

多模態學習旨在理解和分析來自多種模態的信息,近年來在監督機制方面取得了實質進展。
然而,對資料的嚴重依賴加上昂貴的人工標註阻礙了模型的擴展。同時,考慮到現實世界中大規模的未標註資料的可用性,自監督學習已經成為緩解標註瓶頸的一種有吸引力的策略。
基於這兩個方向,自監督多模態學習(SSML)提供了從原始多模態資料中利用監督的方法。

論文網址:https ://arxiv.org/abs/2304.01008
專案網址:https://github. com/ys-zong/awesome-self-supervised-multimodal-learning
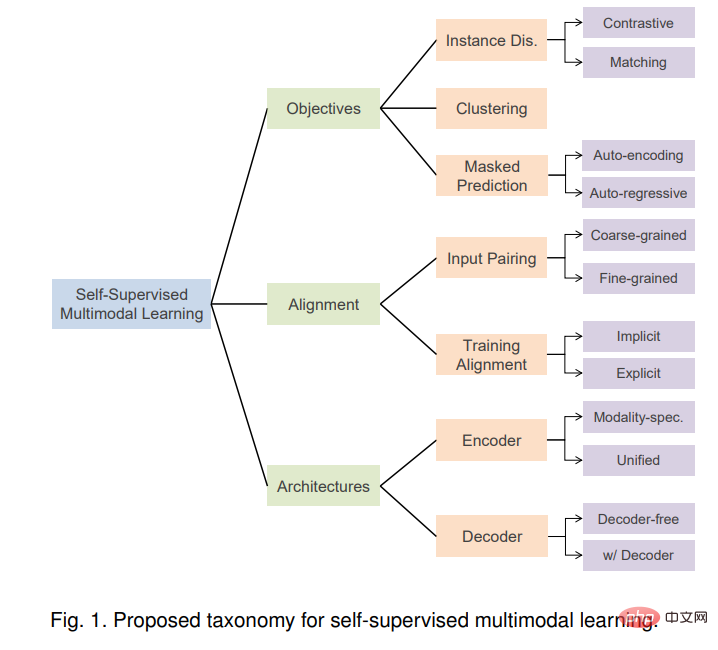
在本綜述中,我們對SSML的最先進技術進行了全面的回顧,我們沿著三個正交的軸進行分類: 目標函數、資料對齊和模型架構。 這些座標軸對應於自監督學習方法和多模態資料的固有特徵。
具體來說,我們將訓練目標分為實例判別、聚類和遮罩預測類別。我們也討論了訓練期間的多模態輸入資料配對和對齊策略。最後,回顧了模型架構,包括編碼器、融合模組和解碼器的設計,這些都是SSML方法的重要組成部分。
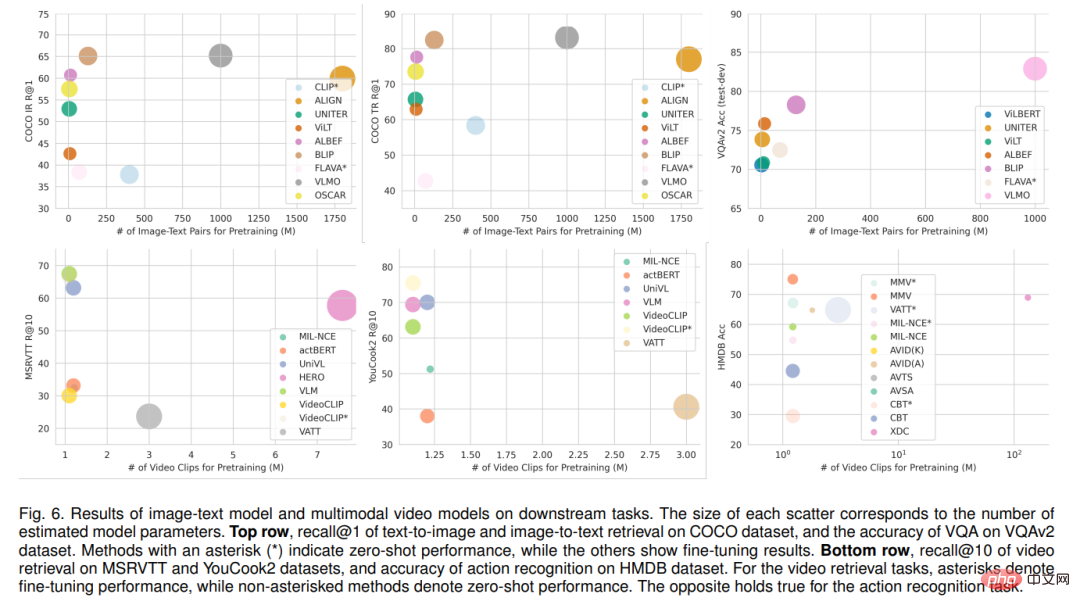
回顧了下游的多模態應用任務,報告了最先進的圖像-文字模型和多模態視訊模型的具體性能,也回顧了SSML演算法在不同領域的實際應用,如醫療保健、遙感和機器翻譯。最後,討論了SSML面臨的挑戰和未來的方向。
人類別透過各種感官來感知世界,包括視覺、聽覺、觸覺和嗅覺。我們透過利用每個模態的互補資訊來全面了解我們的周圍環境。 AI研究一直致力於開發模仿人類行為並以類似方式理解世界的智能體。為此,多模態機器學習領域[1]、[2]旨在開發能夠處理和整合來自多個不同模態的資料的模型。近年來,多模態學習取得了重大進展,導致了視覺和語言學習[3]、視訊理解[4]、[5]、生物醫學[6]、自動駕駛[7]等領域的一系列應用。更根本的是,多模態學習正在推動人工智慧中長期存在的接地問題[8],使我們更接近更一般的人工智慧。
然而,多模態演算法往往仍然需要昂貴的人工標註才能進行有效的訓練,這阻礙了它們的擴展。最近,自監督學習(SSL)[9],[10]已經開始透過從現成的標註資料產生監督來緩解這個問題。單模態學習中自監督的定義相當完善,僅取決於訓練目標,以及是否利用人工標註進行監督。然而,在多模態學習的脈絡下,它的定義則更為微妙。在多模態學習中,一種模態經常充當另一種模態的監督訊號。就消除人工標註瓶頸進行向上擴展的目標而言,定義自我監督範圍的關鍵問題是跨模態配對是否自由取得。
透過利用免費可用的多模態資料和自監督目標,自監督多模態學習(SSML)顯著增強了多模態模型的能力。 在本綜述中,我們回顧了SSML演算法及其應用。我們沿著三個正交的軸分解各種方法:目標函數、資料對齊和模型架構。 這些座標軸對應於自監督學習演算法的特徵和多模態資料所需的具體考慮。圖1提供了擬議分類法的概述。基於前置任務,我們將訓練目標分為實例判別、聚類和遮罩預測類別。也討論了將這些方法中的兩種或兩種以上結合起來的混合方法。
多模態自監督特有的是多模態資料配對的問題。 模態之間的配對,或更一般的對齊,可以被SSML演算法利用作為輸入(例如,當使用一種模態為另一種模態提供監督時),但也可以作為輸出(例如,從未配對的數據中學習並將配對作為副產品誘導)。我們討論了對齊在粗粒度上的不同作用,這種粗粒度通常被假定在多模態自監督中免費可用(例如,網絡爬取的圖像和標題[11]);有時由SSML演算法顯式或隱式誘導的細粒度對齊(例如,標題詞和圖像塊[12]之間的對應關係)。此外,我們探索了目標函數和資料對齊假設的交集。
也分析了當代SSML模型架構的設計。 具體來說,我們考慮編碼器和融合模組的設計空間,將特定模式的編碼器(沒有融合或具有後期融合)和具有早期融合的統一編碼器進行對比。我們也檢查具有特定解碼器設計的架構,並討論這些設計選擇的影響。
最後,討論了這些演算法在多個真實世界領域的應用,包括醫療保健、遙感、機器翻譯等,並對SSML的技術挑戰和社會影響進行了深入討論,指出了潛在的未來研究方向。我們總結了在方法、資料集和實現方面的最新進展,為該領域的研究人員和從業人員提供一個起點。
現有的綜述論文要麼只關注有監督的多模態學習[1],[2],[13],[14],或單模態自監督學習[9],[10],[15],或SSML的某個子區域,例如視覺-語言預訓練[16]。 最相關的綜述是[17],但它更側重於時間數據,忽略了對齊和架構的多模態自監督的關鍵考慮因素。相較之下,我們提供了一個全面且最新的SSML演算法綜述,並提供了一個涵蓋演算法、資料和架構的新分類法。
#多模態學習中的自監督
我們首先描述了本次研究中所考慮的SSML的範圍,因為這個術語在先前的文獻中使用不一致。透過呼叫不同藉口任務的無標籤性質,在單模態環境中定義自監督更為直接,例如,著名的實例辨別[20]或掩蓋預測目標[21]實現了自我監督。相較之下,多模態學習中的情況則更加複雜,因為模態和標籤的作用變得模糊。例如,在監督圖像字幕[22]中,文字通常被視為標籤,但在自監督多模態視覺和語言表示學習[11]中,文字則被視為輸入模態。
在多模態環境中,自監督一詞已被用來指至少四種情況:(1)從自動成對的多模態資料中進行無標籤學習— —例如有視訊和音訊軌道的影片[23],或來自RGBD攝影機[24]的影像和深度資料。 (2)從多模態資料中學習,其中一個模態已經被手動標註,或者兩個模態已經被手動配對,但這個標註已經為不同的目的創建,因此可以被認為是免費的,用於SSML預訓練。例如,從網路爬取的匹配圖像-標題對,如開創性的CLIP[11]所使用的,實際上是監督度量學習[25],[26]的一個例子,其中配對是監督。然而,由於模式和配對都是大規模免費提供的,因此它通常被描述為自監督的。這種未經策劃的偶然創建的數據通常比專門策劃的數據集(如COCO[22]和Visual Genome[27])質量更低,而且噪音更大。 (3)從高品質的目的標註的多模態資料(例如,COCO[22]中的手動字幕影像)中學習,但具有自監督的風格目標,例如Pixel-BERT[28]。 (4)最後,還有一些「自監督」方法,它們混合使用免費和手動標註的多模態資料[29],[30]。為了本次調查的目的,我們遵循自監督的思想,旨在透過打破手動標註的瓶頸來擴大規模。因此,就能夠在免費可用的資料上進行訓練而言,我們包括了前面兩類和第四類方法。我們排除了僅顯示用於手動管理資料集的方法,因為它們在管理資料集上應用典型的「自監督」目標(例如,屏蔽預測)。
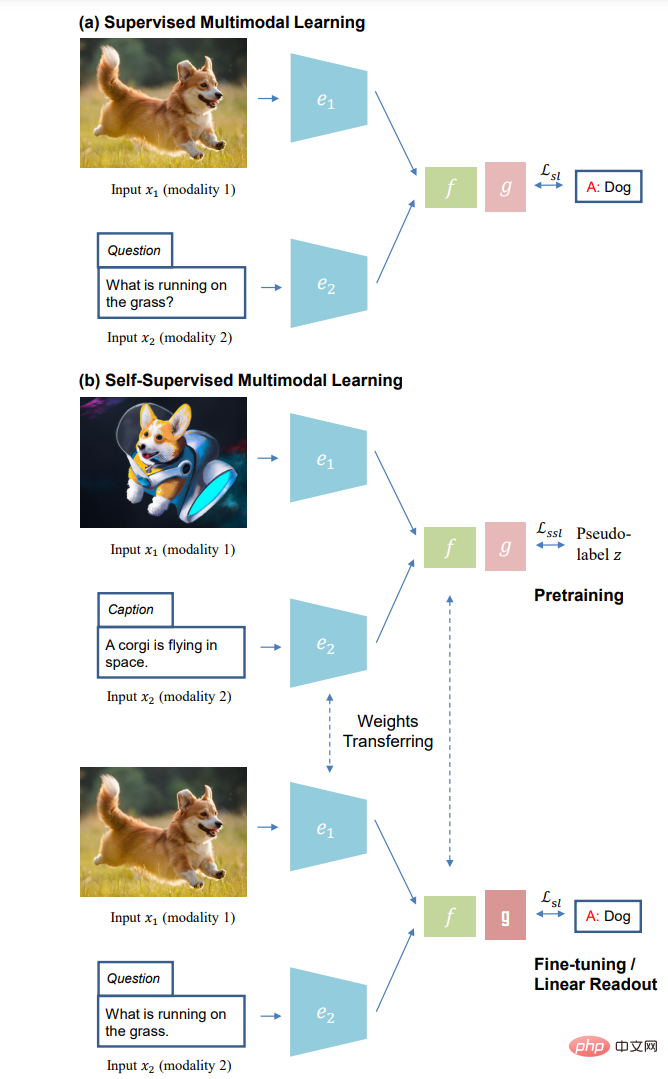
(a)監督式多模態學習和(b)自監督式多模態學習的學習範式:無手動標註的自監督預訓練(上);對下游任務進行監督微調(下)。
在本節中,我們將介紹用於訓練三類自監督多模態演算法的目標函數:實例判別、聚類和掩蓋預測。最後我們也討論了混合目標。
3.1 實例判別
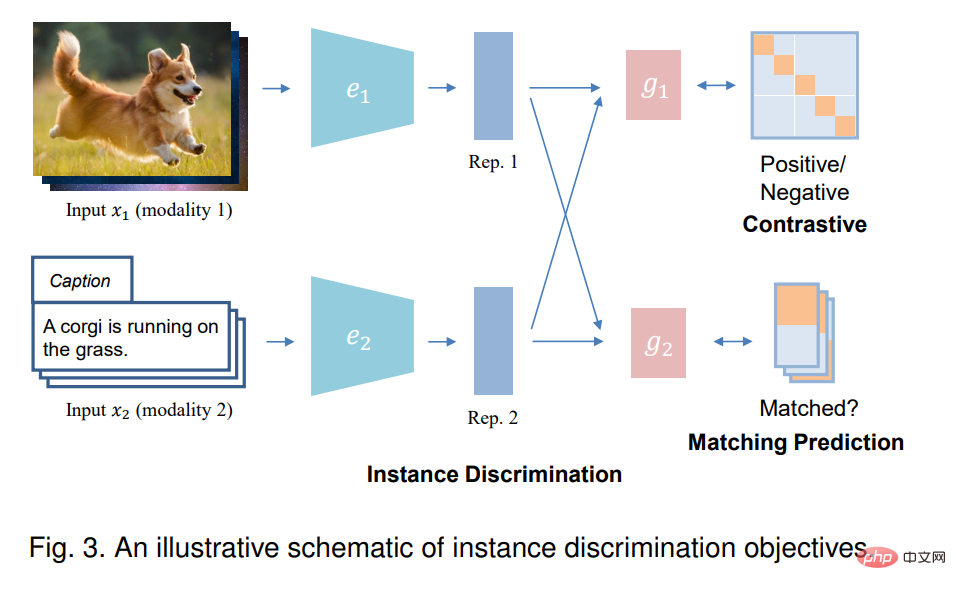
#在單模學習中,實例判別(instance discrimination, ID)將原始數據中的每個實例視為一個單獨的類,並對模型進行訓練,以區分不同的實例。在多模態學習的背景下,實例判別通常旨在確定來自兩個輸入模態的樣本是否來自同一個實例,即配對。透過這樣做,它試圖對齊成對模式的表示空間,同時將不同實例對的表示空間推得更遠。有兩種類型的實例識別目標:對比預測和匹配預測,這取決於輸入是如何採樣的。
3.2 聚類
聚類方法假設應用經過訓練的端到端聚類將導致根據語義顯著特徵對資料進行分組。在實踐中,這些方法迭代地預測編碼表示的聚類分配,並使用這些預測(也稱為偽標籤)作為監督訊號來更新特徵表示。多模態聚類提供了學習多模態表示的機會,也透過使用每個模態的偽標籤監督其他模態來改進傳統聚類。
3.3 遮罩預測
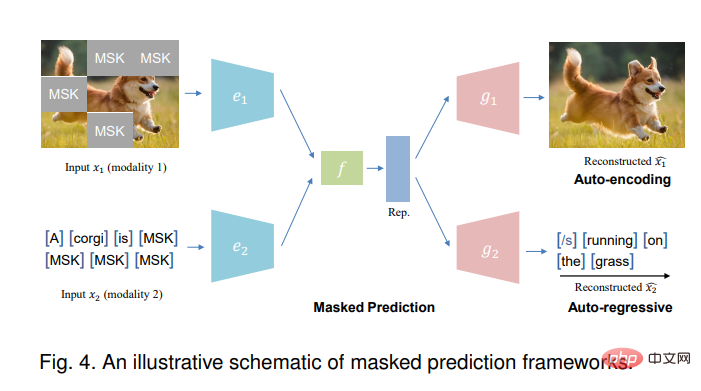
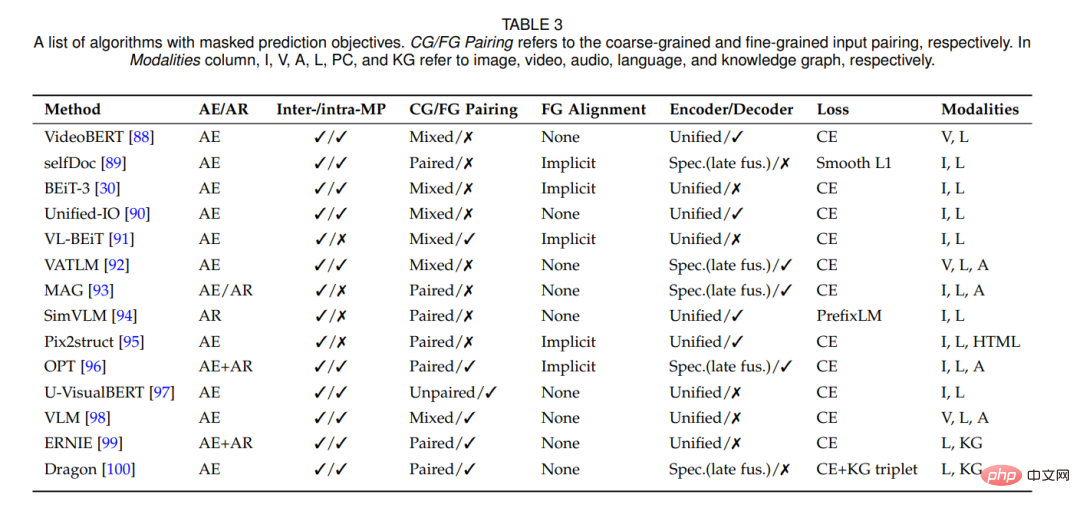
#遮罩預測任務可以採用自動編碼(類似BERT[101])或自動迴歸方法(類似GPT[102])來執行。
以上是多模態自監督學習:探討目標函數、資料對齊和模型架構-以愛丁堡最新綜述為例的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































