

在過去的兩年時間裡,AI界的大型生成模型發布呈現井噴之勢,尤其是Stable Diffusion開源和ChatGPT開放介面後,更加激發了業界對生成式模型的熱情。
但生成式模型種類繁多,發布速度也非常快,稍不留神就有可能錯過了sota
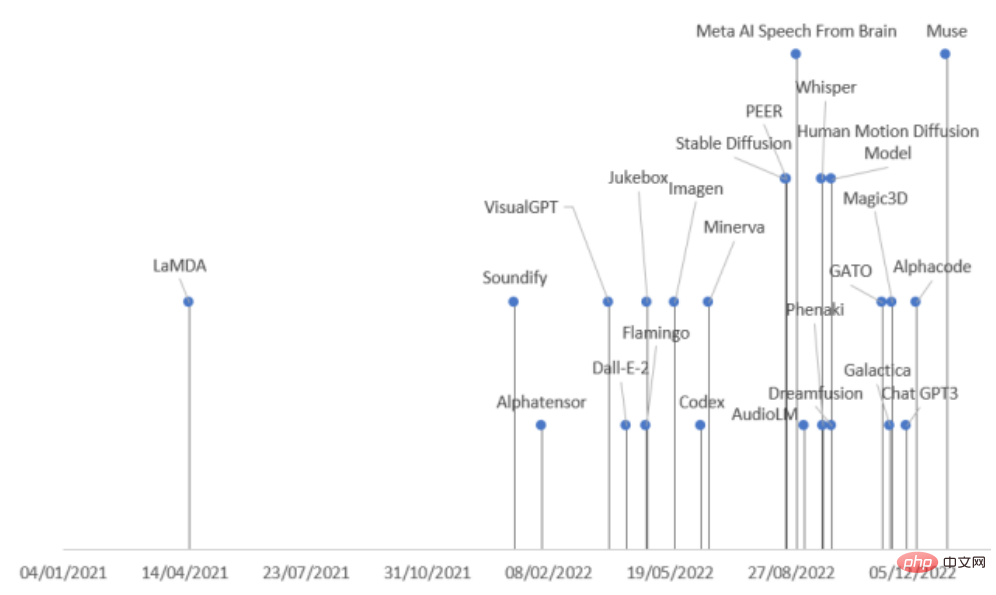
最近,來自西班牙科米利亞斯主教大學的研究人員全面回顧了各領域內AI的最新進展,將生成式模型按照任務模態、領域分為了九大類,並總結了2022年發布的21個生成式模型,一次看明白生成式模型的發展脈絡!

論文連結:https://arxiv.org/abs/2301.04655
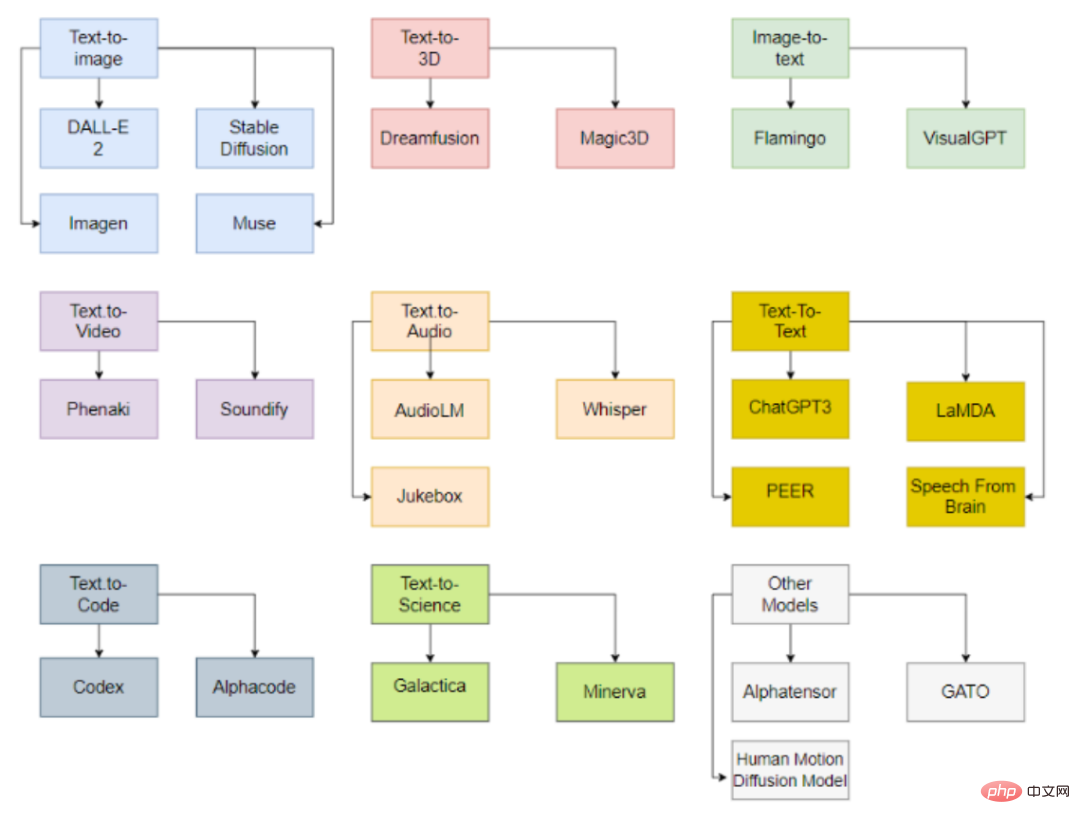
模型可以依照輸入和輸出的資料型態進行分類,目前主要包括9類。
有趣的是,在這些已發布大模型的背後,只有六個組織(OpenAI, Google, DeepMind, Meta, runway, Nvidia)參與部署了這些最先進的模型。
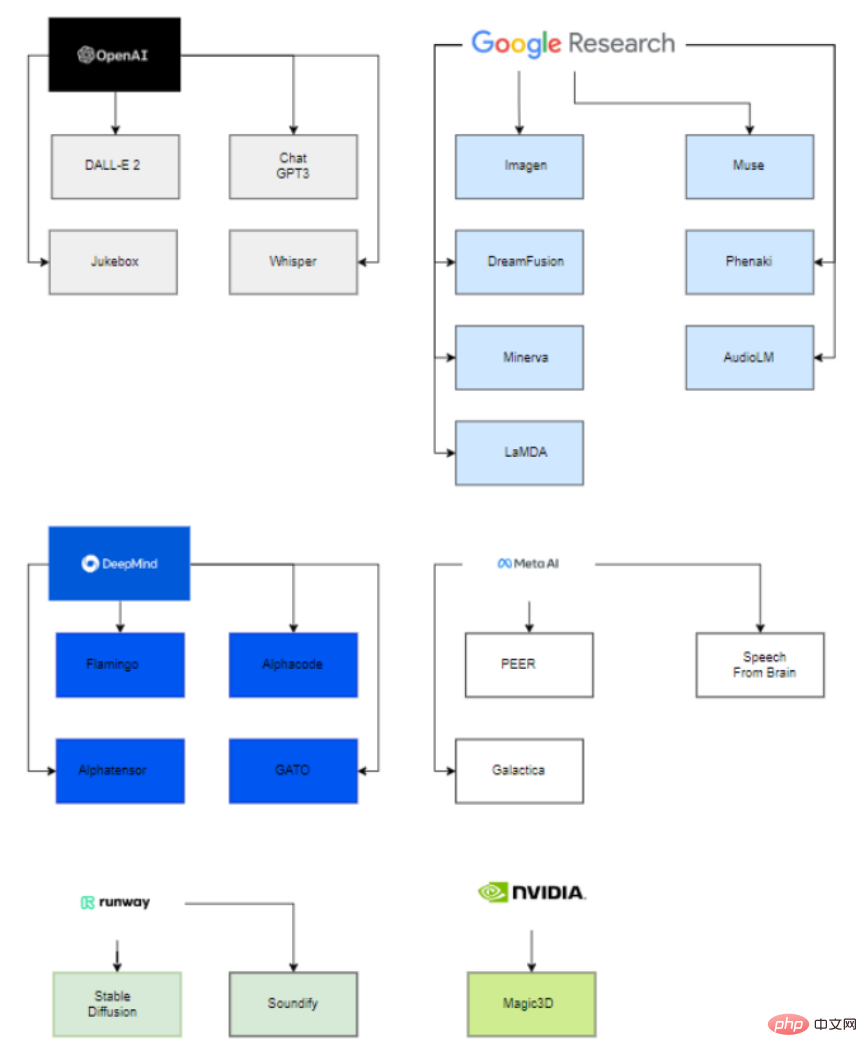
其主要原因是,為了能夠估計這些模型的參數,必須擁有極其龐大的運算能力,以及在資料科學和資料工程方面高度熟練且經驗豐富的團隊。
因此,也只有這些公司,在收購的新創公司和與學術界合作的幫助下,能夠成功部署生成式人工智慧模型。
在大公司參與新創公司方面,可以看到微軟向OpenAI投資了10億美元,並幫助他們開發模型;同樣,Google在2014年收購了Deepmind。
在大學方面,VisualGPT是由阿卜杜拉國王科技大學(KAUST)、卡內基美隆大學和南洋理工大學開發的,Human Motion Diffusion模型是由以色列特拉維夫大學開發的。
同樣,其他專案也是由一家公司與一所大學合作開發的,例如Stable Diffusion由Runway、Stability AI和慕尼黑大學合作開發;Soundify由Runway和卡內基美隆大學合作開發;DreamFusion由Google和加州大學柏克萊分校合作。
Text-to-image模型
由OpenAI開發的DALL-E 2能夠從由文字描述組成的提示中產生原始、真實、逼真的圖像和藝術,而且OpenAI已經對外提供了API來訪問該模型。
DALL-E 2特別之處在於它能夠將概念、屬性和不同風格結合起來,其能力源於語言-圖像預訓練模型CLIP神經網絡,從而可以用自然語言來指示最相關的文字片段。
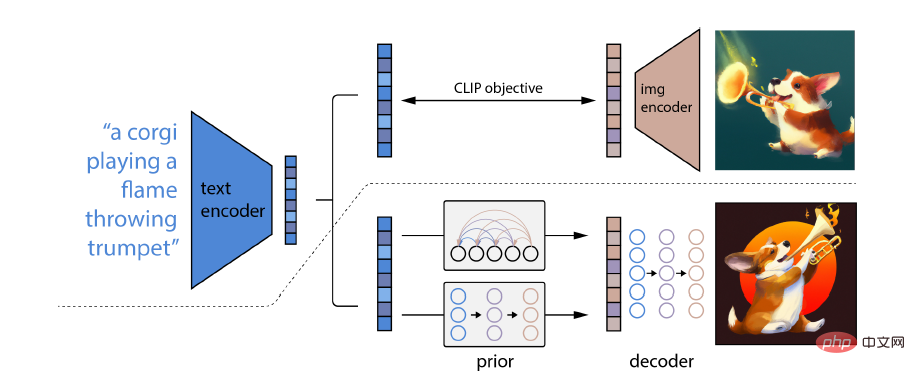
具體來說,CLIP embedding有幾個理想的屬性:能夠對影像分佈進行穩定的轉換;具有強大的zero-shot能力;並且在微調後實現了最先進的結果。
為了獲得一個完整的圖像生成模型,CLIP圖像embedding解碼器模組與一個先驗模型相結合,從一個給定的文本標題中生成相關CLIP圖像embedding

#其他的模型還包括Imagen,Stable Diffusion,Muse
對於某些產業,僅能產生2D影像仍無法完成自動化,例如遊戲領域就需要生成3D模型。
Dreamfusion
DreamFusion由Google Research開發,使用預先訓練好的2D文字到影像的擴散模型來進行文字到3D的合成。
Dreamfusion使用一個從二維擴散模型的蒸餾中得到的損失取代了CLIP技術,即擴散模型可以作為一個通用的連續最佳化問題中的損失來產生樣本。

相比其他方法主要是對像素進行取樣,在參數空間的取樣比在像素空間的取樣要難得多,DreamFusion使用了一個可微的生成器,專注於創建從隨機角度渲染圖像的三維模型。

其他模型如Magic3D由英偉達公司開發。
獲得一個描述圖像的文字也是很有用的,相當於圖像生成的逆版本。
Flamingo
此模型由Deepmind開發,在開放式的視覺語言任務上,只需透過一些輸入/輸出範例的提示,即可進行few- shot學習。
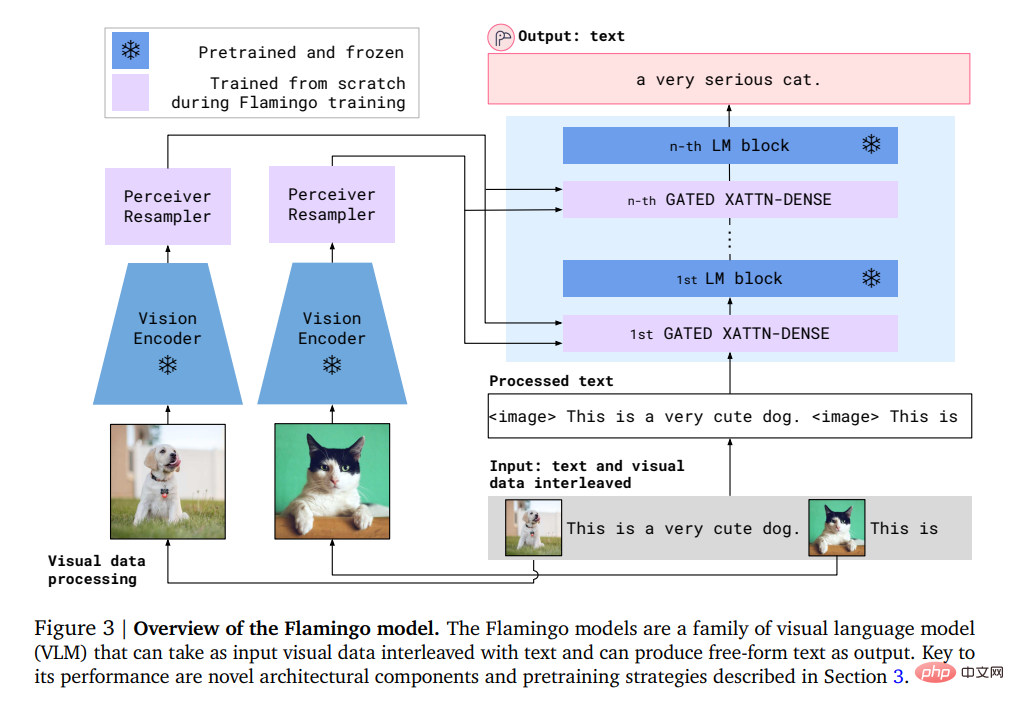
具體來說,Flamingo的輸入包含視覺條件下的自回歸文字產生模型,能夠接收與圖像或視訊交錯的文字token序列,並產生文字作為輸出。
使用者可以向模型輸入query,並附上一張照片或一段視頻,模型就會用文字答案來回答。

Flamingo模型利用了兩個互補的模型:一個是分析視覺場景的視覺模型,一個是執行基本推理形式的大型語言模型。
VisualGPT
VisualGPT是一個由OpenAI開發的圖像描述模型,能夠利用預訓練語言模型GPT-2中的知識。
為了彌合不同模態之間的語意差距,研究人員設計了一個全新的編碼器-解碼器注意力機制,具有整流門控功能。

VisualGPT最大的優點是它不需要像其他圖像到文字模型那樣多的數據,能夠提高圖像描述模型的數據效率,能夠在小眾領域中得到應用或對少見的物體的進行描述。
Phenaki
#此模型由Google Research開發製作,可以在給定一連串文字提示的情況下,進行真實的視訊合成。
Phenaki是第一個能夠從開放域時間變數提示中產生影片的模型。
為了解決資料問題,研究人員在一個大型的圖像-文字對資料集以及數量較少的視訊-文字範例上進行聯合訓練,最終獲得了超越視訊資料集中的泛化能力。
主要是圖像-文字資料集往往有數十億的輸入數據,而文字-視訊資料集則小得多,並且對不同長度的影片進行計算也是一個難題。

Phenaki模型包含三個部分:C-ViViT編碼器、訓練Transformer和視訊產生器。
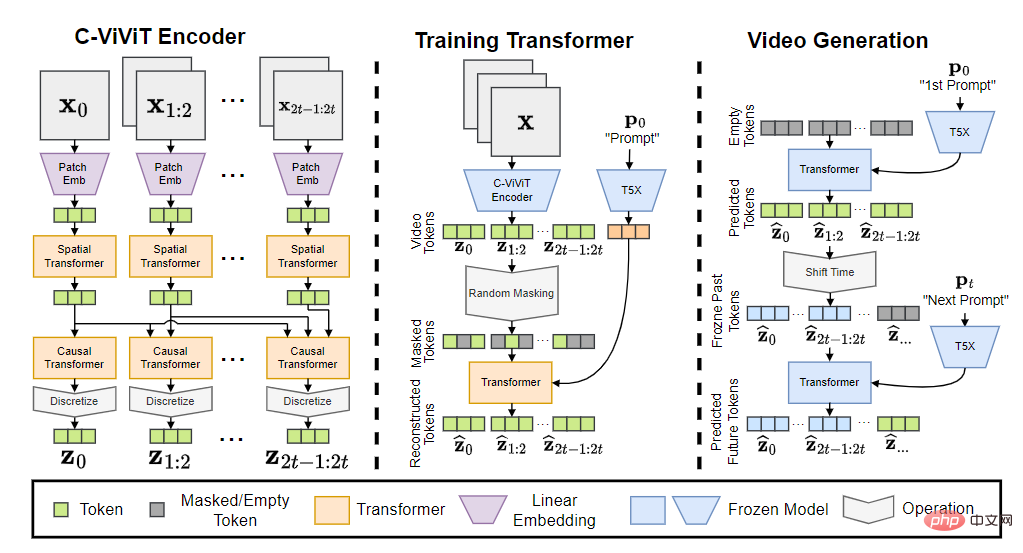
將輸入token轉換為embedding後,接著經過時序Transformer和空間Transformer,再使用一個沒有啟動的單一線性投影,將token對應回像素空間。
最終模型可以產生以開放域提示為條件的時間連貫性和多樣性的視頻,甚至能夠處理一些資料集中不存在的新概念。
相關模型包括Soundify.
#對於影片產生來說,聲音也是不可或缺的部分。
AudioLM
該模型由Google開發,可用於產生高品質的音頻,並具有長距離一致性。
AudioLM的特別之處在於將輸入的音訊映射成離散的token序列,並將音訊產生作為該表示空間的語言建模任務。
透過對原始音訊波形的大型語料庫進行訓練,AudioLM成功地學會了在簡短的提示下產生自然和連貫的連續的語音。這種方法甚至可以擴展到人聲以外的語音,例如連續的鋼琴音樂等等,而不需要在訓練時添加符號表示。
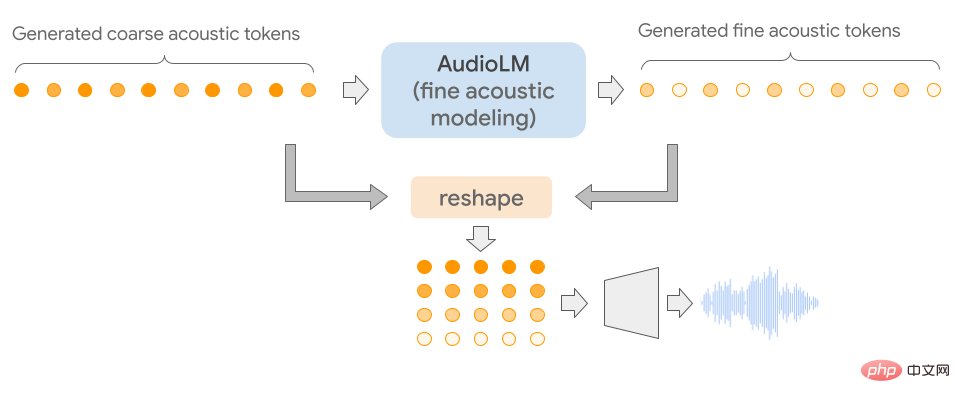
由於音訊訊號涉及多個尺度(scale)的抽象,所以音訊合成時使得多尺度在顯示一致性的同時實現高音訊品質非常具有挑戰性。 AudioLM模型透過結合神經音訊壓縮、自監督表示學習和語言建模的最新進展來實現。
在主觀評估方面,評分者被要求聽一個10秒的樣本,並決定它是人類講話還是合成的語音。基於收集到的1000個評分,比率為51.2%,與隨機分配標籤沒有統計學差異,即人類無法區分合成和真實的樣本。
其他相關模型包括Jukebox和Whisper
問答任務常用。
ChatGPT
廣受歡迎的ChatGPT由OpenAI開發,以對話的方式與用戶互動。
使用者提出一個問題,或是提示文字的前半部分,模型會補全後續部分,並且能夠識別出不正確的輸入前提並拒絕不恰當的請求。
具體來說,ChatGPT背後的演算法是Transformer,訓練過程主要是人類回饋的強化學習。
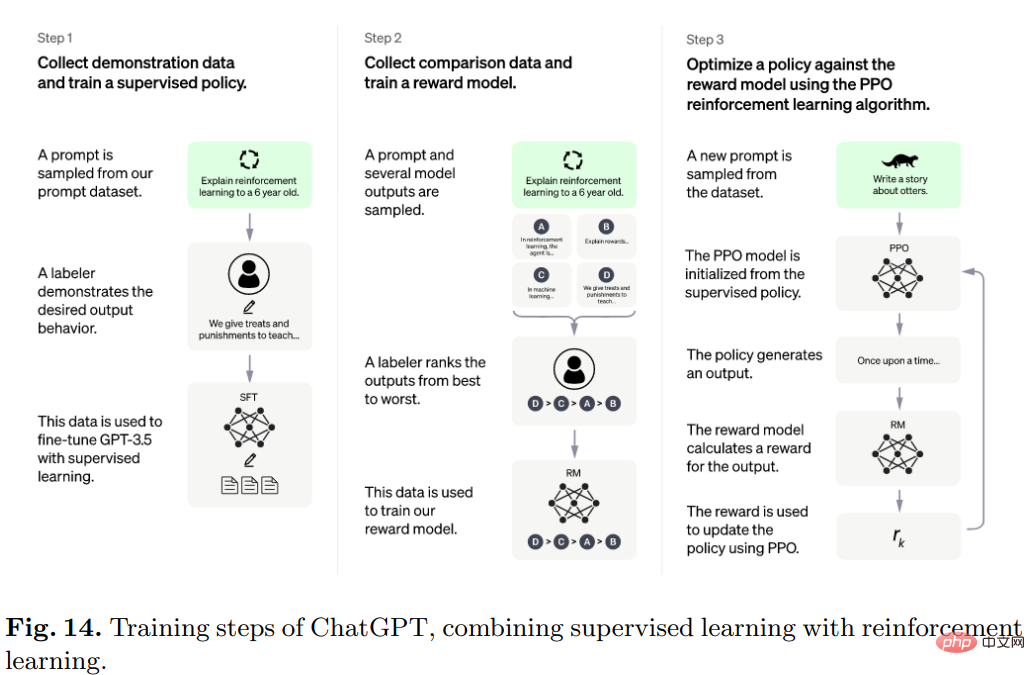
最初的模型是使用監督學習下的微調來訓練的,然後由人類來提供對話,在對話中他們互相扮演用戶和人工智慧助理,然後由人修正模型返回的回复,並用正確的答案幫助模型改進。
將製作的資料集與InstructGPT的資料集混合在一起,轉換為對話格式。
其他相關模型包括LaMDA和PEER
和text-to-text類似,只不過產生的是特殊類型的文本,即代碼。
Codex
該模型由OpenAI開發,可以將文字翻譯成程式碼。
Codex是一種通用的程式設計模型,基本上可以應用於任何程式設計任務。
人類在程式設計時的活動可以分為兩部分:1)將一個問題分解成更簡單的問題;2)將這些問題映射到已經存在的現有程式碼(庫、API或函數)中。
其中第二部分是對程式設計師來說最浪費時間的部分,也是Codex最擅長的地方。
訓練資料於2020年5月從GitHub上託管的公共軟體庫中進行收集,包含179GB的Python文件,並在GPT-3的基礎上進行微調,其中已經包含了強大的自然語言表徵。
相關模型也包含Alphacode
科學研究文字也是AI文本產生的目標之一,但要達成成果仍有很長的路要走。
Galactica
該模型是由Meta AI和Papers with Code共同開發的,可用於自動組織科學文本的大型模型。
Galactica的主要優勢在於即便進行多個episode的訓練後,模型仍然不會過度擬合,並且上游和下游的性能會隨著token的重複使用而提高。
而資料集的設計對此方法至關重要,因為所有的資料都是以通用的markdown格式處理的,從而能夠混合不同來源的知識。
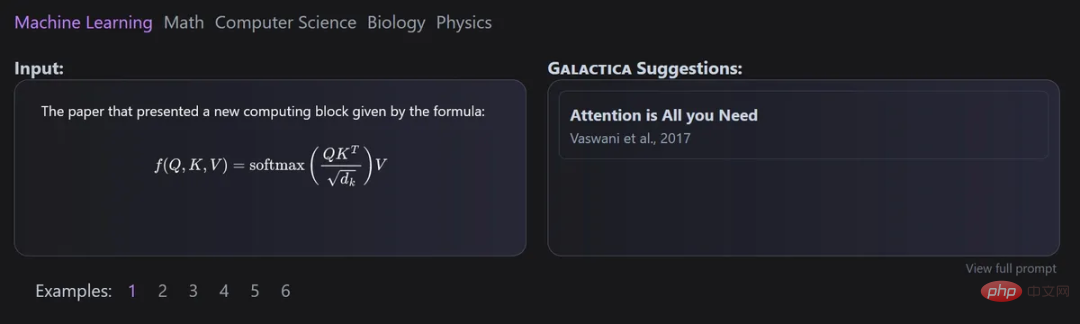
引文(citations)透過一個特定的token來處理,使得研究人員可以在任何輸入上下文中預測一個引文。 Galactica模型預測引文的能力會隨著規模的提升而提高。
此外,模型在僅有解碼器的設定中使用了一個Transformer架構,對所有尺寸的模型進行了GeLU激活,從而可以執行涉及SMILES化學公式和蛋白質序列的多模態任務,
Minerva
Minerva的主要目的是解決決數學和科學問題,為此收集了大量的訓練數據,並解決了定量推理問題,大規模模型開發問題,也採用了一流的推理技術。
Minerva取樣語言模型架構透過使用step-by-step推理來解決輸入的問題,即輸入是需要包含計算和符號操作,而不用引入外部工具。
還有一些模型不屬於前面提到的類別。
AlphaTensor
由Deepmind公司開發,因其發現新演算法的能力,在業界是一個完全革命性的模型。
在已發表的例子中,AlphaTensor創造了一個更有效的矩陣乘法演算法。這種演算法非常重要,從神經網路到科學計算程式都可以從這種高效率的乘法計算中受益。
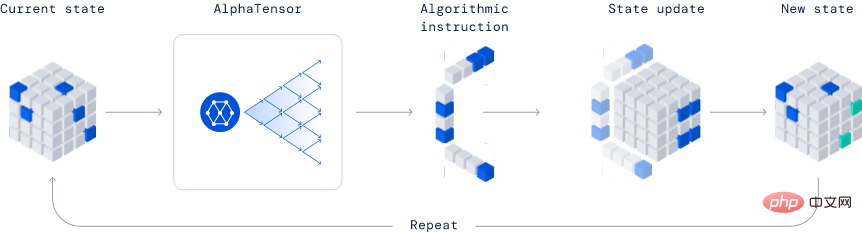
該方法是基於深度強化學習方法,其中智能體AlphaTensor的訓練過程就是玩一個單人遊戲,目標是在有限的因子空間內尋找張量分解。
在TensorGame的每一步,玩家需要選擇如何結合矩陣的不同entries來進行乘法,並根據達到正確的乘法結果所需的操作數量來獲得獎勵分數。 AlphaTensor使用特殊的神經網路架構來利用合成訓練遊戲(synthetic training game)的對稱性。
GATO
該模型是由Deepmind開發的通用智能體,它可以作為一個多模態、多任務或多embodiment泛化策略來使用。
具有相同權重的同一個網路可以承載非常不同的能力,從玩雅達利遊戲、描述圖片、聊天、堆積木等等。
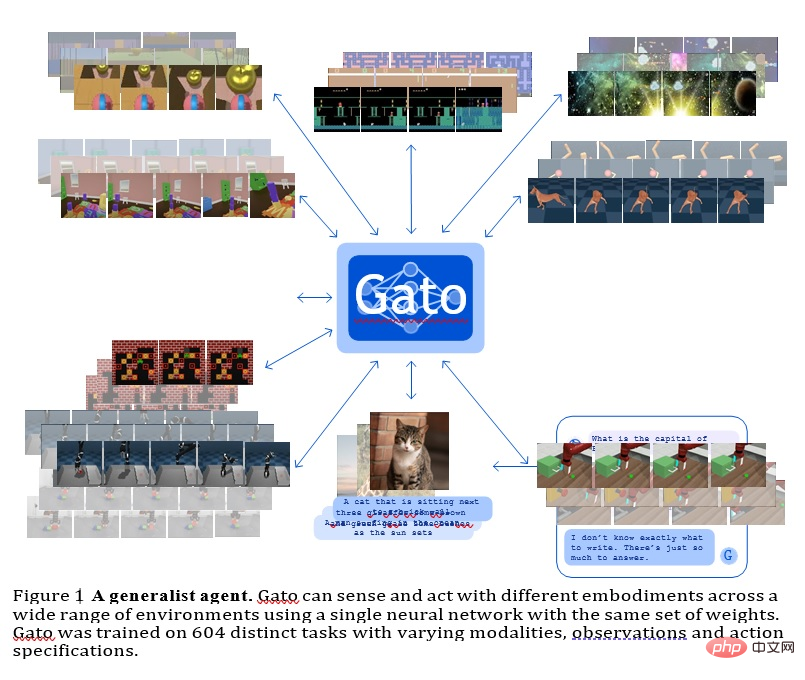
在所有任務中使用單一的神經序列模型有很多好處,減少了手工製作具有自身歸納偏見策略模型的需要,並增加了訓練數據的數量和多樣性。
這種通用智能體在大量任務中都取得了成功,並且可以用很少的額外數據進行調整,以便在更多的任務中取得成功。
目前GATO大約有1.2B個參數,可以即時控制現實世界機器人的模型規模。
其他已發表的生成性人工智慧模型包括生成human motion等。
參考資料:https://arxiv.org/abs/2301.04655
以上是一文看盡SOTA生成式模型:九大類別21個模型全回顧!的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































