

在消費級 GPU 上運行大規模模型是機器學習社群正面臨的挑戰。
語言模型的規模一直在變大,PaLM 有540B 參數,OPT、GPT-3 和BLOOM 有大約176B 參數,模型還在朝著更大的方向發展。

這些模型很難在易於存取的裝置上運行。例如,BLOOM-176B 需要在 8 個 80GB A100 GPU(每個約 15000 美元)上運行才能完成推理任務,而微調 BLOOM-176B 則需要 72 個這樣的 GPU。 PaLM 等更大的模型將需要更多的資源。
我們需要找到方法來降低這些模型的資源需求,同時保持模型的效能。領域內已經開發了各種試圖縮小模型大小的技術,例如量化和蒸餾。
BLOOM 是去年由1000 多名志願研究人員在一個名為「BigScience」的計畫中創建的,該計畫由人工智慧新創公司Hugging Face 利用法國政府的資金運作,今年7 月12 日BLOOM 模型正式發布。
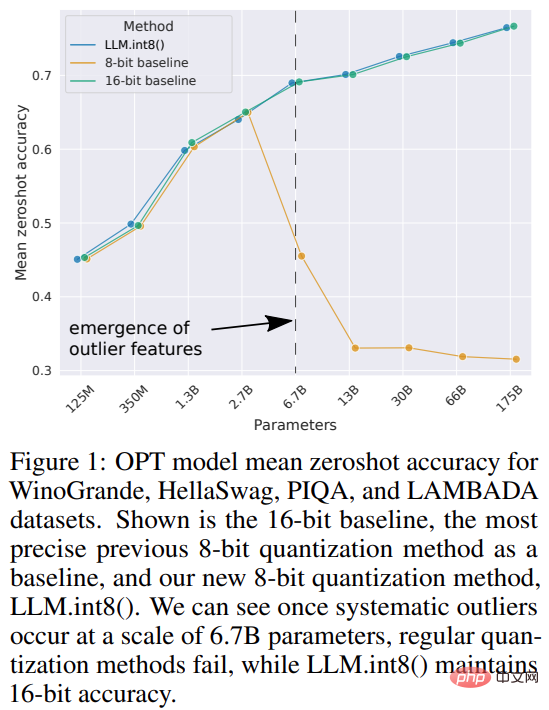
使用 Int8 推理會大幅減少模型的記憶體佔用,但不會降低模型的預測效能。基於此,來自華盛頓大學、Meta AI 研究院等(原Facebook AI Research )機構的研究員聯合HuggingFace 開展了一項研究,試圖讓經過訓練的BLOOM-176B 在更少的GPU 上運行,並將所提方法完全整合到HuggingFace Transformers 中。

該研究為transformer 提出了首個數十億規模的Int8 量化過程,該過程不會影響模型的推理性能。它可以載入一個具有 16-bit 或 32-bit 權重的 175B 參數的 transformer,並將前饋和注意力投影層轉換為 8-bit。其將推理所需的記憶體減少了一半,同時保持了全精度效能。
本研究將向量量化和混合精確度分解的組合命名為 LLM.int8()。實驗表明,透過使用 LLM.int8(),可以在消費級 GPU 上使用多達 175B 參數的 LLM 執行推理,而不會降低效能。此方法不僅為異常值對模型效能的影響提供了新思路,還首次使在消費級 GPU 的單一伺服器上使用非常大的模型成為可能,例如 OPT-175B/BLOOM。
機器學習模型的大小取決於參數的數量及其精確度,通常是float32、float16 或bfloat16之一。 float32 (FP32) 代表標準化的 IEEE 32 位元浮點表示,使用這種資料類型可以表示廣泛的浮點數。 FP32 為「指數」保留 8 位,為「尾數」保留 23 位,為數字的符號保留 1 位。並且,大多數硬體都支援 FP32 操作和指令。
而 float16 (FP16) 為指數保留 5 位,為尾數保留 10 位。這使得 FP16 數字的可表示範圍遠低於 FP32,面臨溢位(試圖表示非常大的數字)和下溢(表示非常小的數字)的風險。
出現溢位時會得到 NaN(非數字)的結果,如果像在神經網路中那樣進行順序計算,那麼很多工作都會崩潰。 bfloat16 (BF16) 則能夠避免這種問題。 BF16 為指數保留 8 位,為小數保留 7 位,表示 BF16 可以保留與 FP32 相同的動態範圍。
理想情況下,訓練和推理應該在 FP32 中完成,但它的速度比 FP16/BF16 慢,因此要使用混合精度來提高訓練速度。但在實務中,半精度權重在推理過程中也能提供與 FP32 相似的品質。這意味著我們可以使用一半精度的權重並使用一半的 GPU 來完成相同的結果。
但是,如果我們可以使用不同的資料類型以更少的記憶體儲存這些權重呢?一種稱為量化的方法已廣泛用於深度學習。
研究首先在實驗中以 2-byte BF16/FP16 半精確度取代 4-byte FP32 精確度,實現了幾乎相同的推理結果。這樣一來,模型就減少了一半。但是如果進一步降低這個數字,精確度會隨之降低,那麼推理品質就會急劇下降。
為了彌補這一點,研究引入 8bit 量化。這種方法使用四分之一的精度,因此只需要四分之一模型大小,但這不是通過去除另一半 bit 來實現的。
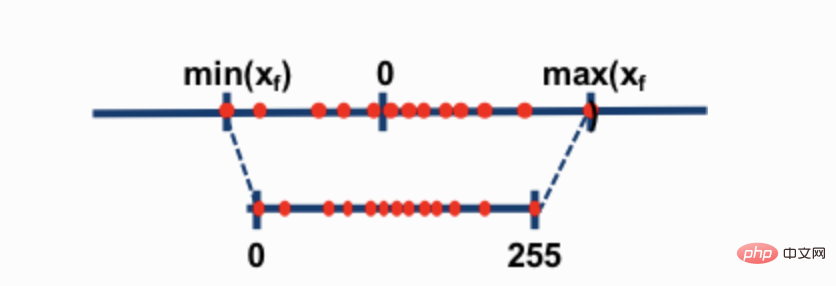
兩種最常見的 8-bit 量化技術為 zero-point 量化和 absmax(absolute maximum)量化。這兩種方法將浮點值映射為更緊湊的 int8(1 位元組)值。
例如,在 zero-point 量化中,如果資料範圍是 -1.0——1.0,量化到 -127——127,其擴展因子為 127。在這個擴展因子下,例如值 0.3 將被擴展為 0.3*127 = 38.1。量化通常會採用四捨五入(rounding),得到了 38。如果反過來,將得到 38/127=0.2992——在這個例子中有 0.008 的量化誤差。這些看似微小的錯誤在通過模型層傳播時往往會累積和增長,並導致性能下降。
雖然這些技術能夠量化深度學習模型,但它們通常會導致模型準確率下降。但整合到 Hugging Face Transformers 和 Accelerate 庫中的 LLM.int8(),是第一種即使對於具有 176B 參數的大型模型 (如 BLOOM) 也不會降低效能的技術。
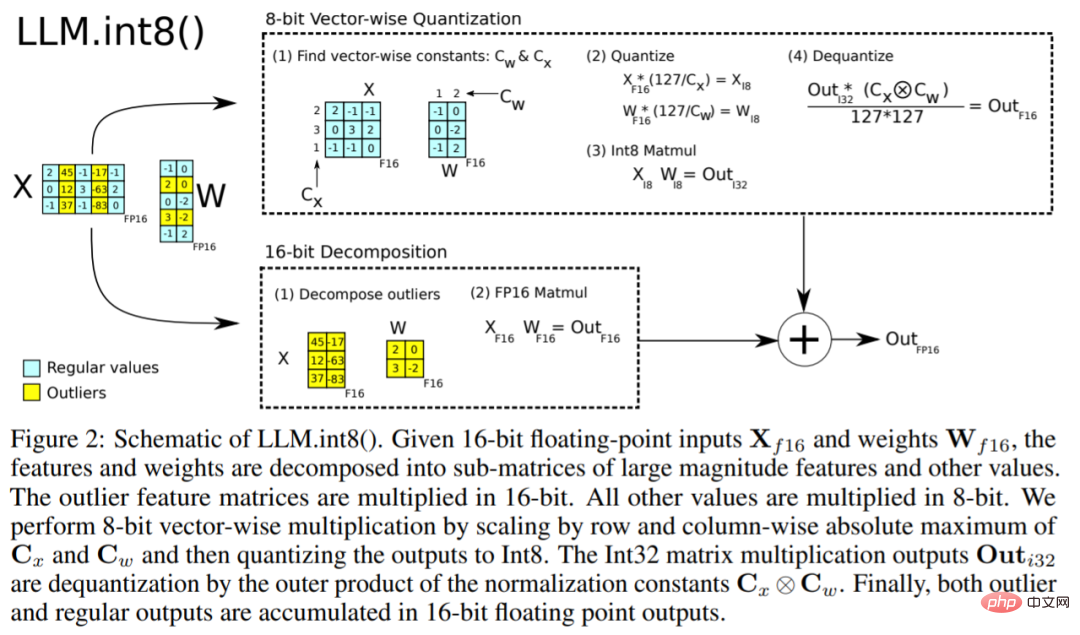
LLM.int8()演算法可以這樣解釋,本質上,LLM.int8()試圖透過三個步驟來完成矩陣乘法計算:
這些步驟可以在下面的動畫中總結:

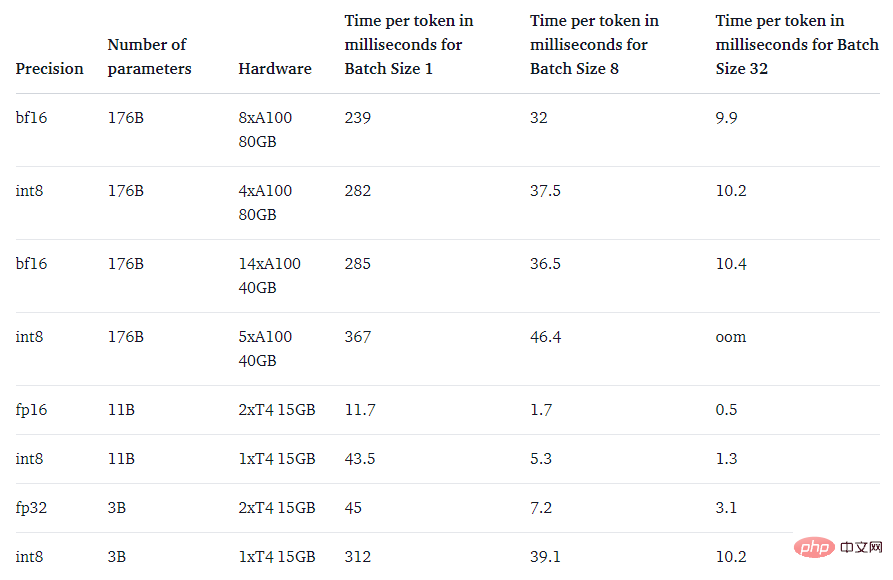
最後,該研究也關注了一個問題:速度比原生模型更快嗎?
LLM.int8() 方法的主要目的是使大型模型更易於存取而不會降低效能。但是,如果它非常慢,那麼用處也不大了。研究團隊對多個模型的生成速度進行了基準測試,發現 LLM.int8() 的 BLOOM-176B 比 fp16 版本慢了大約 15% 到 23%——這是完全可以接受的。而較小的模型(如 T5-3B 和 T5-11B)的減速幅度較大。研究團隊正在努力提升這些小型模型的運行速度。
以上是消費級GPU成功運行1760億參數大模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































