

以Transformer為核心的自回歸注意力類程式始終難以跨越規模化這道難關。為此,DeepMind/Google最近建立新項目,提出一個幫助這類程序有效瘦身的好方法。
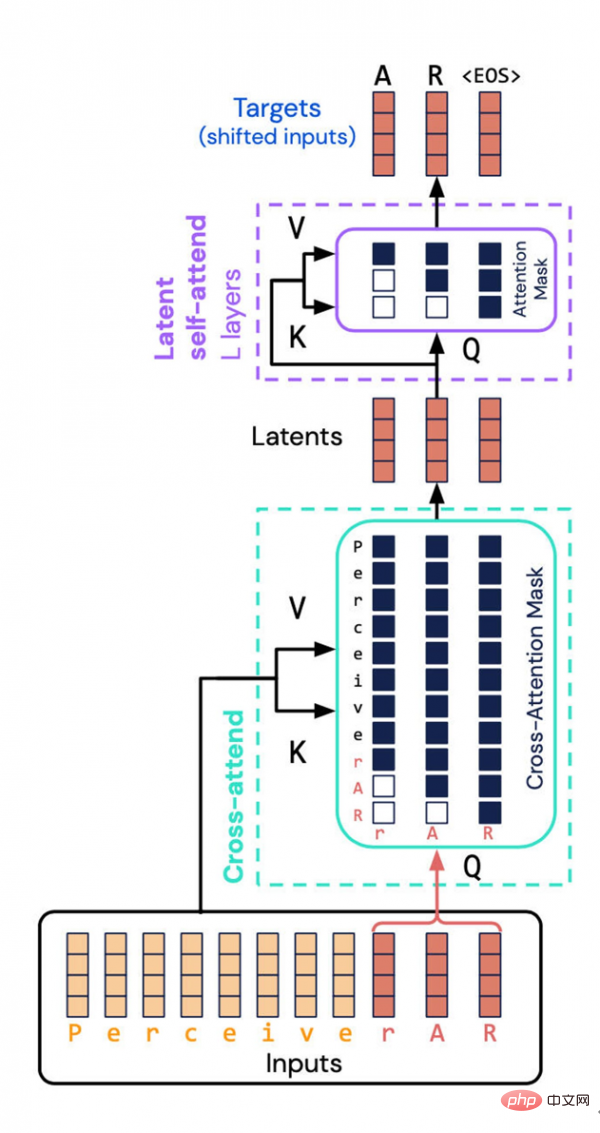
DeepMind與Google Brain打造的Perceiver AR架構迴避了一大嚴重佔用資源的任務-將輸入與輸出的組合性質計算至潛在空間。相反,他們向潛在空間引入了“因果掩蔽”,由此實現了典型Transformer的自回歸順序。
人工智慧/深度學習領域最令人印象深刻的發展趨勢之一,就是模型體量越來越大。該領域的專家表示,由於規模往往與效能直接掛鉤,所以這股體量膨脹的浪潮恐怕還會持續下去。
但專案規模越來越大,消耗的資源自然也越來越多,這就導致深度學習引發了社會倫理層面的新問題。這一困境,已經得到《自然》等主流科學期刊的關注。
也正因為如此,我們恐怕又要回歸「效率」這個老字眼——AI程序,到底還沒有進一步提效的空間?
DeepMind及Google Brain部門的科學家們,最近對自己去年推出的神經網路Perceiver進行了一番改造,希望能提升其對算力資源的使用效率。
新程式被命名為Perceiver AR。這裡的AR源自於自回歸“autoregressive”,也是如今越來越多深度學習程式的另一個發展方向。自迴歸是一種讓機器將輸出作為程式新輸入的技術,屬於遞歸操作,藉此構成多個元素相互關聯的注意力圖。
Google在2017年推出的大受歡迎的神經網路Transformer,也同樣具有這種自回歸特性。事實上,後來出現的GPT-3以及Perceiver的首個版本都延續了自回歸的技術路線。
在Perceiver AR之前,今年3月推出的Perceiver IO是Perceiver的第二個版本,再向前追溯就是去年這個時候發布的Perceiver初版了。
最初的Perceiver創新點,在於採用Transformer並做出調整,使其能夠靈活吸收各種輸入,包括文字、聲音和影像,由此脫離對特定類型輸入的依賴。如此一來,研究人員即可利用多種輸入類型來開發對應的神經網路。
身為時代大潮中的一員,Perceiver跟其他模型項目一樣,也都開始使用自回歸注意力機制將不同輸入模式和不同任務域混合起來。這類用例還包括Google的Pathways、DeepMind的Gato,以及Meta的data2vec。
到今年3月,初版Perceiver的締造者Andrew Jaegle及其同事團隊又發布了「IO」版本。新版本增強了Perceiver所支援的輸出類型,實現了包含多種結構的大量輸出,具體涵蓋文字語言、光流場、視聽序列甚至符號無序集等等。 Perceiver IO甚至能夠產生《星海爭霸2》遊戲中的操作指令。
在這次的最新論文中,Perceiver AR已經能夠以長上下文實現通用自回歸建模。但在研究當中,Jaegle及其團隊也遇到了新的挑戰:模型應對各類多模式輸入和輸出任務時,該如何實現擴展。
問題在於,Transformer的自迴歸質量,以及任何同樣建構輸入到輸出注意力圖的程序,都需要包含多達數十萬個元素的巨量分佈規模。
這就是注意力機制的致命弱點所在。更準確地說,需要專注於一切才能建立起注意力圖的機率分佈。
正如Jaegle及其團隊在論文中提到,當輸入當中需要相互比較的事物數量的增加,模型對算力資源的吞噬也將愈發誇張:
這種長上下文結構與Transformer的計算特性之間相互衝突。 Transformers會重複對輸入執行自註意力操作,這會導致計算需求同時隨輸入長度而二次增長,並隨模型深度而線性增加。輸入資料越多,觀察資料內容所對應的輸入標記就越多,輸入資料中的模式也變得愈發微妙且複雜,必須用更深的層對所產生的模式進行建模。而由於算力有限,Transformer使用者被迫要麼截斷模型輸入(防止觀察到更多遠距離模式),要麼限制模型的深度(也就剝奪了它對複雜模式進行建模時的表達能力)。
實際上,初版Perceiver也曾經嘗試過提高Transformers的效率:不直接執行注意力,而是對輸入的潛在表示執行注意力。如此一來,即可「(解耦)處理大型輸入數組的算力要求同大深度網路所對應的算力需求」。
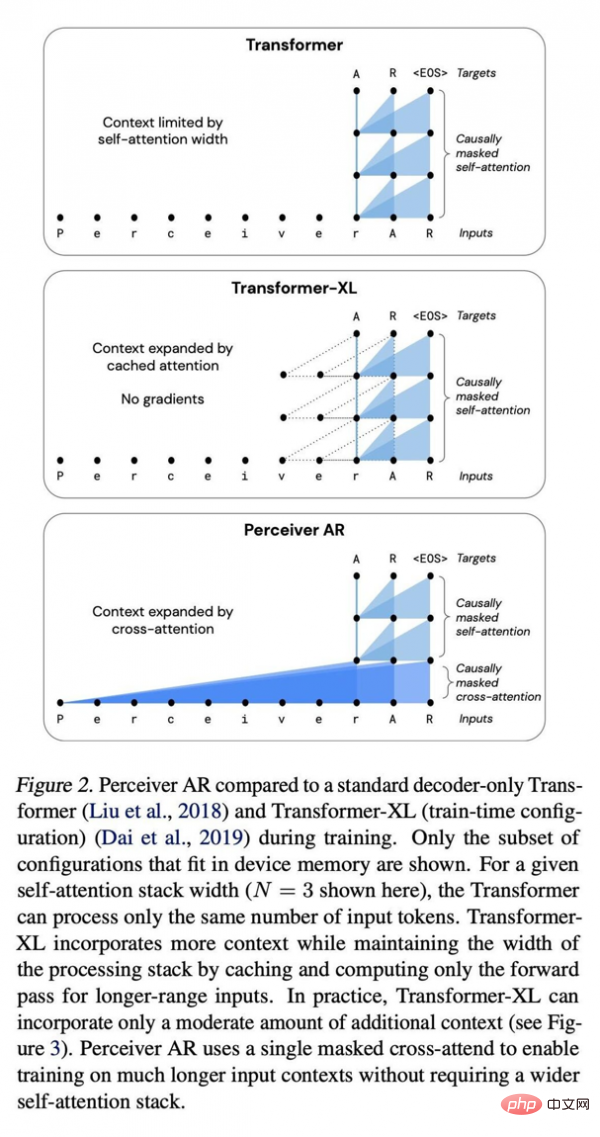
Perceiver AR與標準Transformer深度網路、增強型Transformer XL間的比較。
在潛在部分中,輸入表示經過了壓縮,因此成為一種效率更高的注意力引擎。這樣,“對於深度網絡,大部分計算就實際發生在自註意力堆疊上”,而無需對無數輸入執行操作。
但挑戰仍然存在,因為潛在表示不具備順序概念,所以Perceiver無法像Transformer那樣產生輸出。而順序在自回歸中至關重要,每個輸出都應該是它先前輸入的產物,而非之後的產物。
研究人員寫道,「但由於每個潛在模型都關注所有輸入,而不管其位置如何,所以對於要求每個模型輸出必須僅依賴其先前輸入的自回歸生成來說, Perceiver將無法直接適用。」
而到了Perceiver AR這邊,研究團隊更進一步,將順序插入至Perceiver當中,使其能夠實現自動回歸功能。
這裡的關鍵,就是對輸入和潛在表示執行所謂「因果掩蔽」。在輸入側,因果掩蔽會執行“交叉注意”,而在潛在表示這邊則強制要求程序只關注給定符號之前的事物。這種方法恢復了Transformer的有向性,且仍能顯著降低計算總量。
結果就是,Perceiver AR能夠基於更多輸入實現與Transformer相當的建模結果,但效能得以大幅提升。
他們寫道,「Perceiver AR可以在合成複製任務中,完美識別並學習相距至少100k個標記的長上下文模式。」相較之下,Transformer的硬限制為2048個標記,標記越多則上下文越長,程式輸出就越複雜。
與廣泛使用純解碼器的Transformer和Transformer-XL架構相比,Perceiver AR的效率更高,而且能夠根據目標預算靈活改變測試時實際使用的算力資源。
論文寫道,在同等注意力條件下,計算Perceiver AR的掛鐘時間要明顯更短,且能夠要同等算力預算下吸收更多上下文(即更多輸入符號):
Transformer的上下文長度限制為2048個標記,相當於只支援6個層-因為更大的模型和更長的上下文需要佔用巨量記憶體。使用相同的6層配置,我們可以將Transformer-XL記憶體的總上下文長度擴展至8192個標記。 Perceiver AR則可將上下文長度擴展至65k個標記,若配合進一步優化,甚至可望突破100k。
所有這一切,都令計算變得更加靈活:「我們能夠更好地控制給定模型在測試過程中產生的計算量,並使我們能夠在速度與性能間穩定求取平衡」
Jaegle及其同事也寫道,這種方法適用於任意輸入類型,並不限於單字符號。例如可以支援影像中的像素:
只要應用了因果掩蔽技術,相同過程就適用於任何可以排序的輸入。例如,透過對序列中每個像素的R、G、B顏色通道進行有序或亂序解碼,即可按光柵掃描順序為影像的RGB通道排序。
作者們發現Perceiver中蘊藏著巨大潛力,並在論文中寫道,「Perceiver AR是長上下文通用型自回歸模型的理想候選方案。」
但要追求更高的計算效率,還需要解決另一個額外的不穩定因素。作者們指出,最近研究界也在嘗試透過「稀疏性」(即限制部分輸入元素被賦予重要性的過程)來減少自回歸注意力的算力需求。
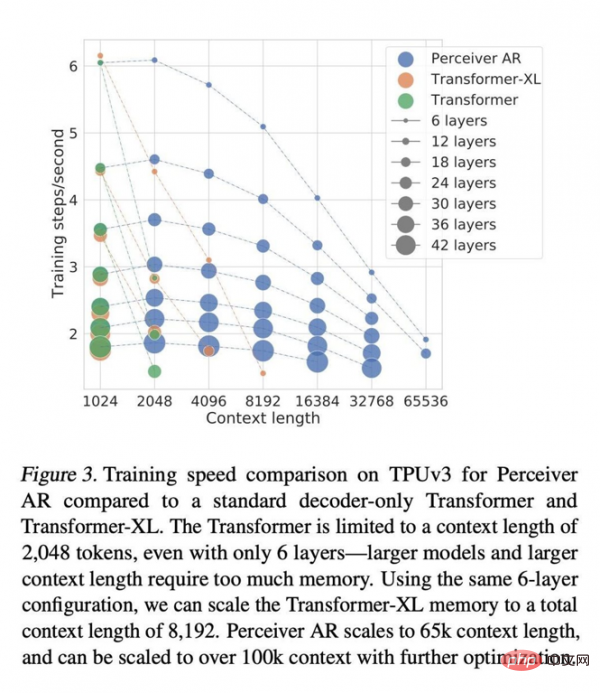
在相同的掛鐘時間內,Perceiver AR能夠在層數相同的情況下運行更多來自輸入的符號,或在輸入符號運行數量相同的情況下顯著縮短計算時長。作者認為,這種出色的靈活性有望為大型網路找到通用的提效方法。
但稀疏性也有自己的缺點,主要就是過於死板。論文寫道,「使用稀疏性方法的缺點在於,必須以手動調整或啟發式方法創建這種稀疏性。這些啟發式方法往往只適用於特定領域,而且往往很難調整。」OpenAI與英偉達在2019年發布的Sparse Transformer就屬於稀疏性專案。
他們解釋道,「相較之下,我們的工作並不需要在註意力層上強製手動創建稀疏模式,而是允許網路自主學習哪些長上下文輸入更需要關注、更需要通過網路進行傳播。」
論文還補充稱,「最初的交叉注意力操作減少了序列中的位置數量,可以被視為一種稀疏學習形式。」
對此種方式學習到的稀疏性本身,也許在未來幾年內成為深度學習模型工具包中的另一個強大利器。
#以上是DeepMind表示:AI模型需要減肥,自回歸成為主要趨勢的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















