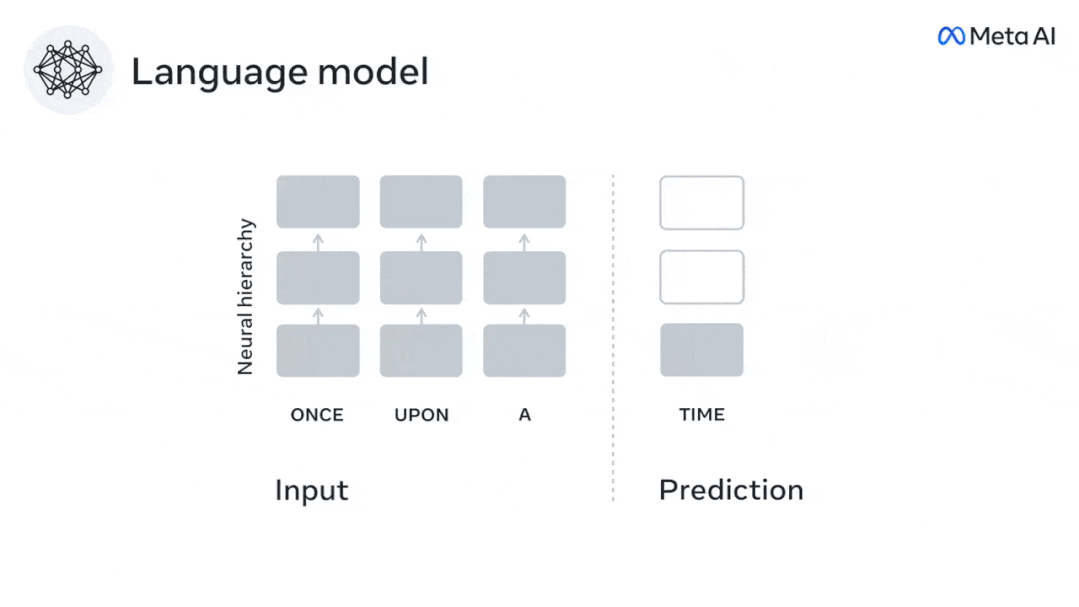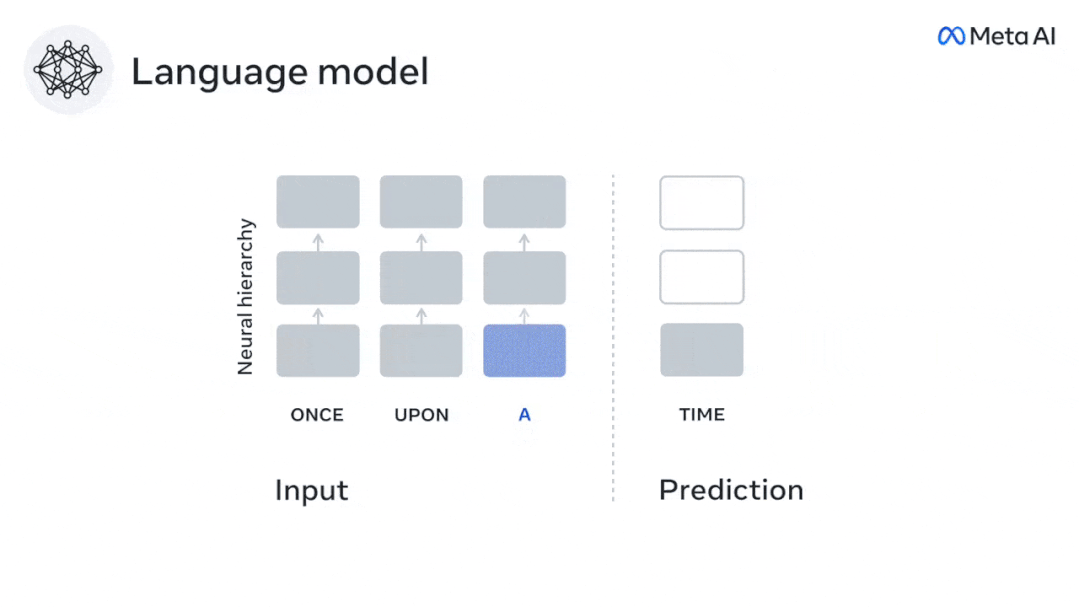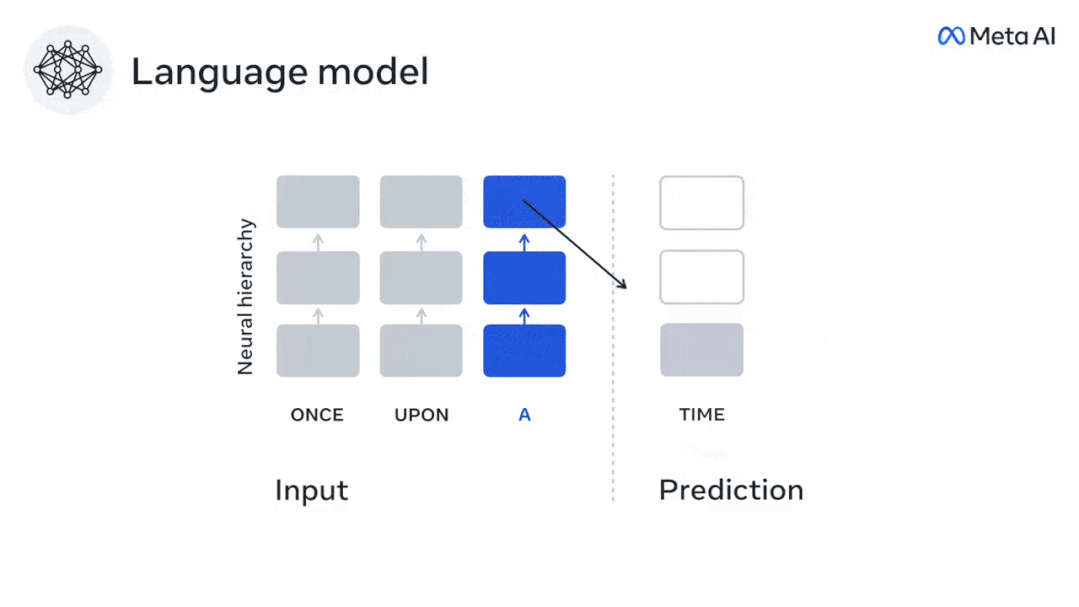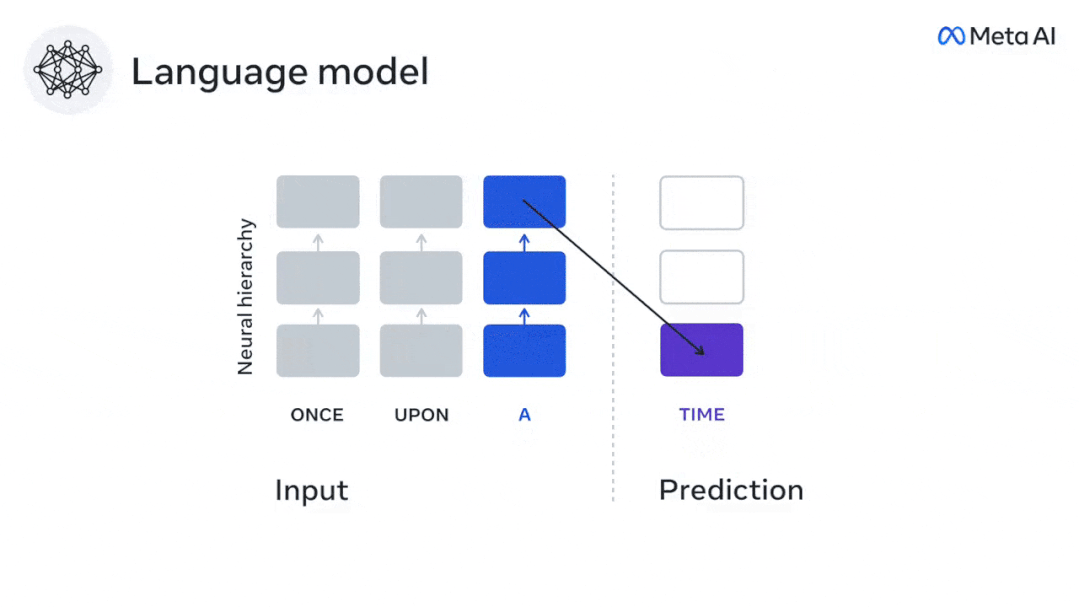
為了測試添加預測單字的表示是否改善了這種相關性,將網路的激活(黑色矩形X ) 連接到預測視窗(彩色矩形~X) ,再使用PCA將預測視窗的維度降低到X的維度。
最後F量化了透過增強語言演算法對此預測視窗的活化而獲得的大腦得分增益。我們用不同的距離視窗重複這個分析(d)。
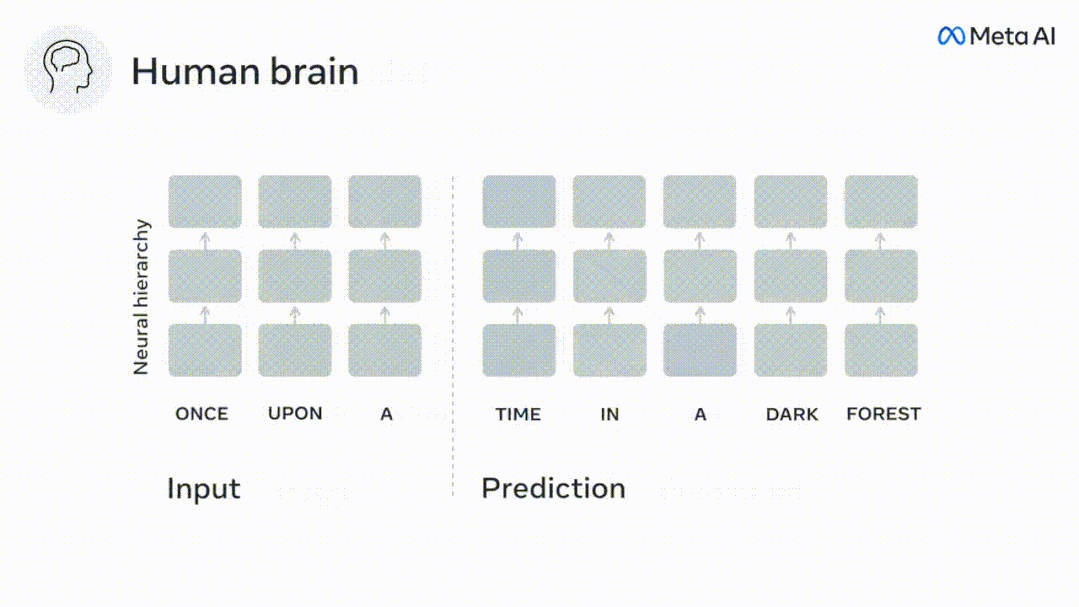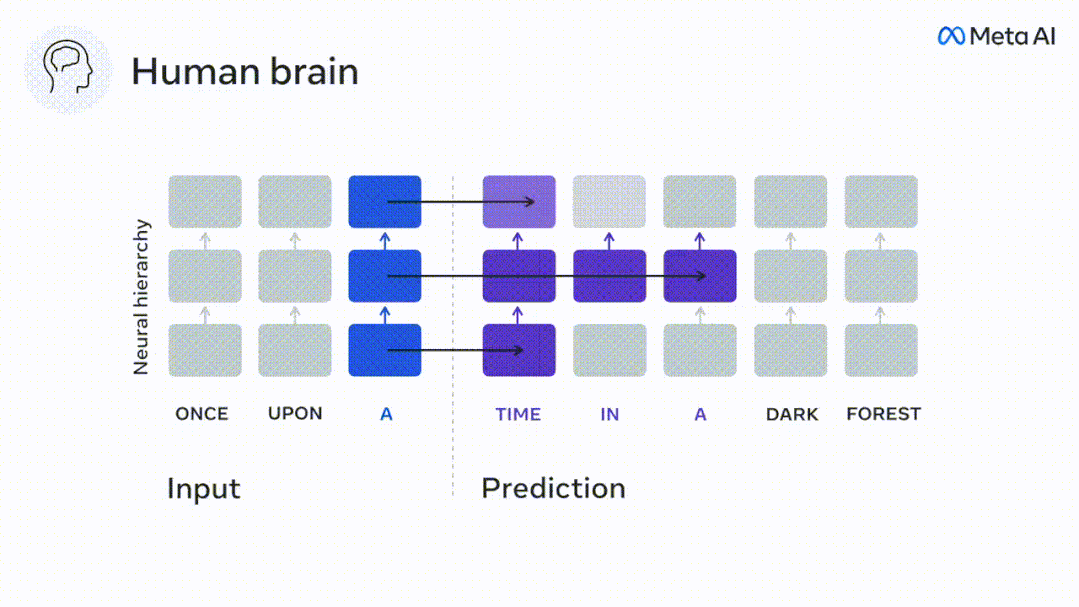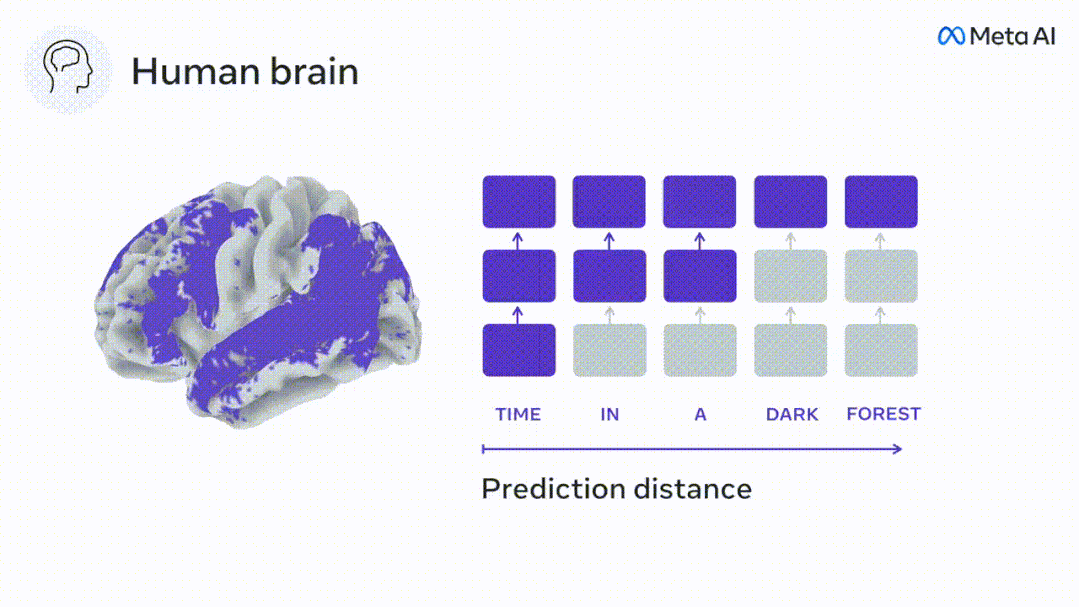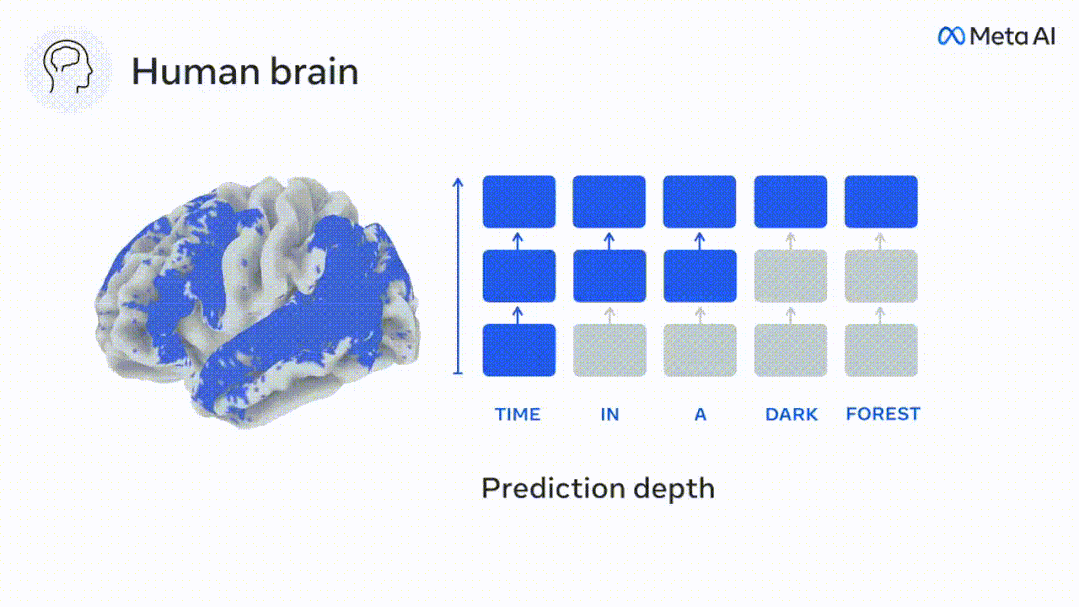
透過使用跨越多個時間尺度的預測,即遠距離預測和分層預測,來增強這些演算法,發現可以改善這種大腦映射。
最後,實驗結果發現這些預測是分層組織的:額葉皮質比顳葉皮質預測更高層次、更大範圍和更多的上下文表徵。
#深度語言模型對應到大腦活動
#科學研究人員定量了研究輸入內容相同時深度語言模型和大腦之間的相似性。
使用Narratives資料集,分析了304個聽短故事的人的fMRI(功能性磁振造影)。
對每個體素和每個實驗個體的結果進行獨立的線性嶺回歸,以預測由幾個深度語言模型激活而得到的fMRI訊號。
使用保留的數據計算了相應的「大腦分數」,即fMRI訊號和輸入指定語言模型刺激所得的嶺回歸預測結果之間的相關性。
為清晰起見,首先關注GPT-2第八層的激活,這是一個由HuggingFace2提供的12層因果深度神經網絡,最能預測大腦活動。
#與先前的研究一致,GPT-2的活化結果準確地映射到一組分佈式雙邊大腦區域,大腦分數在聽覺皮質和前顳區和上顳區達到高峰。
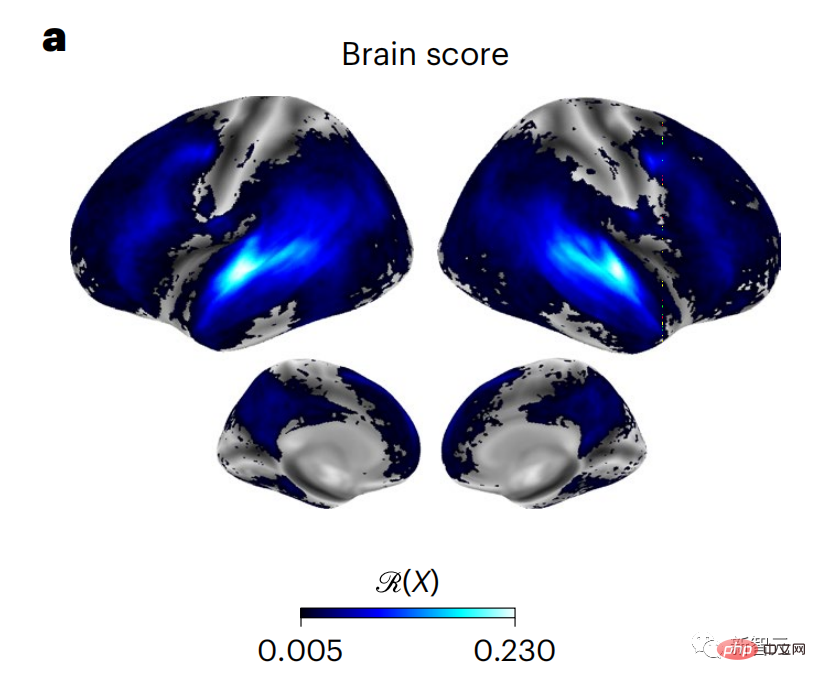
Meta團隊接著測試了增強對具有長距離預測功能的語言模型的刺激是否能使其獲得更高的大腦分數。
對於每個詞,研究人員將當前詞的模型激活和一個由未來詞組成「預測窗口」連接起來。預測視窗的表示參數包括表示當前單字和視窗中最後一個未來單字之間距離的d和所串聯詞數量的w。對於每個d,比較有和沒有預測表徵時的大腦分數,計算“預測分數”。
結果顯示,d=8時預測分數最高,峰值出現在與語言處理有關的大腦區域。
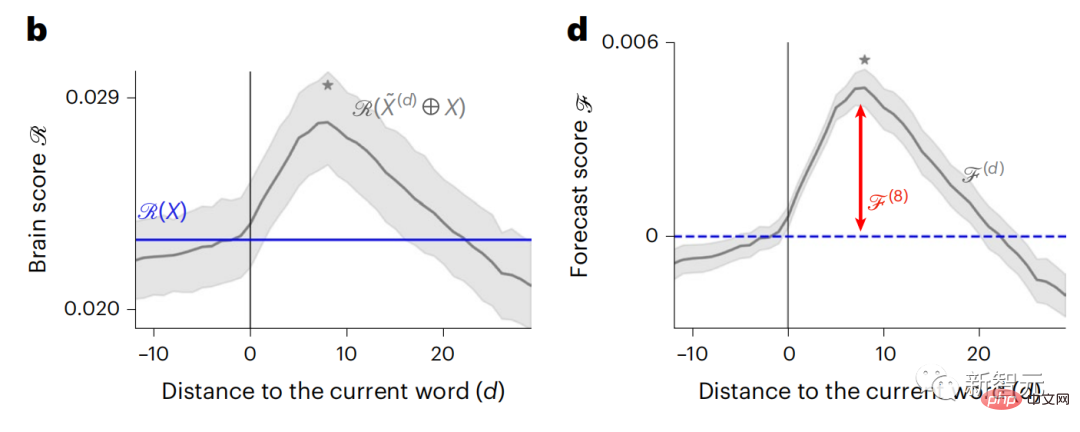
d=8對應於3.15秒的音頻,即兩個連續的fMRI掃描的時間。預測分數在大腦中呈雙邊分佈,除了額葉下部和邊緣上回。
透過補充分析,團隊也得到以下結果:(1)與當前字詞距離0到10的每個未來字詞都對預測結果有明顯貢獻;(2)預測表徵最好用8個左右的詞的窗口大小來捕捉;(3)隨機預測表徵不能提高大腦得分;(4)比起真正的未來詞,GPT-2生成的詞能夠取得類似的結果,但得分較低。
預測的時間範圍沿著大腦的層次變化
解剖學和功能學研究都表明,大腦皮質分層次的。不同層次的皮層,預測的時間窗口是否相同呢?
研究人員估計了每個體素預測分數的峰值,將其對應的距離表示為d。
結果顯示,前額葉區的預測峰值出現時對應的d平均而言大於顳葉區(圖2e),顳下回的d要大於顳上溝。
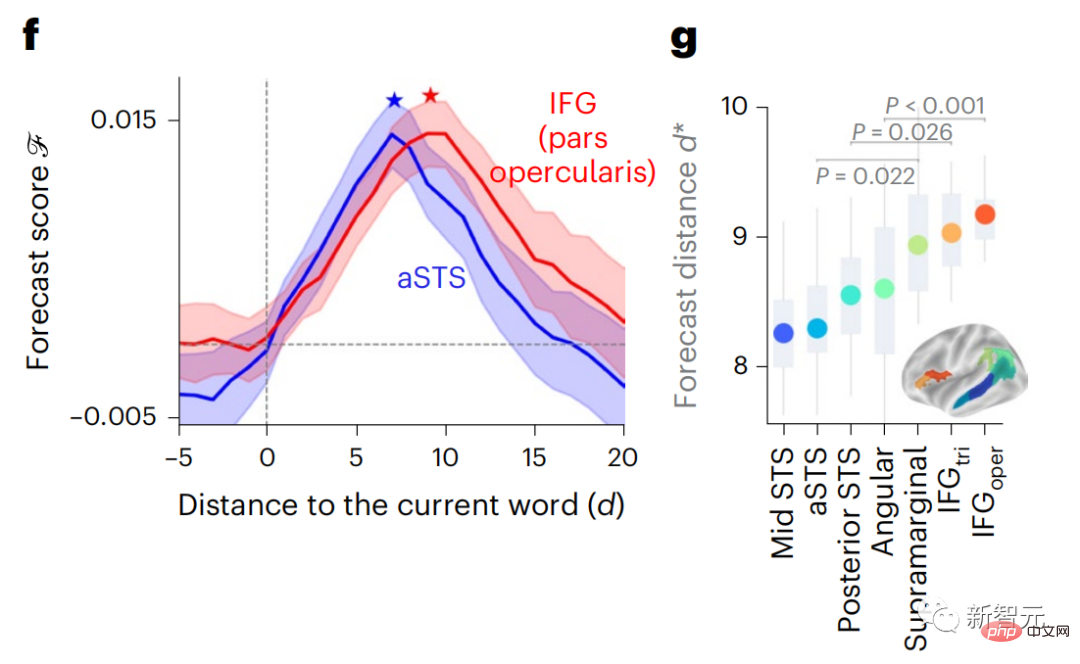
最佳預測距離沿著顳頂-額軸的變化在大腦兩個半球上基本上是對稱的。
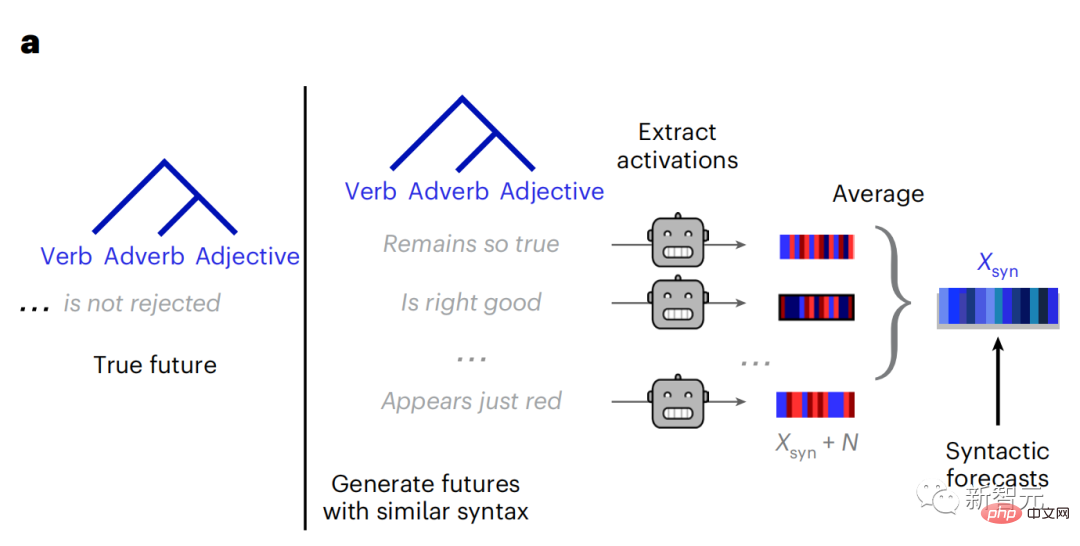
#對於每個字及其前文語境,產生十個可能的未來詞,這與真正未來詞的句法相匹配。對於每個可能的未來詞,提取相應的GPT-2激活並取其平均值。這種方法能夠將給定語言模型活化分解為句法成分和語義成分,從而計算其各自的預測分數。
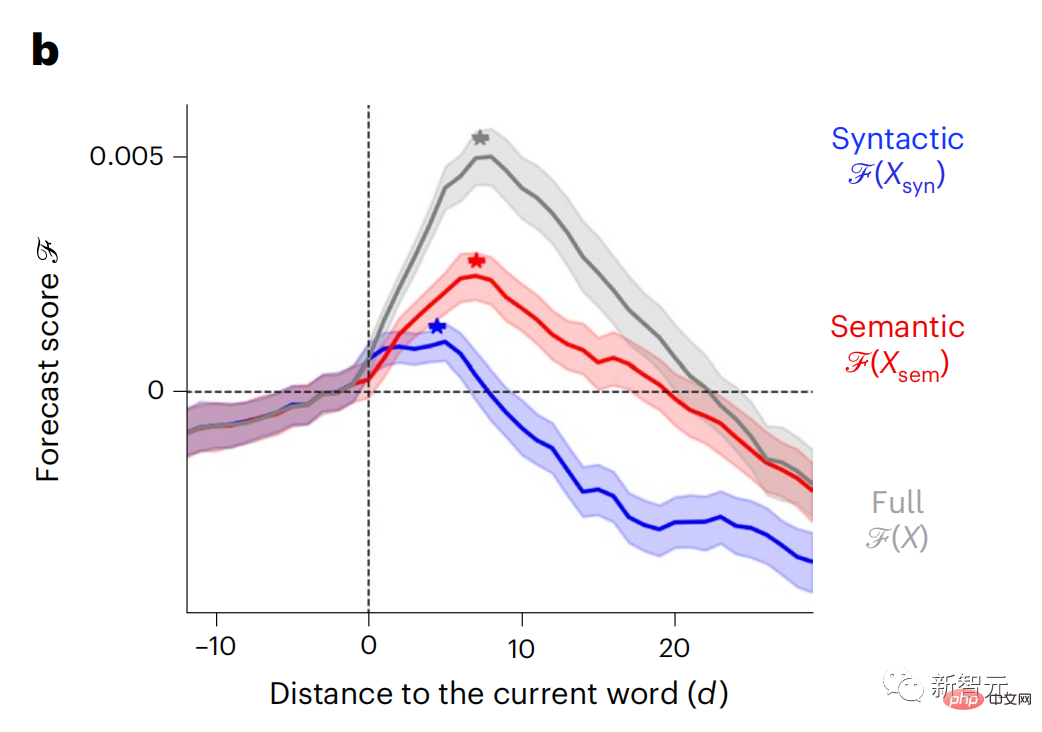
結果顯示,語意預測是長距離的(d = 8),涉及一個分散式網絡,在額葉和頂葉達到峰值,而句法預測的範圍較短(d = 5),集中在上顳區和左額區。
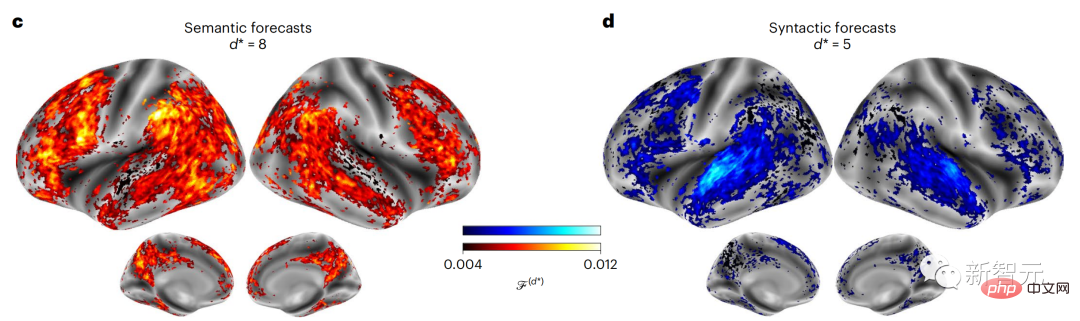
這些結果揭示了大腦中多層次的預測,其中上顳皮質主要預測短期、淺層和句法表徵,而下額葉和頂葉區域主要預測長期、上下文、高層和語義表徵。
預測的背景沿著大腦層次變得更複雜
仍按照之前的方法計算預測分數,但改變了GPT-2的使用層,為每個體素確定k,即預測分數最大化的深度。
我們的結果表明,最佳預測深度沿著預期的皮質層次而變化,聯想皮質比低階語言區有更深的預測的最佳模型。區域之間的差異雖然平均很小,但在不同的個體中是非常明顯的。
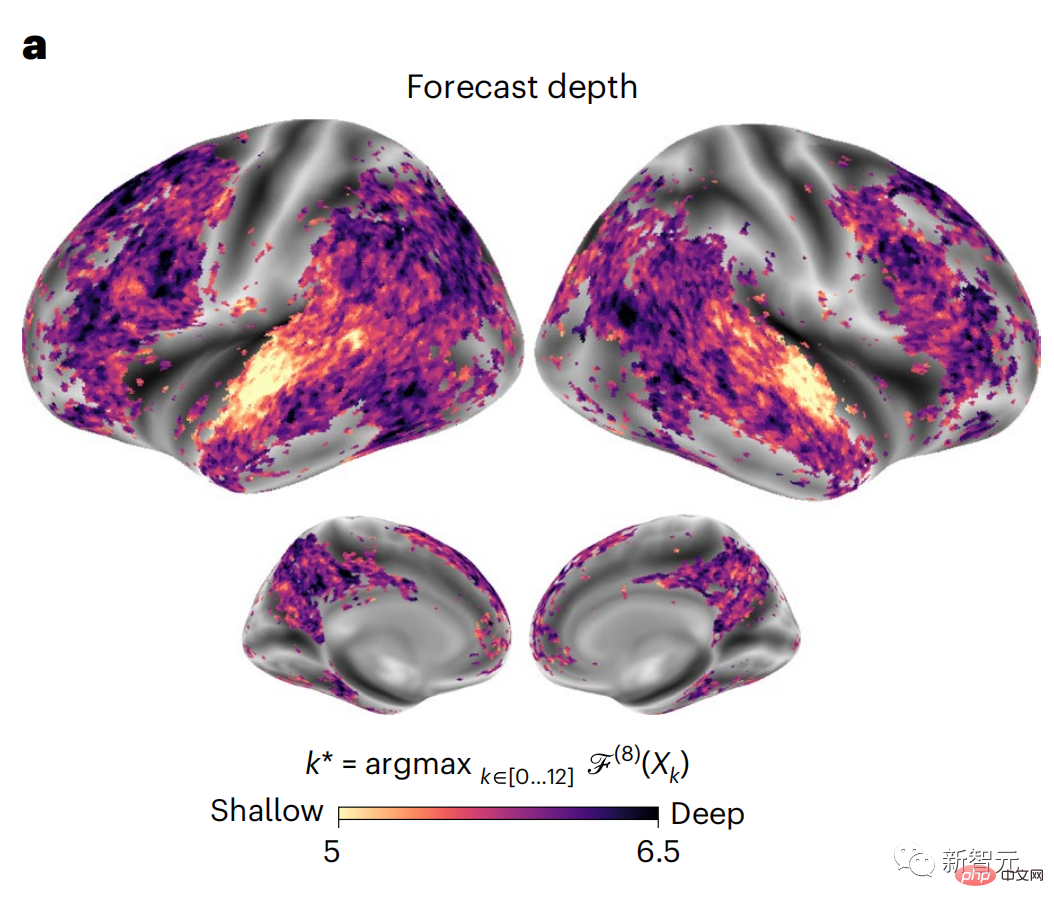
總的來說,額葉皮質的長程預測比低水平腦區的短期預測背景更複雜,水平更高。
將GPT-2調整為預測編碼結構
#將GPT-2的當前詞和未來詞的表徵串聯起來可以得到更好的大腦活動模型,特別是在額葉區。
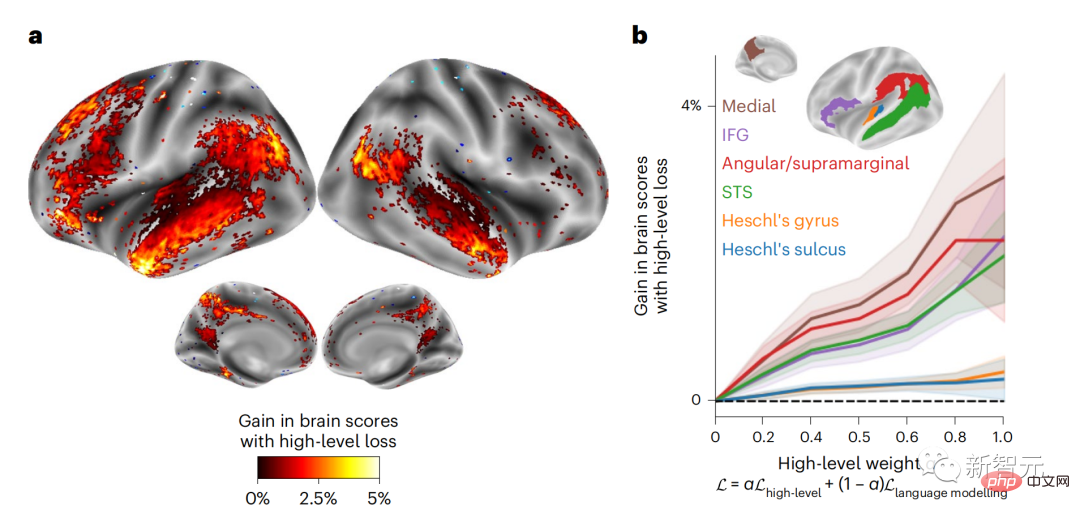
對GPT-2進行微調以預測距離更遠、背景更豐富、層次更高的表徵,能否改善這些區域的大腦映射呢?
在調整中,不僅使用了語言建模,還使用了高層次和長距離的目標,這裡的高層次目標是預先訓練的GPT -2模型的第8層。
結果顯示,以高層次和遠距離建模對進行GPT-2微調最能改善額葉的反應,而聽覺區和較低層次的腦區並沒有從這種高層次的目標中明顯受益,進一步反映了額葉區在預測語言的長程、語境和高層次表徵方面的作用。
參考資料:https:/ /m.sbmmt.com/link/7eab47bf3a57db8e440e5a788467c37f
以上是大腦分層預測讓大模型更卷!的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















