

本月初,Meta 發布「分割一切」AI 模型 ——Segment Anything Model(SAM)。 SAM 被認為是通用的影像分割基礎模型,它學會了關於物體的一般概念,可以為任何影像或影片中的任何物體產生 mask,包括在訓練過程中沒有遇到的物體和影像類型。這種「零樣本遷移」的能力令人驚嘆,甚至有人稱 CV 領域迎來了「GPT-3 時刻」。
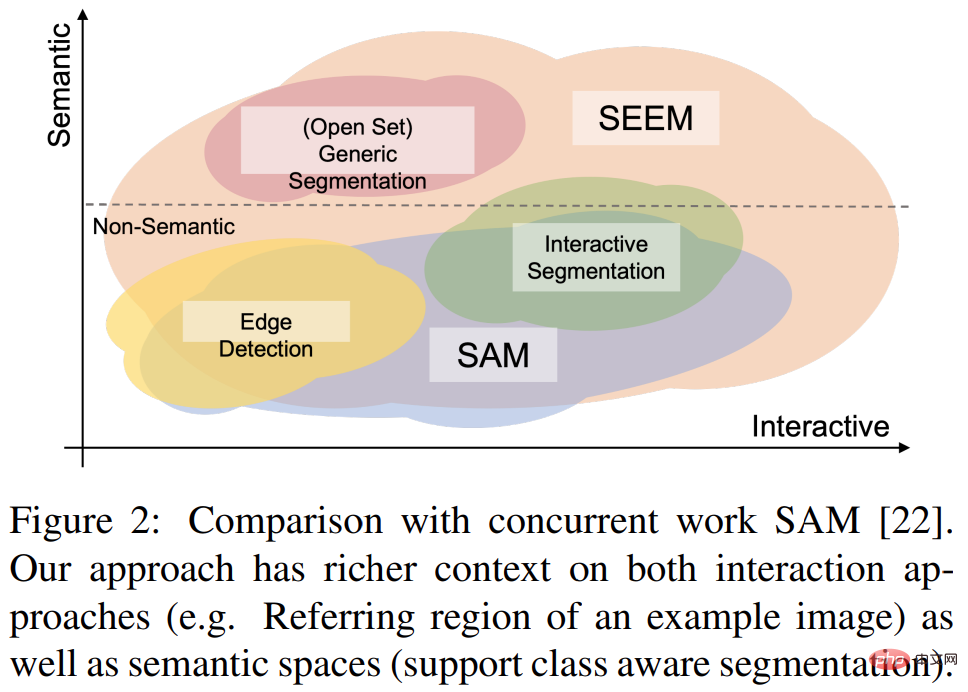
最近,一篇「一次分割一切」的新論文《Segment Everything Everywhere All at Once》再次引起關注。在論文中,來自威斯康辛大學麥迪遜分校、微軟、香港科技大學的幾位華人研究者提出了一種基於 prompt 的新型互動模型 SEEM。 SEEM 能夠根據使用者給予的各種模態的輸入(包括文字、圖像、塗鴉等等),一次分割圖像或影片中的所有內容,並識別出物件類別。該專案已經開源,並提供了試玩地址供大家體驗。

論文連結:https://arxiv.org/pdf/2304.06718.pdf
#專案連結:https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once
#試用網址:https://huggingface.co/spaces/xdecoder/SEEM
該研究透過全面的實驗驗證了SEEM 在各種分割任務上的有效性。即使 SEEM 不具有了解使用者意圖的能力,但它表現出強大的泛化能力,因為它學會了在統一的表徵空間中編寫不同類型的 prompt。此外,SEEM 可以透過輕量級的 prompt 解碼器有效地處理多輪互動。
先來看看分割效果:
在變形金剛的合照中把「擎天柱」分割出來:

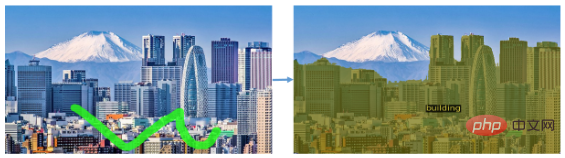
也能對一類物件分割,例如在一張景觀圖片中分割出所有建築物:
SEEM 也能輕鬆分割影片中移動的物件:

這個分割效果可以說是非常絲滑了。我們來看看該研究提出的方法。
該研究旨在提出一個通用接口,以藉助多模態 prompt 進行影像分割。為了實現這一目標,他們提出了一個包含4 個屬性的新方案,包括多功能性(versatility)、組合性(compositionality)、互動性(interactivity)和語義感知能力(semantic-awareness),具體包括
1)多功能性研究提出將點、遮罩、文字、偵測框(box)甚至是另一個影像的參考區域(referred region)這些異質的元素,編碼成同一個聯合視覺語意空間中的prompt。
2)組合性透過學習視覺和文字 prompt 的聯合視覺語義空間來即時編寫查詢以進行推理。 SEEM 可以處理輸入 prompt 的任意組合。
3)互動性:研究引入了透過結合可學習的記憶(memory) prompt,並透過遮罩指導的交叉注意力保留對話歷史資訊。
4)語意知覺能力:使用文字編碼器對文字查詢和遮罩標籤進行編碼,從而為所有輸出分割結果提供了開放集語意。

架構方面,SEEM 遵循一個簡單的Transformer 編碼器- 解碼器架構,並額外添加了一個文字編碼器。在 SEEM 中,解碼過程類似於生成式 LLM,但具有多模態輸入和多模態輸出。所有查詢都作為 prompt 反饋到解碼器,圖像和文字編碼器用作 prompt 編碼器來編碼所有類型的查詢。
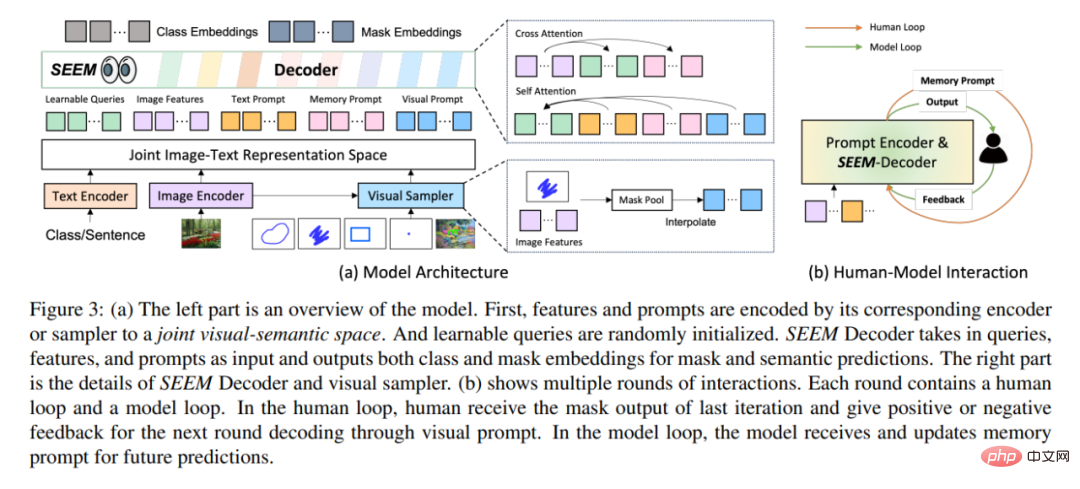
具體來說,研究將所有查詢(如點、框和遮罩)編碼為視覺prompt,同時使用文字編碼器將文字查詢轉換為文字prompt,這樣視覺和文字prompt 就能保持對齊。 5 種不同類型的 prompt 都能都映射到聯合視覺語義空間中,透過零樣本適應來處理未見過的使用者 prompt。透過對不同的分割任務進行訓練,模型具有處理各種 prompt 的能力。此外,不同類型的 prompt 可以藉助交叉注意力互相輔助。最終,SEEM 模型可以使用各種 prompt 來獲得卓越的分割結果。
除了強大的泛化能力,SEEM 在運作方面也很有效率。研究人員將 prompt 作為解碼器的輸入,因此在與人類進行多輪互動時,SEEM 只需要在最開始運行一次特徵提取器。在每次迭代中,只需要使用新的 prompt 再次運行輕量級的解碼器。因此,在部署模型時,參數量大運行負擔重的特徵提取器可以在伺服器上運行,而在用戶的機器上僅運行相對輕量級的解碼器,以緩解多次遠端呼叫中的網路延遲問題。
如上圖 3(b)所示,在多輪互動中,每次互動包含一個人工循環和一個模型循環。在人工循環中,人們接收上一次迭代的遮罩輸出,並透過視覺 prompt 給予下一輪解碼的正回饋或負回饋。在模型循環中,模型接收並更新記憶 prompt 以供未來的預測。
該研究將 SEEM 模型與 SOTA 互動式分割模型進行了實驗比較,結果如下表 1 所示。
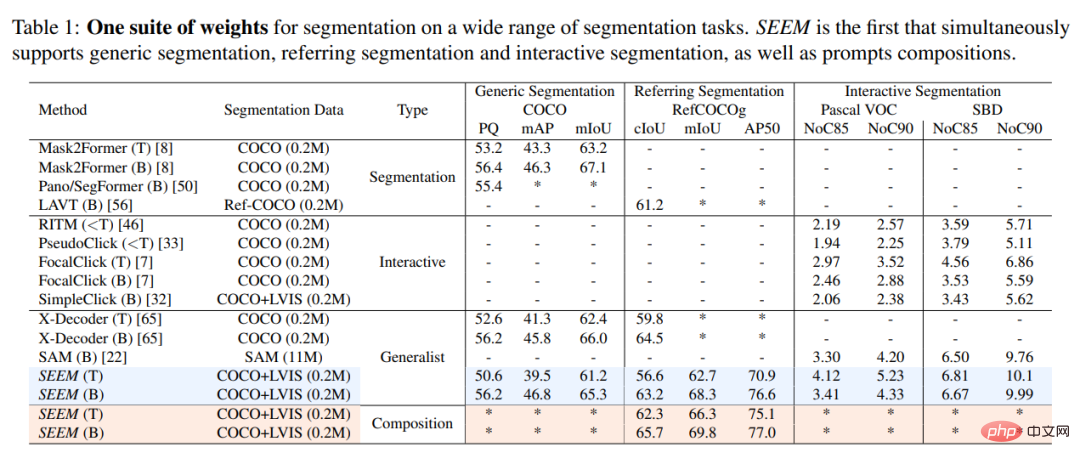
作為通用模型,SEEM 實作了與RITM,SimpleClick 等模型相當的效能,並且與SAM 的效能非常接近,而SAM 用於訓練的分割資料是SEEM 的50 倍之多。
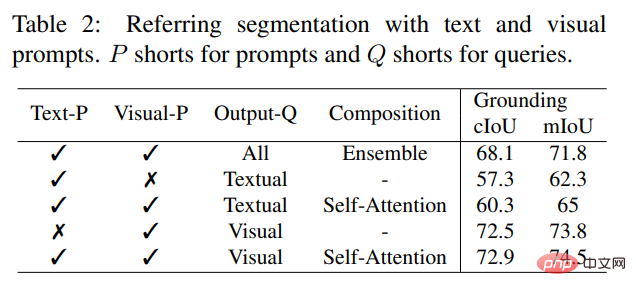
與現有的互動式模型不同,SEEM 是第一個不僅支援經典分割任務,還支援各種使用者輸入類型的通用接口,包括文字、點、塗鴉、框和圖像,提供強大的組合功能。如下表 2 所示,透過添加可組合的 prompt,SEEM 在 cIoU,mIoU 等指標上有了顯著的分割效能提升。
我們再來看看互動式影像分割的視覺化結果。使用者只需要畫出一個點或簡單塗鴉,SEEM 就能提供非常好的分割結果

#也可以輸入文本,讓SEEM 進行圖像分割

也能直接輸入參考影像並指出參考區域,對其他影像進行分割,找出與參考區域一致的物件:

該專案已經可以線上試玩,有興趣的讀者快去試試吧。
以上是華人團隊打造的通用分割模型SEEM,將一次性分割推向新高度的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















