

國際學習表徵會議 ICLR(International Conference on Learning Representations),被公認為目前最具影響力的機器學習國際學術會議之一。
在今年的 ICLR 2023 大會上,微軟亞洲研究院發表了在機器學習穩健性、負責任的人工智慧等領域的最新研究成果。
其中,微軟亞洲研究院與韓國科學技術院(KAIST)在雙方學術合作框架下的科研合作成果,因其出色的清晰性、洞察力、創造力和潛在的持久影響獲評ICLR 2023 傑出論文獎。

#論文網址:https://arxiv.org/abs/2303.14969
密集預測任務是電腦視覺領域的一類重要任務,如語意分割、深度估計、邊緣偵測和關鍵點偵測等。對於這類任務,手動標註像素級標籤面臨著難以承受的巨額成本。因此,如何從少量的標註資料中學習並作出準確預測,即小樣本學習,是該領域備受關注的課題。近年來,關於小樣本學習的研究不斷取得突破,尤其是一些基於後設學習和對抗學習的方法,深受學術界的關注和歡迎。
然而,現有的電腦視覺小樣本學習方法一般針對特定的某一類任務,如分類任務或語意分割任務。它們通常在設計模型架構和訓練過程中利用特定於這些任務的先驗知識和假設,因此不適合推廣到任意的密集預測任務。微軟亞洲研究院的研究員們希望探究一個核心問題:是否存在一個通用的小樣本學習器,可以從少量標記圖像中學習任意段未見過的密集預測任務。
一個密集預測任務的目標是學習從輸入圖像到以像素為單位註釋的標籤的映射,它可以被定義為:
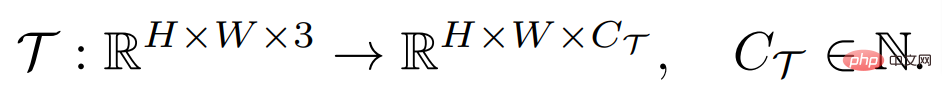
#其中H 和W 分別是影像的高與寬,輸入影像一般包含RGB 三個通道,C_Τ 表示輸出通道的數目。不同的密集預測任務可能涉及不同的輸出通道數目和通道屬性,如語意分割任務的輸出是多通道二值的,而深度估計任務的輸出是單通道連續值的。一個通用的小樣本學習器F,對於任何這樣的任務Τ,在給定少量標記樣本支持集S_Τ(包含了N 組樣本X^i 和標註Y^i)的情況下,可以為未見過的查詢圖像X^q 產生預測,即:
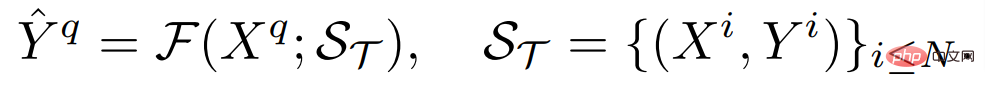
如果存在適合任意密集預測任務的通用小樣本學習器,那麼必須滿足以下期望:
因此,微軟亞洲研究院的研究員設計並實現了小樣本學習器視覺token匹配VTM(Visual Token Matching),其可用於任意的密集預測任務。這是首個適配所有密集預測任務的小樣本學習器,VTM 為電腦視覺中密集預測任務的處理以及小樣本學習方法打開了全新的思路。這份工作獲得了 ICLR 2023 傑出論文獎。
VTM 的設計靈感源自於類比人類的思考過程:給定一個新任務的少量範例,人類可以根據範例之間的相似性快速將類似的輸出分配給類似的輸入,同時也可以根據給定的上下文靈活變通輸入和輸出之間在哪些層面相似。研究員們使用基於影像區塊(patch)層級的非參數匹配實現了密集預測的類比過程。透過訓練,模型被啟發出了捕捉影像區塊中相似性的能力。
給定一個新任務的少量標記範例,VTM 首先會根據給定的範例以及範例的標籤調整其對相似性的理解,從範例影像區塊中鎖定與待預測影像區塊相似的影像區塊,透過組合它們的標籤來預測未見過的影像區塊的標籤。
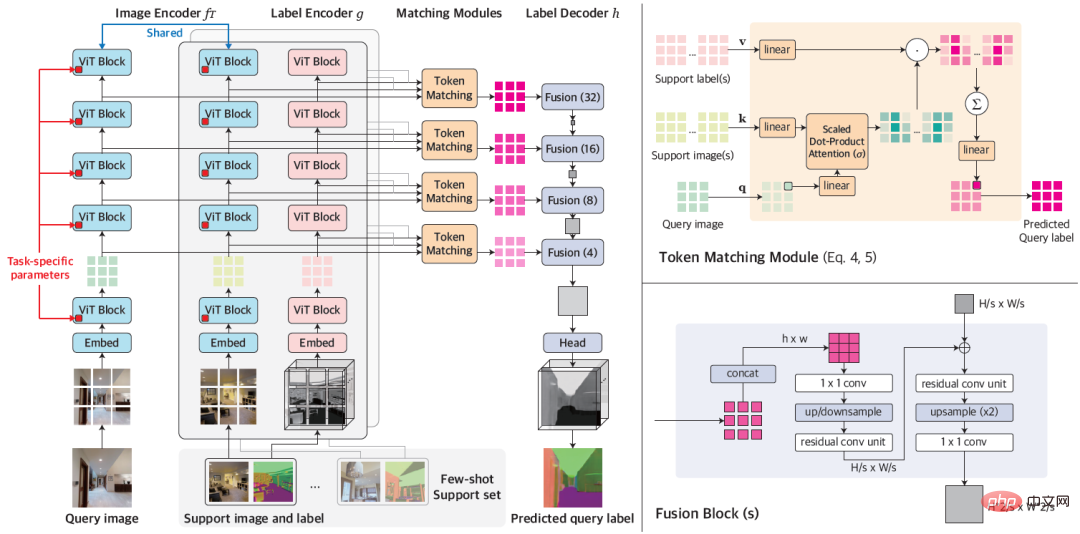
圖1:VTM 的整體架構
VTM 採用分層的編碼器-解碼器架構,在多個層次上實現了基於影像區塊的非參數匹配。它主要由四個模組組成,分別為影像編碼器 f_Τ、標籤編碼器 g、匹配模組和標籤解碼器 h。給定查詢圖像和支援集,圖像編碼器首先會獨立地提取每個查詢和支援圖像的圖像塊級表達。標籤編碼器也會類似地提取每個支援標籤的標記。在每個層次的標記給定後,匹配模組會執行非參數匹配,最終由標籤解碼器推斷出查詢圖像的標籤。
VTM 的本質是一個元學習方法。其訓練由多個 episode 組成,每個 episode 模擬一個小樣本學習問題。 VTM 訓練運用到了元訓練資料集 D_train,其中包含多種有標籤的密集預測任務範例。每個訓練 episode 都會模擬資料集中特定任務 T_train 的小樣本學習場景,目標是在給定支援集的條件下,為查詢影像產生正確的標籤。透過多個小樣本學習的經驗,模型能夠學習到通用的知識,以便快速、靈活地適應新的任務。在測試時,模型需要在訓練資料集 D_train 中未包含的任意任務 T_test 上進行小樣本學習。
在處理任意任務時,由於元訓練和測試中的每個任務的輸出維度 C_Τ 不同,因此使得為所有任務設計統一的通用模型參數成為了巨大挑戰。為了提供一個簡單而普適的解決方案,研究員將任務轉換為 C_Τ 個單通道子任務,分別學習每個通道,並使用共享的模型 F 獨立地對每個子任務進行建模。
為了測試 VTM ,研究員們也特別建構了 Taskonomy 資料集的變種,從而模擬未見過的密集預測任務的小樣本學習。 Taskonomy 包含各種標註過的室內圖像,研究員從中選擇了十個具有不同語義和輸出維度的密集預測任務,將其分為五個部分用於交叉驗證。在每個拆分方式中,兩個任務用於小樣本評估(T_test),其餘八個任務用於訓練(T_train)。研究員們仔細建構了分區,使得訓練和測試任務彼此有足夠的差異,例如將邊緣任務(TE,OE)分組為測試任務,以便對新語義的任務進行評估。
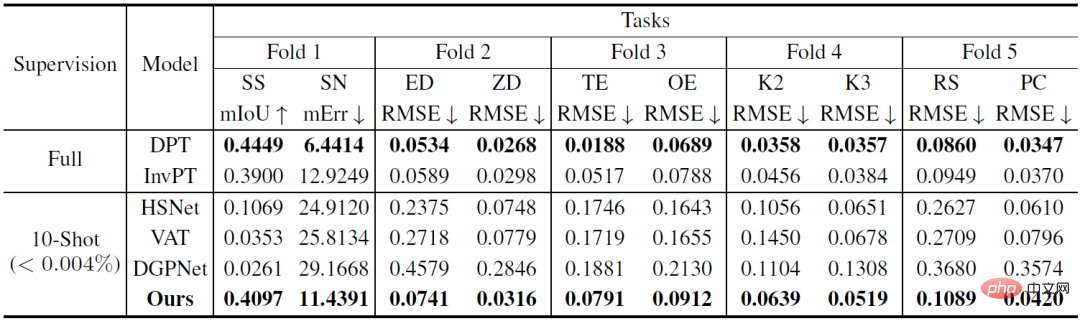
表1:在Taskonomy 資料集上的定量比較( Few-shot 基準在訓練了來自其他分區的任務後,在需測試的分區任務上進行了10-shot 學習,其中完全監督的基線在每個fold(DPT)或所有fold(InvPT)上訓練和評估了任務)
表1和圖2分別定量與定性地展示了 VTM 和兩類基準模型在十個密集預測任務上的小樣本學習表現。其中,DPT 和 InvPT 是兩種最先進的監督學習方法,DPT 可獨立地針對每個單一任務進行訓練,而 InvPT 則可以共同訓練所有任務。由於在VTM 之前還沒有針對通用密集預測任務開發的專用小樣本方法,因此研究員們將VTM 與三種最先進的小樣本分割方法,即DGPNet、HSNet 和VAT,進行對比,並將它們拓展到處理密集預測任務的一般標籤空間。 VTM 在訓練期間沒有訪問測試任務T_test,並且僅在測試時使用了少量(10張)的標記圖像,但它卻在所有小樣本基線模型中表現得最好,並且在許多任務中的表現都具備與全監督基準模型比較的競爭力。
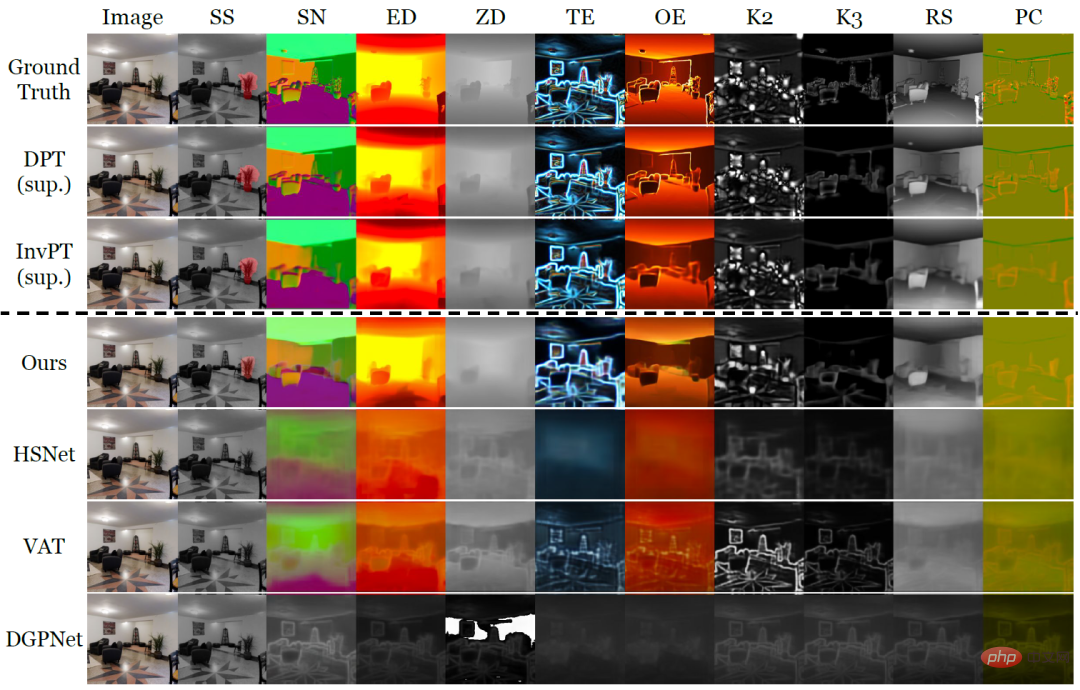
圖2:在Taskonomy 的十個密集預測任務中,在新任務上僅提供十張標記圖像的小樣本學習方法的定性比較。在其他方法失敗的情況下, VTM 成功地學習了所有具有不同語義和不同標籤表示的新任務。
在圖2中,虛線上方的分別是真實標籤和兩種監督學習方法 DPT 和 InvPT。虛線下方的是小樣本學習方法。值得注意的是,其他小樣本基準在新任務上出現了災難性的欠擬合,而 VTM 成功地學習了所有任務。實驗說明,VTM 可以在極少量的標記示例(<0.004%的完全監督)上現表現出與完全監督基線類似的競爭力,並能夠在相對較少的附加數據(0.1%的完全監督)下縮小與監督方法的差距,甚至實現反超。
總結來說,儘管VTM 的底層思路非常簡單,但它具有統一的體系結構,可用於任意密集預測任務,因為匹配演算法本質上包含所有任務和標籤結構(例如,連續或離散)。此外,VTM 僅引入了少量的任務特定參數,就能具備抗過擬合與彈性。未來研究員希望進一步探討預訓練過程中的任務類型、資料量、以及資料分佈對模型泛化表現的影響,以幫助我們建構一個真正普適的小樣本學習器。
以上是通用小樣本學習器:適用於各種密集預測任務的解決方案的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















