

如果人工智慧可以解讀你的想像,將你腦海中的圖像變成現實,那會怎麼樣?

雖然這聽起來有點賽博龐克。但最近發表的一篇論文,讓 AI 圈吵翻了天。
這篇論文發現,他們使用最近非常火辣的Stable Diffusion,就能重建大腦活動中的高分辨率、高精準影像。作者寫道,與先前的研究不同,他們不需要訓練或微調人工智慧模型來創建這些圖像。

他們是怎麼做到的呢?
在本研究中,作者基於 Stable Diffusion 來重建透過功能性磁振造影 (fMRI) 而獲得的人腦活動影像。作者也表示,透過研究與大腦相關功能的不同組成部分(例如圖像 Z 的潛在向量等),也有助於了解隱擴散模型的機制。
這篇論文也已經被 CVPR 2023 接收。
該研究的主要貢獻包括:
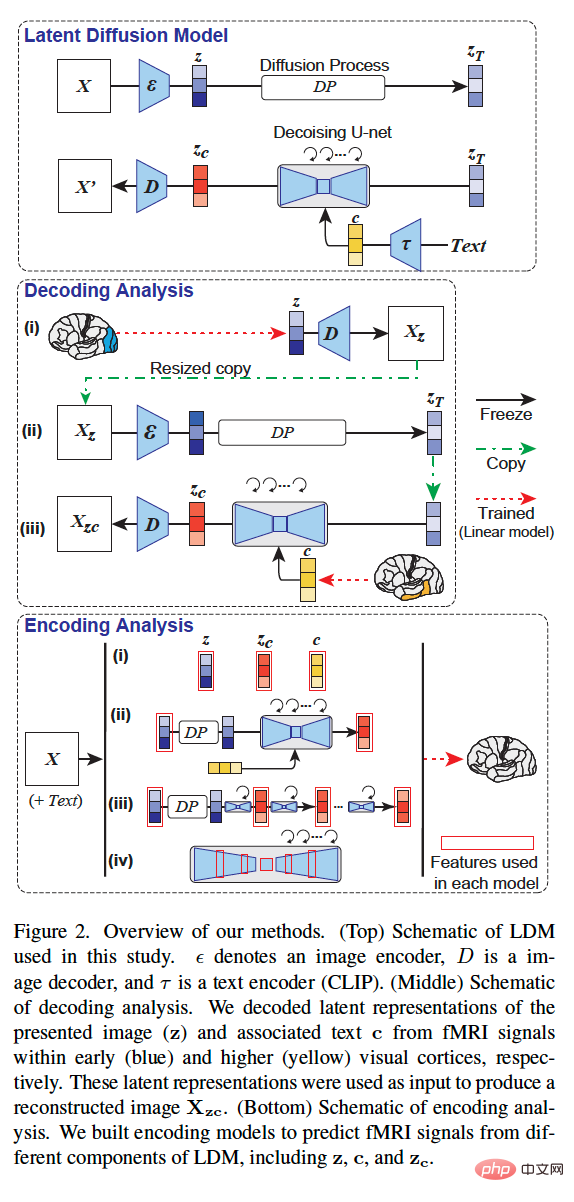
該研究的整體方法如下圖 2 所示。圖 2(上)是該研究中使用的 LDM 示意圖,其中,ε 表示圖像編碼器,D 表示圖像解碼器,τ 表示文字編碼器(CLIP)。
圖 2(中)是本研究的解碼分析示意圖。研究者分別從早期(藍色)和高級(黃色)視覺皮層內的 fMRI 訊號中解碼了呈現圖像 (z) 和相關文本 c 的潛在表徵。這些潛在表徵被用作產生重建影像 X_zc 的輸入。
圖 2(下)是本研究的編碼分析示意圖。研究者建構了編碼模型來預測來自 LDM 不同組成部分的 fMRI 訊號,包括 z、c 和 z_c。
有關 Stable Diffusion 這裡就不做太多介紹,相信很多人比較了解。
我們來看看該研究的視覺重建結果。
解碼
#下圖 3 展示了一個主體(subj01)的視覺重建結果。研究者為每個測試影像產生了五個影像,並選擇了具有最高 PSM 的影像。一方面,只用 z 重建的圖像在視覺上與原始圖像一致,但未能抓住其語義內容。另一方面,只用 c 重建的圖像產生的圖像具有很高的語義保真度,但在視覺上卻不一致。最後,使用 z_c 重建的影像可以產生具有高語義保真度的高解析度影像。

圖4 展示了所有測試者對相同影像的重建影像(所有影像都是用z_c 產生的) 。整體來說,各測試者的重建品質是穩定且準確的。

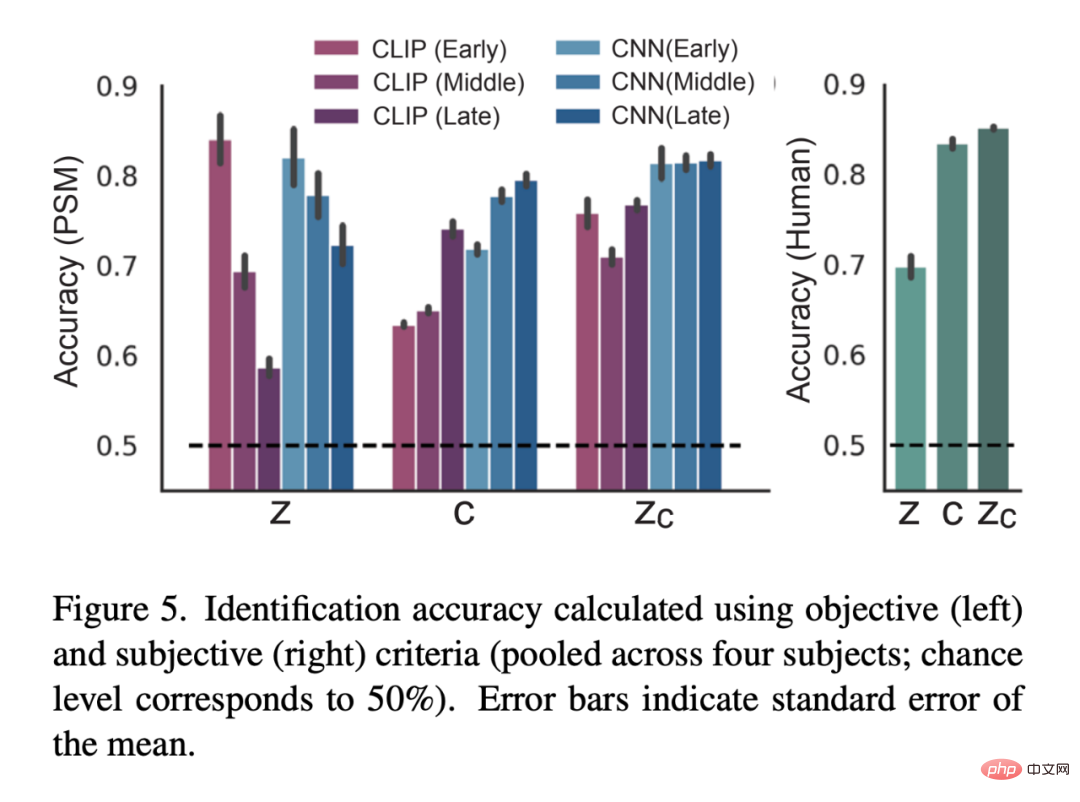
#圖5 是量化評估的結果:
#編碼模型
#圖6 顯示了編碼模型對與LDM 相關的三種潛像的預測精度:z,原始圖像的潛像;c,圖像文本註釋的潛像;以及z_c,經過與c 交叉注意力反向擴散過程後的z 的加噪潛像表徵。
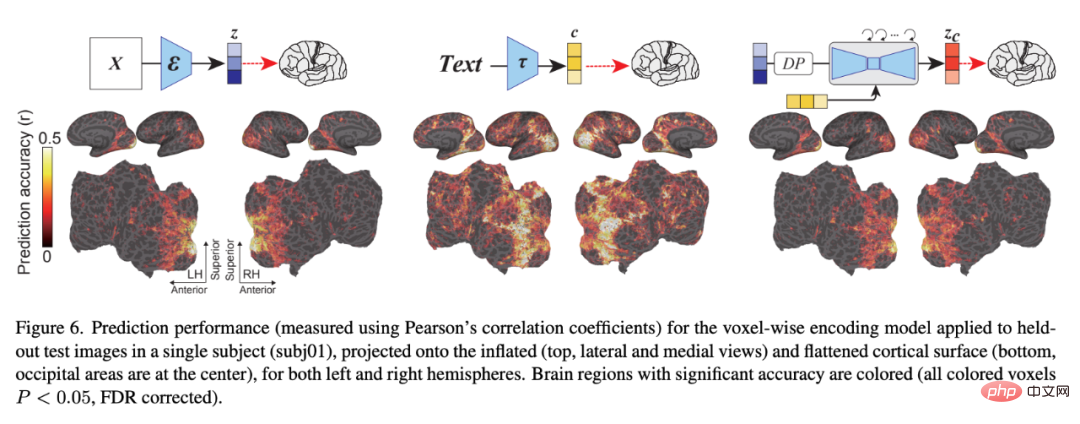
圖 7 顯示,當加入少量的雜訊時,z 對整個皮質的體素活動的預測比 z_c 更好。有趣的是,當增加噪音水平時,z_c 對高位視覺皮層內體素活動的預測優於 z,這表明圖像的語義內容逐漸被強調。

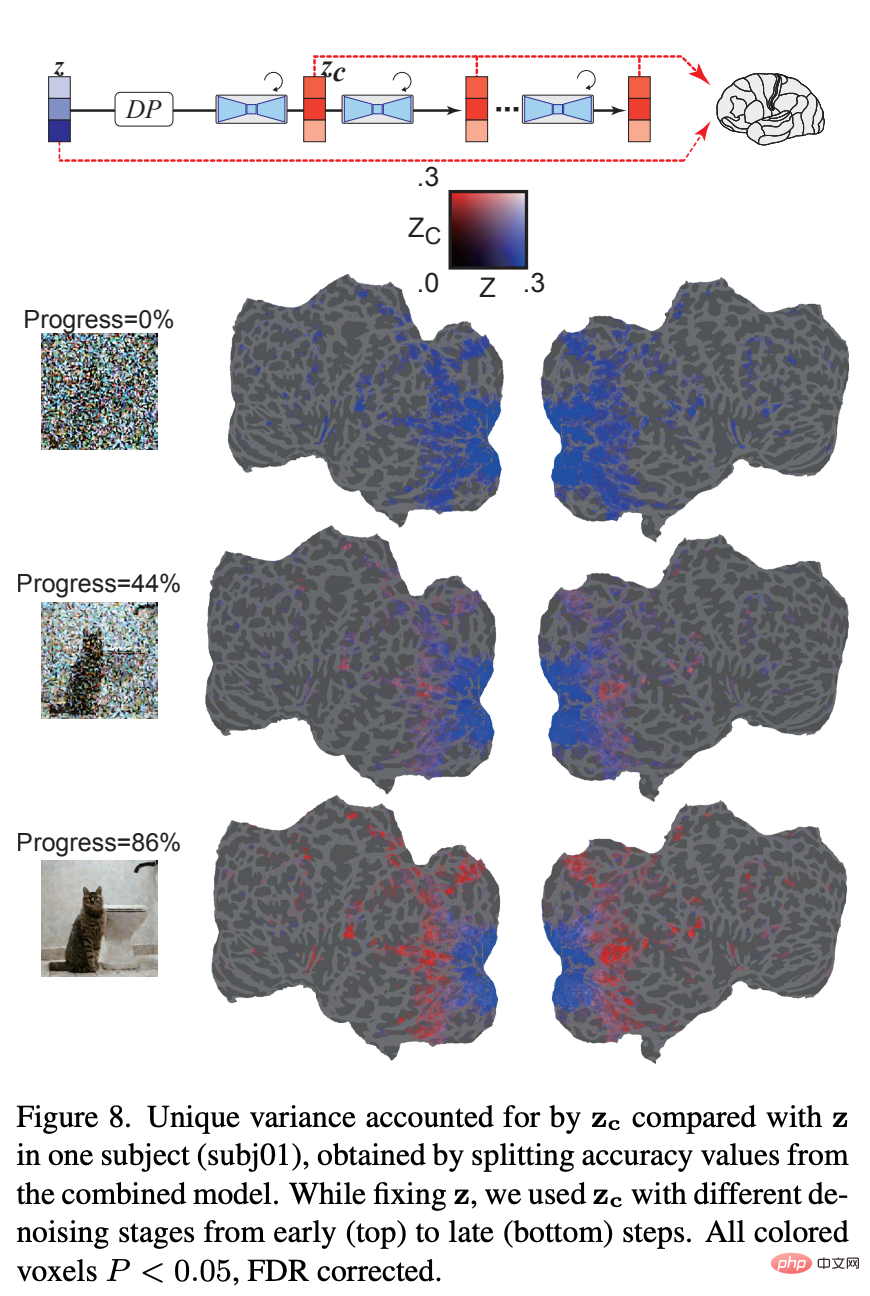
在迭代去噪過程中,加入雜訊的潛在表徵如何改變?圖 8 顯示,在去雜訊過程的早期階段,z 訊號主導了 fMRI 訊號的預測。在去噪過程的中間階段,z_c 對高位視覺皮層內活動的預測比 z 好得多,表明大部分語義內容在這個階段出現了。結果顯示了 LDM 如何從雜訊中提煉和生成影像。
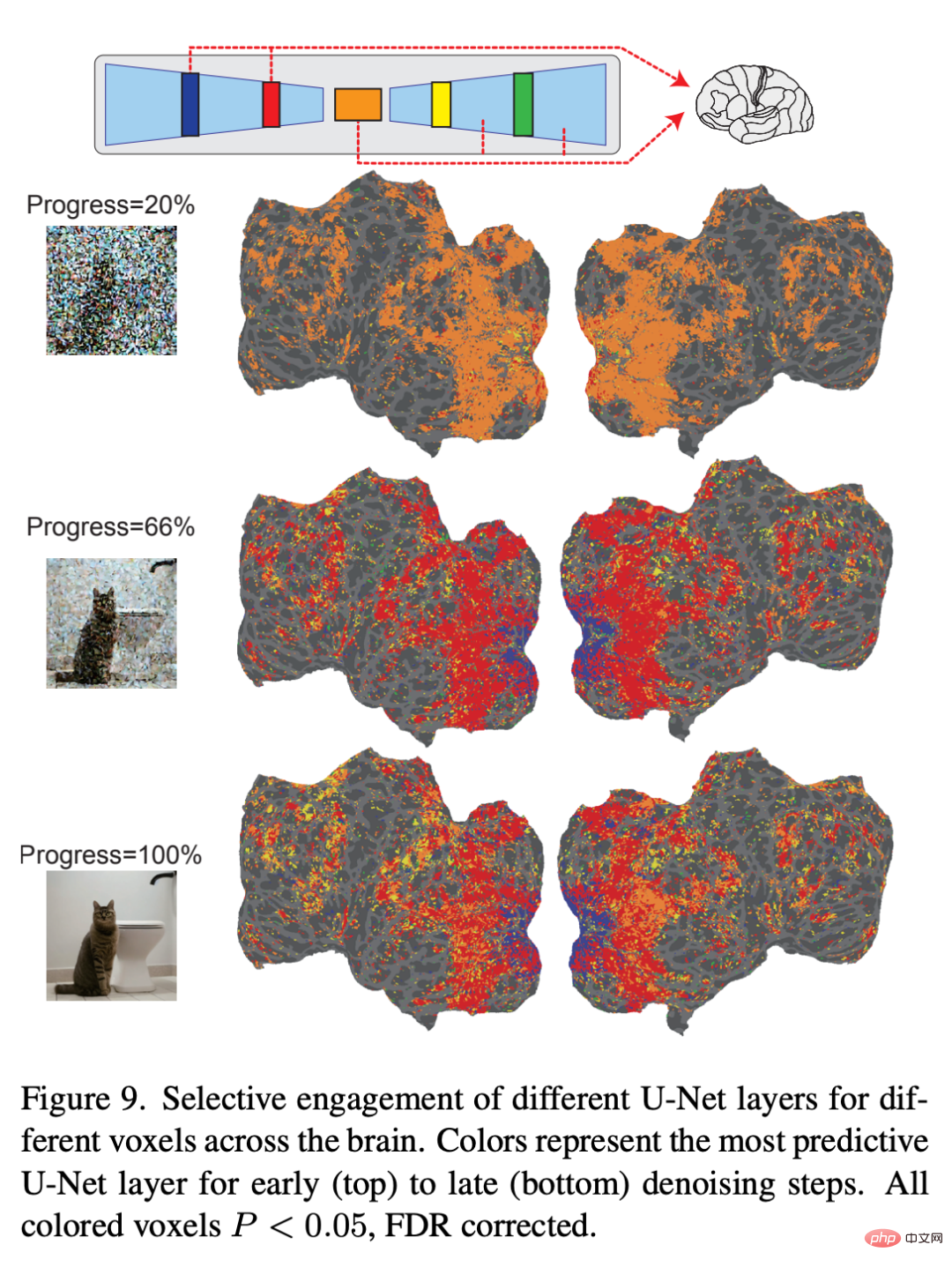
最後,研究者探討了 U-Net 的每一層都在處理什麼資訊。圖 9 顯示了去雜訊過程的不同步驟(早期、中期、晚期)以及 U-Net 不同層的編碼模型的結果。在去噪過程的早期階段,U-Net 的瓶頸層(橘色)在整個皮質中產生了最高的預測效能。然而,隨著去噪的進行,U-Net 的早期層(藍色)預測早期視覺皮層內的活動,而瓶頸層則轉向對更高的視覺皮層的卓越預測能力。
更多研究細節,可查看原始論文。
以上是'使用Stable Diffusion技術重現影像,相關研究被CVPR會議接受'的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















