

作者| 崔皓
審查| 重樓
#一次革命性的技術升級,ChatGPT 4.0的發布震動了整個AI產業。現在,不僅可以讓電腦識別並回答日常的自然語言問題,ChatGPT還可以透過對產業數據建模,提供更準確的解決方案。本文將帶您深入了解ChatGPT的架構原理及其#發展前景,同時介紹如何使用ChatGPT的API訓練產業資料。讓我們一起探索這個嶄新且極具前途的領域,開創一個新的AI時代。
ChatGPT 4.0 已經正式發布了!這一版本的 ChatGPT 引入了跨越式革新,與先前的 ChatGPT 3.5 相比,它在模型的性能和速度方面都有了巨大的提升##。在ChatGPT 4.0發布之前,許多人已經關注過ChatGPT,並意識到它在自然語言處理領域的重要性。然而,在3.5以及先前的版本,ChatGPT的限制仍然存在,因為它的訓練資料主要集中在通用領域在語言模型中,難以產生與特定產業相關的內容。但是,隨著ChatGPT 4.0的發布,越來越多的人已經開始使用它來訓練自己的行業數據,並被廣泛應用於各個行業。這使得越來越多的人從關注到使用 ChatGPT。接下來,我將為您介紹 ChatGPT 的架構原理、發展前景以及在訓練產業資料方面的應用。
ChatGPT 的能力##ChatGPT的架構基於深度學習神經網絡,是一種自然語言處理技術,其原理是使用預先訓練的大型語言模型來產生文本,使得機器可以理解和生成自然語言。 ChatGPT的模型原理基於Transformer網絡,使用無監督的語言建模技術進行訓練,預測下一個單字的機率分佈,以產生連續的文字。使用參數包括網路的層數、每層的神經元數、Dropout機率、Batch Size等。學習的範圍涉及了通用的語言模型,以及特定領域的語言模型。通用領域的模型可以用於產生各種文本,而特定領域的模型則可以根據具體的任務進行微調和最佳化。
OpenAI利用了海量的文字資料作為GPT-3的訓練資料。具體來說,他們使用了超過45TB的英文文字資料和一些其他語言的數據,其中包括了網頁文字、電子書、百科全書、維基百科、論壇、部落格等等。他們也使用了一些非常大的資料集,例如Common Crawl、WebText、BooksCorpus等等。這些資料集包含了數萬億個單字和數十億個不同的句子,為模型的訓練提供了非常豐富的資訊。
既然要學習這麼多的內容,所使用的算力也是相當可觀的。ChatGPT花費的算力較高,需要大量的GPU資源來訓練。根據OpenAI在2020年的技術報告中介紹,GPT-3在訓練時耗費了約175億個參數和28500個TPU v3處理器。
從上面的介紹,##我們知道了ChatGPT具有強大的能力,同時也需要一個龐大的運算和資源消耗,訓練這個##大型語言模型需要花費高成本。但花費了這樣高昂的成本生產出來的AIGC工具存在其限制,對某些專業領域的知識它並沒有涉足。例如,當涉及醫療或法律等專業領域時,ChatGPT就無法產生準確的答案。這是因為ChatGPT的學習資料來自網路上的通用語料庫,這些資料並不包括某些特定領域的專業術語和知識。因此,要讓ChatGPT在某些專業領域有較好的表現,需要使用該領域的專業語料庫進行訓練,也就是說將專業領域專家的知識「教導」ChatGPT進行學習。
但是,ChatGPT並沒有讓我們失望。如果將ChatGPT應用到某個產業中,需要先將該產業的專業資料提取出來,並進行預處理。具體來說,需要對資料進行清洗、去重、切分、標註等一系列處理。之後,將處理後的資料進行格式化,將其轉換為符合ChatGPT模型輸入要求的資料格式。然後,可以利用ChatGPT的API接口,將處理後的資料輸入到模型中進行訓練。訓練的時間和花費取決於資料量和算力大小。訓練完成後,可以將模型應用到實際場景中,用於回答使用者的問題。#使用ChatGPT訓練專業領域知識!
其實建立專業領域的知識庫並不難,具體操作##就是將產業資料轉換為問答格式,然後將問答的格式透過自然語言處理(NLP)技術進行建模,從而回答問題。使用OpenAI的GPT-3 API#(以GPT3為例)可以建立一個問答模型,只需提供一些範例,它就可以根據您提供的問題產生答案。
#使用GPT-3 API建立問答模型的大致步驟如下:#

#整個過程需要呼叫OpenAI,它提供不同類型的API訂閱計劃,包括Developer、Production和Custom等計劃。每個計劃都提供不同的功能和API存取權限,並且有不同的價格。因為並不是本文的重點,這裡不展開說明。
建立資料集#從上面的操作步驟來看,第2步驟轉換為問答格式對我們來說是一個挑戰。
#假設##有##關於人工智慧的歷史的領域知識需要教導GPT,#並將這些知識轉化為回答相關問題的模型。那就要轉換成如下的形式:
############# #####
|
##當然整理成這樣問答的形式還不夠,需要形成GPT能夠理解的格式,如下所示
|
其實就是在問題後面加上了「\n\n」,而在答案後面加上了「##\n#」。
快速產生問答格式的模型解決了問答格式問題,新的問題又來了,我們要如何將業界的知識都整理成問答的模式呢?多數情況,我們從網路上爬取大量的領域知識,或找一大堆的領域文檔,不管是哪種情況,輸入文檔對於我們來說是最方便的。但是將大量的文字處理成問答的形式,使用正規表示式或人工的方式顯然是不切實際的。
#因此就需要引入##一種叫做自動摘要(Automatic Summarization)的技術,它可以從一篇文章中提取關鍵訊息,並產生一個簡短的摘要。
# 自動摘要有兩種類型:抽取式自動摘要和產生式自動摘要。抽取式自動摘要從原始文本中抽取出最具代表性的句子來生成摘要,而生成式自動摘要則是透過模型學習從原始文本中提取重要信息,並根據此信息生成摘要。實際上,自動摘要就是將輸入的文字產生問答模式。
#問題搞清楚了接下來就是上工具了,我們使用NLTK來搞事情,NLTK是Natural Language Toolkit的縮寫,是一個Python庫,主要用於自然語言處理領域。它包括了各種處理自然語言的工具和函式庫,如文字預處理、詞性標註、命名實體辨識、文法分析、情緒分析等。
我們只需要將文字交給NLTK,它會對文字進行資料預處理操作,包括去除停用詞、分詞、詞性標註等。在預處理之後,可以使用NLTK中的文字摘要產生模組來產生摘要。可以選擇不同的演算法,例如基於詞頻、基於TF-IDF等。在產生摘要的同時,可以結合問題範本來產生問答式的摘要,使得產生的摘要更易於理解。同時也可以對摘要進行微調,例如句子連貫性不強、答案不準確等,都可以進行調整。
#來看下面的程式碼:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline ####import nltk # 輸入文字 #text = """Natural Language Toolkit(自然語言處理工具包,縮寫NLTK)是一套Python庫,用於解決人類語言資料的處理問題,例如: 分詞 ##詞性標註 ##句法分析 ##情緒分析 #語意分析 #語音辨識 #文字產生等等 #""" ## 產生摘要 #sentences = nltk.sent_tokenize(text) # 用產生的摘要進行F#ine-t#uning,得到模型 #tokenizer = AutoTokenizer.from_pretrained("t5-base ") model = AutoModelForSeq2SeqLM.from_pretrained ("t5-base") text = "summarize: " summary # 建構輸入格式 inputs = tokenizer(text, return_tensors="pt", padding=True) # 訓練模型 ##model_name = "first-model" model.save_pretrained(model_name) ## 測試模型 qa = pipeline("question-answering", model=model_name, tokenizer=model_name) context = "What is NLTK used for?" # 待解答問題 ##answer = qa(questinotallow=context, cnotallow= text["input_ids"]) | print("問題:", context)
輸出結果如下:
摘要: Natural Language Toolkit(自然語言處理工具包,縮寫NLTK)是一套Python庫,用於解決人類語言資料的處理問題,例如: - 分詞- 詞性標註##問題:NLTK # 用來做什麼的? |
上面的程式碼透過nltk.sent_tokenize方法對輸入的文字進行摘要的抽取,也就是進行問答格式化。然後,呼叫Fine-tuning的AutoModelForSeq2SeqLM.from_pretrained方法對其進行建模,##再將名為「first-model」的模型進行保存。最後呼叫訓練好的模型測試結果。
#上面不只透過##產生了問答的摘要,也需要使用F##ine-tuning的功能。 Fine-tuning是在預訓練模型基礎上,透過少量的有標籤的資料對模型進行微調,以適應特定的任務。其實就是用原來的模型裝你的資料形成你的模型,當然你也可以調整模型的內部結果,例如隱藏層的設定和參數等等。這裡我們只是使用了它最簡單的功能,可以透過下圖了解更多Fine-tuning的資訊。
 需要說明的是:AutoModelForSeq2SeqLM 類,從預訓練模型"t5-base" 載入
需要說明的是:AutoModelForSeq2SeqLM 類,從預訓練模型"t5-base" 載入
Tokenizer 和模型。AutoTokenizer 是Hugging Face Transformers 庫中的一個類,可以根據預訓練模型自動選擇並載入合適的
Tokenizer。Tokenizer 的作用是將輸入的文字編碼為模型可以理解的格式,以便後續的模型輸入。
AutoModelForSeq2SeqLM 也是 Hugging Face Transformers 庫中的一個類,可以根據預訓練模型自動選擇並載入適當的序列到序列模型。在這裡,使用的是基於T#5架構的序列到序列模型,用於產生摘要或翻譯等任務。在載入預訓練模型之後,可以使用此模型進行F#ine-tuning 或產生任務相關的輸出。
上面我們對建模程式碼進行了解釋,涉及了Fine-# #tunning和HuggingFace的部分,可能聽起來比較懵。這裡用一個例子幫助大家理解。
#假設你要做菜,雖然你已經有食材(行業知識)了,但是不知道如何做。於是你向廚師朋友請教,你告訴他你有什麼食材(產業知識)以及要做什麼菜(解決的問題),你的朋友基於他的經驗和知識(通用模型)給你提供一些建議,這個過程就是#F##ine-tuning(把產業知識放到一般模型中訓練)。你朋友的經驗與知識##就是#預先訓練的模型,你需要輸入行業知識和要解決的問題,並使用預先訓練的模型,當然可以對這個模型進行微調,例如:佐料的含量,炒菜的火候,目的就是為了解決你行業的問題。
而Hugging Face就是食譜的倉庫(程式碼中"t5-base"就是一個食譜) ,它包含了許多定義好的食譜(模型),例如:魚香肉絲、宮保雞丁、水煮肉片的做法。這些現成的食譜,可以配合我們提供食材和需要做的菜來創造出我們的食譜。我們只需要對這些食譜進行調整,然後進行訓練,就形就成了我們自己的食譜。以後,我們就可以用自己的食譜做菜了(解決業界問題)。如何選擇適合自己的模型?
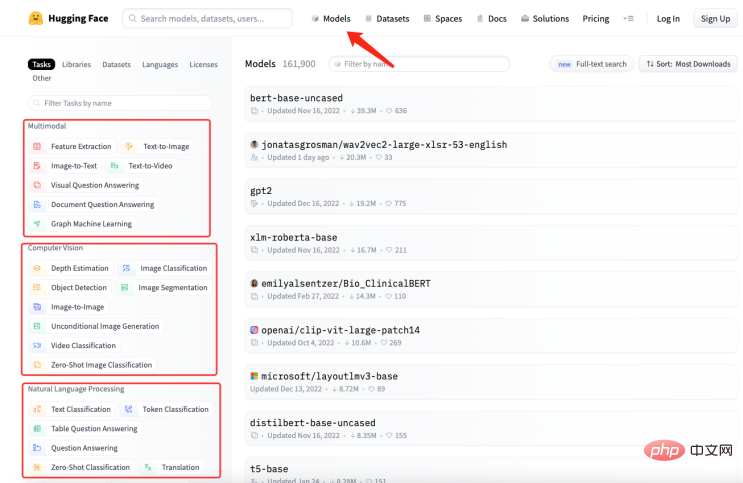
可以在 Hugging Face 的模型庫中搜尋你需要的模型。如下圖所示,在 Hugging Face 的官方網站上,點選"Models",可以看到模型的分類,同時也可以使用搜尋框搜尋模型名稱。
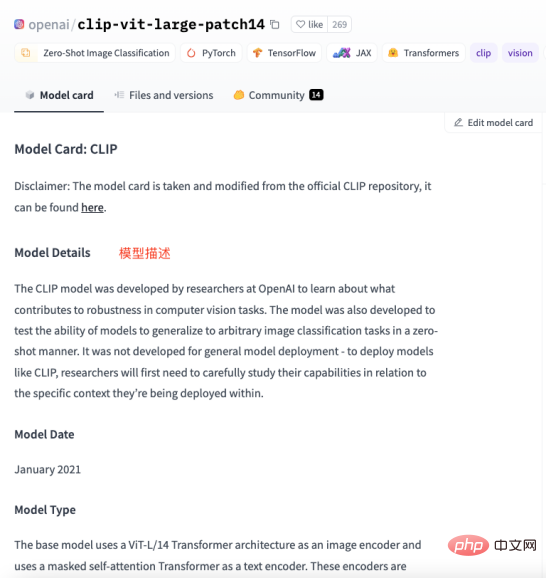
如下圖所示,每個模型頁面都會提供模型的描述、用法範例、預訓練權重下載連結等相關資訊。
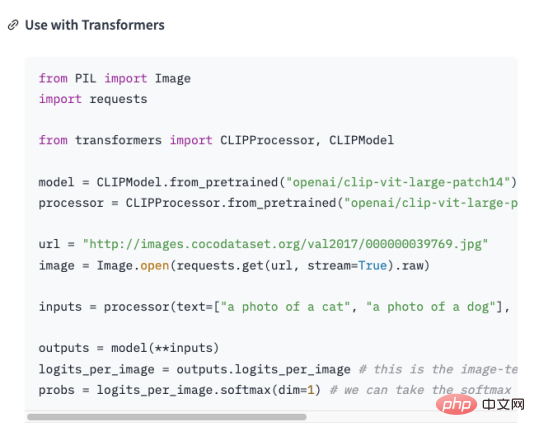
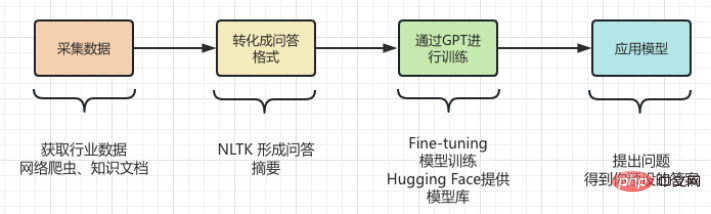
#這裡將整個產業知識從採集、轉化、訓練和使用的過程再和大家一起捋一遍。如下圖所示:
以上是20年IT老司機分享如何利用ChatGPT創建領域知識的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































