

資料是機器的命脈。沒有它,你就無法建立任何與 AI 相關的東西。根據 Appen 本週發布的 AI 和機器學習狀況報告,許多組織仍在努力獲取良好、乾淨的數據以維持其 AI 和機器學習計劃。
根據Appen對人工智慧的調查,在人工智慧的四個階段——資料採購、資料準備、模型訓練和部署以及人工指導的模型評估中,資料採購消耗的資源最多、花費的時間最多、最具挑戰性。 504 位商業領袖和技術專家。
根據Appen 的調查,平均而言,資料採購消耗組織人工智慧預算的34%,而資料準備和模型測試和部署各佔24%,模型評估各佔15%,該調查由Harris Poll 進行,包括IT 決策者、來自美國、英國、愛爾蘭和德國的商業領袖和經理以及技術從業者。
就時間而言,資料採購消耗組織大約 26% 的時間,而資料準備和模型測試、部署和模型評估分別佔 24% 和 23%。最後,與模型評估 (41%)、模型測試和部署 (38%) 以及資料準備 (34%) 相比,42% 的技術人員認為資料採購是 AI 生命週期中最具挑戰性的階段。
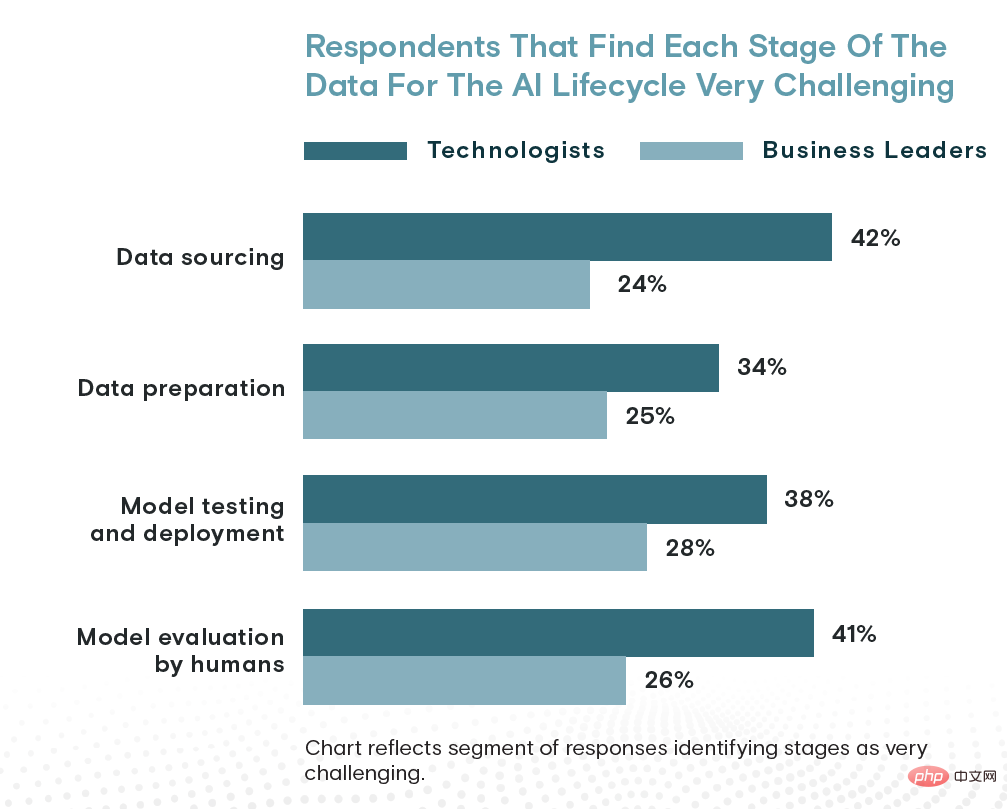
據技術專家稱,資料採購是人工智慧面臨的最大挑戰。但商界領袖對事物的看法不同……
儘管存在挑戰,但組織正在使其發揮作用。據 Appen 稱,五分之四 (81%) 的受訪者表示,他們有信心擁有足夠的數據來支援他們的人工智慧計畫。這項成功的關鍵可能在於:絕大多數 (88%) 正在透過使用外部 AI 訓練資料提供者(例如 Appen)來擴充他們的資料。
然而,數據的準確性是有問題的。 Appen 發現,只有 20% 的調查對象報告資料準確率超過 80%。只有 6%(約十分之一的人)表示他們的數據準確度為 90% 或更高。換句話說,五分之一的資料包含超過 80% 的組織的錯誤。
考慮到這一點,根據 Appen 的調查,近一半 (46%) 的受訪者同意資料準確性很重要,“但我們可以解決它”,這也許並不奇怪。只有 2% 的人表示資料準確性不是一個大需求,而 51% 的人同意這是一個關鍵需求。
看來,Appen 技術長 Wilson Pang 對資料品質重要性的看法與 48% 的客戶認為資料品質不重要。
「資料準確性對於 AI 和 ML 模型的成功至關重要,因為品質豐富的資料會產生更好的模型輸出以及一致的處理和決策制定,」Pang 在報告中說。 「為了獲得良好的結果,資料集必須準確、全面且可擴展。」
#超過90% 的Appen 受訪者表示他們使用預先標記的資料
Pang在最近的一次採訪中告訴表示,深度學習和以數據為中心的AI 的興起已將AI 成功的動力從良好的數據科學和機器學習建模轉變為良好的數據收集、管理和標記。對於當今的遷移學習技術來說尤其如此,人工智慧從業者從一個大型預訓練語言或電腦視覺模型的頂部跳出來,用他們自己的資料重新訓練一小部分層。
更好的數據還可以幫助防止不必要的偏見滲入 AI 模型,並通常防止 AI 出現不良結果。澳鵬人工智慧專家高階主管 Ilia Shifrin 表示,對於大型語言模型尤其如此。
「隨著基於多語言網路爬蟲資料訓練的大型語言模型 (LLM) 的興起,公司面臨著另一個挑戰,」Shifrin 在報告中說。 「由於大量有毒的語言,以及訓練語料庫中的種族、性別和宗教偏見,這些模型經常表現出不良行為。」
Web 數據中的偏見引發了一些棘手的問題,雖然有一些變通方法(改變訓練方案、過濾訓練數據和模型輸出,以及從人類反饋和測試中學習),但需要更多的研究來為「以人為中心」建立一個良好的標準Shifrin 說,LLM 基準和模型評估方法。
據 Appen 稱,資料管理仍然是 AI 面臨的最大障礙。調查發現,人工智慧循環中 41% 的人認為資料管理是最大的瓶頸。缺乏數據排在第四位,30% 的人認為這是 AI 成功的最大障礙。
但也有一些好消息:組織花在管理和準備資料上的時間呈下降趨勢。 Appen 說,今年這一比例剛超過 47%,而去年的報告中為 53%。
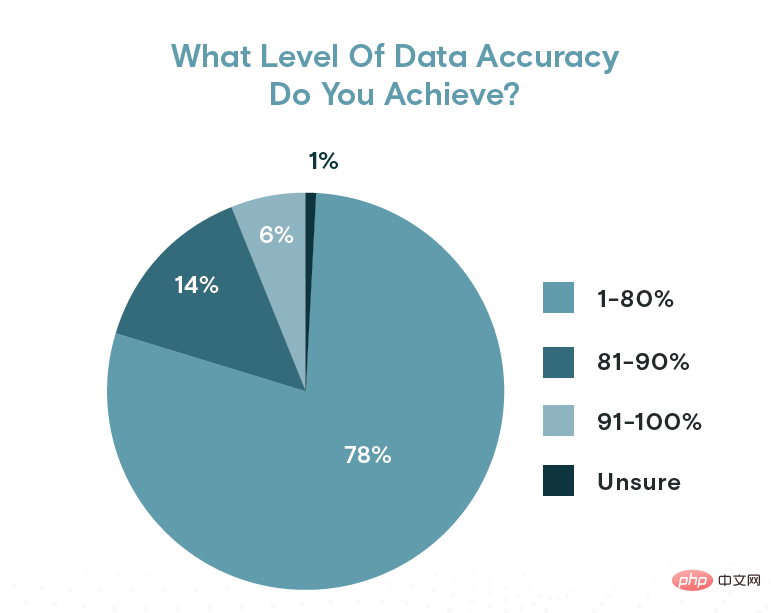
資料準確性水準可能沒有某些組織希望的那麼高
「大多數受訪者使用外部資料供應商,可以推斷,透過外包資料採購和準備,資料科學家正在節省正確管理、清理和標記資料所需的時間,」數據標籤公司表示。
然而,從資料中相對較高的錯誤率來看,也許組織不應該縮減他們的資料採購和準備流程(無論是內部的還是外部的)。在建立和維護 AI 流程方面有許多相互競爭的需求—聘用合格的資料專業人員是澳鵬確定的另一個首要需求。但是,在資料管理方面取得重大進展之前,組織應繼續對其團隊施加壓力,以繼續推動資料品質的重要性。
調查也發現,93% 的組織強烈或在某種程度上同意道德 AI 應該是 AI 計畫的「基礎」。 Appen 執行長 Mark Brayan 表示,這是一個良好的開端,但還有很多工作要做。 「問題是,許多人都面臨著試圖用糟糕的數據集構建偉大的人工智慧的挑戰,這為實現他們的目標創造了一個重要的障礙,」 Brayan 在一份新聞稿中說。
根據 Appen 的報告,內部、自訂收集的資料仍然是用於 AI 的組織的大部分資料集,佔資料的 38% 到 42%。合成資料的表現出乎意料地強勁,佔組織資料的 24% 到 38%,而預先標記的資料(通常來自資料服務提供者)佔資料的 23% 到 31%。
特別是合成資料有可能減少敏感人工智慧專案中的偏見發生率,97% 的澳鵬受訪者表示他們「在開發包容性訓練資料集時」使用合成資料。
該報告的其他有趣發現包括:
以上是研究顯示:資料來源仍然是 AI 的主要瓶頸的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































