

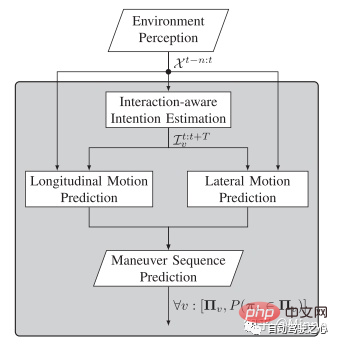
自動駕駛中,軌跡預測一般位於感知模組的後端,規則控制的前端,為承上啟動的模組。輸入為感知模組提供的目標track的state訊息、道路結構訊息,綜合考量高精地圖訊息、目標間的互動訊息,環境的語意訊息及目標的意圖訊息,對感知到的各類目標做出意圖預測(cut in/out、直行)以及未來一段時間的軌跡預測(0-5s不等)。如下圖所示。
ADAS系統需要對周遭環境資訊有一定認知能力,最基本的層次是要辨識環境,再上一層則需要理解環境,而再上一層則需要對環境進行預測。在對目標進行預測後,規控便可根據預測訊息進行自車的路徑規劃,並做出決策對可能出現的危險情況進行製動或發出告警,這便是軌跡預測模組存在的意義所在。
軌跡預測可分為短期預測與長期預測。
對於長期的軌跡預測有兩個挑戰:
影響做長期軌跡預測的不確定性主要來自三個面向:
#對軌跡預測系統應該考慮的四個問題:
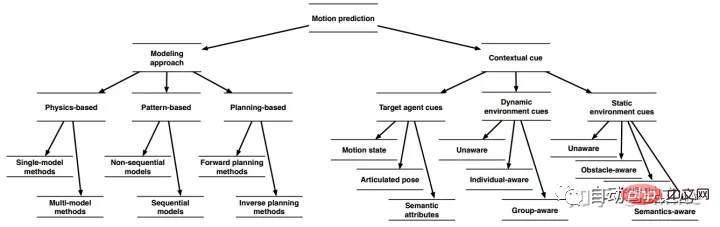
#如下圖為bosch公司發表綜述論文[2]中的分類方法。
軌跡預測具體會牽涉到哪些通用演算法呢?
那軌跡預測可以使用哪些具體資訊呢?
目前學術界軌跡預測的論文越來越多,主要原因還是業界沒有行之有效的方法。
以下列舉業界論文:
#BMW##:物理模型意圖預測(learning-based)。使用啟發式的方法整合專家知識,簡化了互動模型,在意圖預測的分類模型中加入了博弈論想法[3]。
BENZ#:主要為意圖預測的相關論文,使用的是DBN[4] 。
Uber#:LaneRCNN[5]。
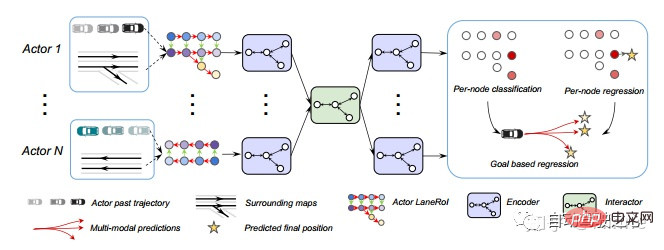
Google#:VectorNet[6]。
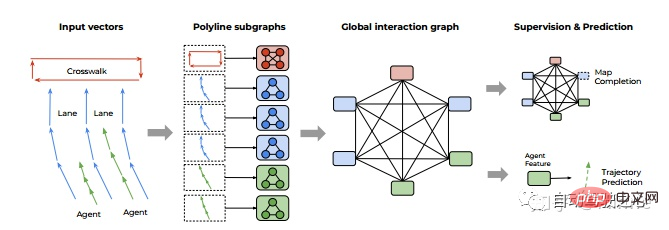
Huawei#:HOME[7]。
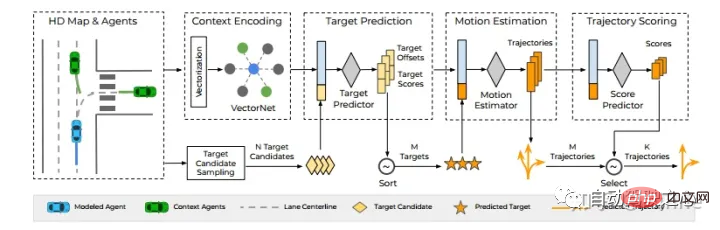
Waymo#:TNT[8]。
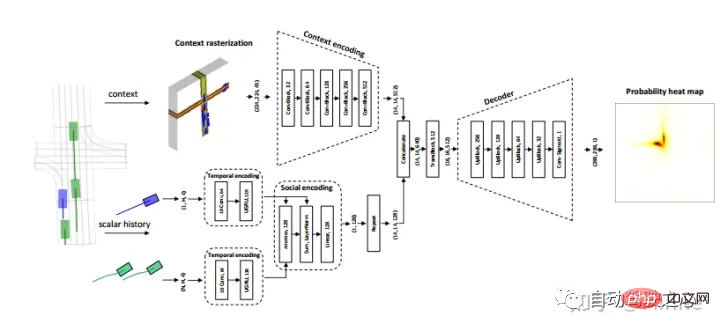
Aptive#:Covernet[9]。
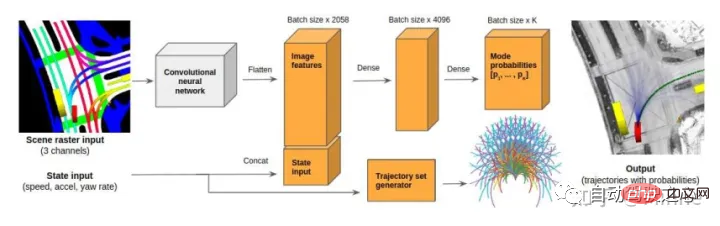
NEC#:R2P2[10]。
商湯:TPNet[11]。
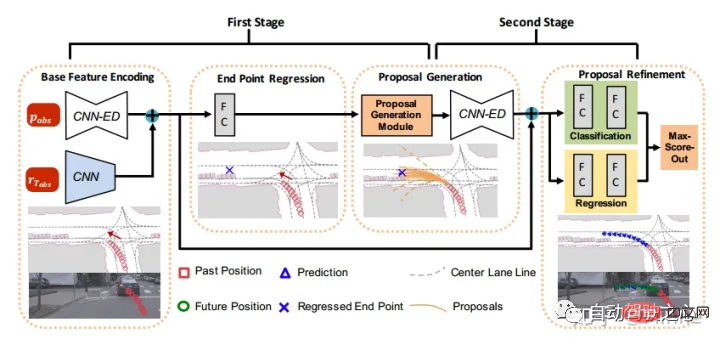
美團:StarNet[12]。行人。
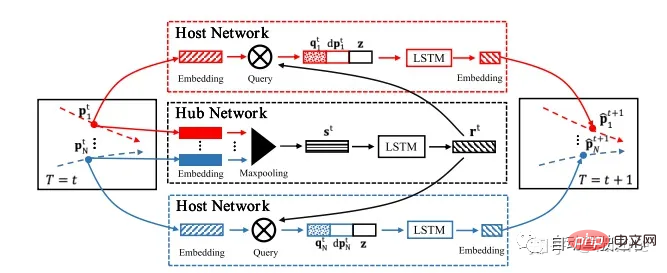
Aibee#:Sophie[13]。行人。
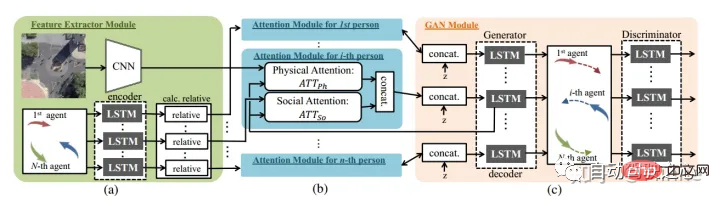
MIT#:Social lstm[14]。行人。
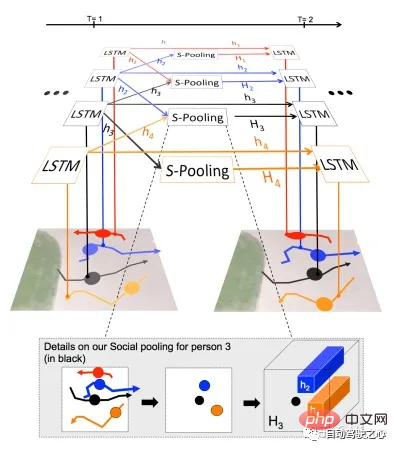
#中科大:STGAT[15]。行人。
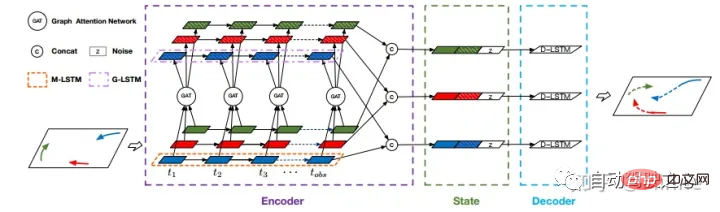
#百度#:Lane-Attention[16]。
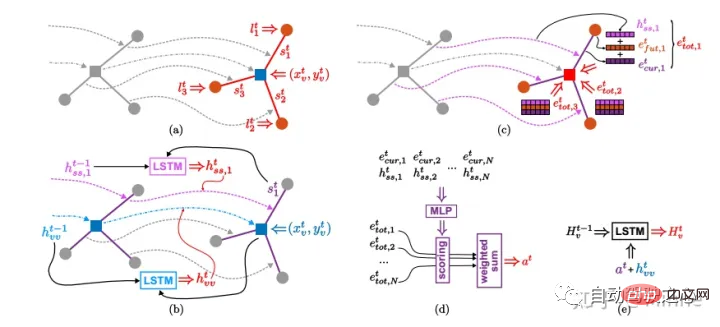
Apollo:可以看如下部落格作為參考。
https://www.cnblogs.com/liuzubing/p/11388485.html
Apollo的預測模組接收感知、定位以及地圖模組的輸入。
1.首先做了場景拆分,分為了普通巡航道路以及路口兩個場景。
2.而後對感知得到的目標做重要性劃分,分為可以忽略的目標(不會影響到自車)、需要謹慎處理的目標(可能影響到自車)以及普通目標(介於二者之間)。
3.而後進入Evaluator,本質上就是意圖預測。

4.最後進入predictor,用於預測軌跡產生。對於靜止目標、沿道行駛、freeMove、路口等不同場景做不同的操作。

#(1) NGSIM
此資料集是美國FHWA蒐集的高速公路行車數據,包括了US101、I-80等道路上的所有車輛在一個時間段的車輛行駛狀況。數據是採用攝影機獲取,然後加工成一條一條的軌跡點記錄。其資料集為CSV檔。數據沒有太多雜訊。
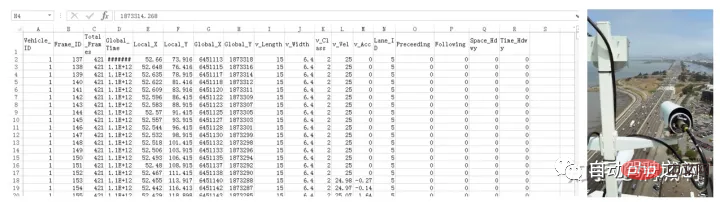
更多是整體調度層面的訊息,如道路規劃、車道設定、車流量調節等。車輛運動學狀態需要進一步抽取。處理程式碼可使用下面的github。
https://github.com/nachiket92/conv-social-pooling
(2) INTERACTION
此資料集為加州大學柏克萊分校機械系統控制實驗室(MSC Lab)與來自卡爾斯魯厄理工學院(KIT)和國立巴黎高等礦業學院(MINES ParisTech)的合作者建立了一個國際性、對抗性、協作性的資料集(INTERACTION)。它能準確重現不同國家的各種駕駛場景中道路使用者(如車輛、行人)的大量互動性行為。

http://www.interaction-dataset.com/
# (3)apolloscape
此為Apollo的公開自動駕駛資料集,其中有為軌跡預測提供的資料。內部文件為2fps的1min資料序列,資料結構包括幀數ID、目標ID、目標類別、位置xyz,長寬高資訊以及heading,其中目標類別包括小車、大車、行人、自行車/電動車以及其他。
https://apolloscape.auto/trajectory.html
(4) TRAF
此資料集聚焦於高密度的交通狀況,此狀況可以幫助演算法更好地專注於不確定環境下人類駕駛員行為分析。數據每幀分別包含約13輛機動車輛,5名行人和2輛自行車
#https://gamma.umd.edu/researchdirections/autonomousdriving/ad
在連結中有很多使用此資料集的軌跡預測項目。
(5) nuScenes
#重磅來了,此資料集是2020年4月提出。其在波士頓和新加坡這兩個城市收集了1000個駕駛場景,這兩個城市交通繁忙且駕駛狀況極具挑戰性。其數據集具有相關論文,可以看看,更好地了解此數據集。
https://arxiv.org/abs/1903.11027
此資料集中有預測相關的比賽,可以關注。

https://www.nuscenes.org/prediction?externalData=all&mapData=all&modalities=Any
目前主要使用的評估指標為幾何測量。
幾何測量有許多指標,主要使用的是ADE、FDE、MR。
ADE為均一化歐式距離。 FDE為最終預測點之間的歐式距離。 MR為未中率。有很多不同的名字,主要就是設一個閾值,預測點跡之間歐式距離低於這個預測就記為命中,高於這個閾值就記為未命中,最後計算一個百分比。
幾何測量是衡量預測軌跡與實際軌跡相似性的重要指標,可以很好是代表精確度。但是以軌跡預測存在的意義來說,僅僅評估精確度是沒有意義的。也應有機率度量,用來評估不確定性,尤其是對於多模態輸出分佈;還有任務層面度量,魯棒性的度量以及效率的評估這些。
機率測量:可以使用KL散度、預測機率、累積機率來作為機率度量。如NLL, KDE-based NLL[17]。任務層度量:評估軌跡預測對後端規控的影響(piADE,piFDE)[18]。穩健性:要考慮在預測之前,觀測到的部分軌跡的長度或持續時間;訓練資料的size;輸入資料取樣頻率和感測器雜訊;神經網路泛化、過度擬合及輸入利用率分析;感知模組送入的輸入如果有問題是否保證功能正常等等方面的因素。效率:要考慮算力的。
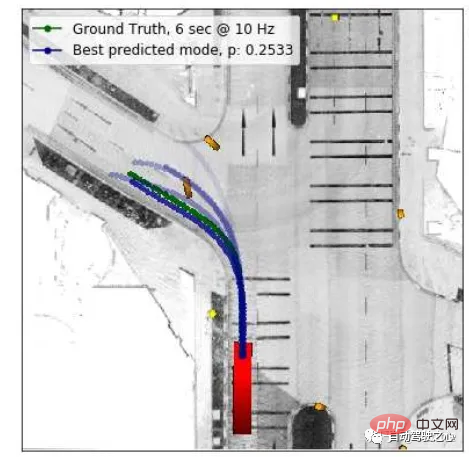
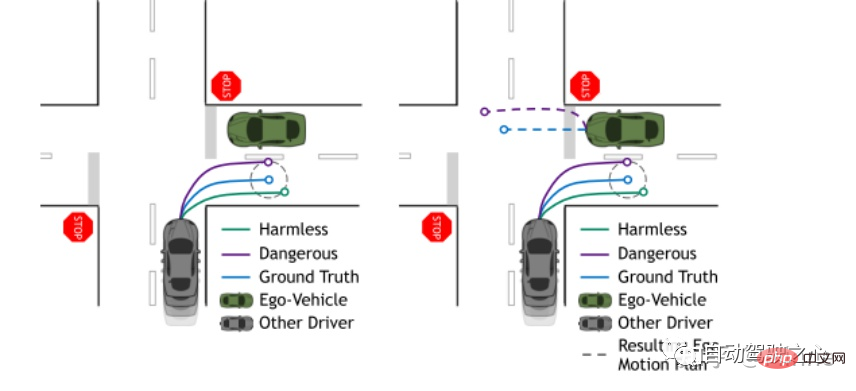
如下圖所示,此論文的主要考慮為基於真值(藍色),灰色的目標車預測的紫色與綠色軌跡如果使用幾何度量是具有相同的ADE與FDE的,但是不同的預測方式對自車的planning會造成影響,而現在沒有這種評估任務層級的度量,於是他們提出piADE與piFDE來做這件事。
#問題1:三種不同的軌跡預測方法:基於實體模型、基於學習、基於規劃各自應用場景在什麼地方,有什麼優缺點呢?
不同的建模方法可以結合並利用不同類型的上下文資訊。利用目標的上下文線索、動靜態環境可以擴展出所有建模方法。然而,不同的建模方法在結合不同類別的語義資訊時表現出不同程度的複雜性和效率。
1.基於物理模型的方法
#適用場景:目標、靜態環境、動力學模擬可以被顯式轉移方程式建模。
優點:
缺點:
這樣的缺點導致使用物理的方法限制在短期預測或obstacle-free的環境。
2.基於學習的方法
#適用場景:適合於當前環境具有複雜的未知資訊(例如具有豐富語意的公共區域),並且這些資訊可以用於比較大的預測範圍。
優點:
缺點:
3.基於規劃的方法
#適用場景:在終點定下來了且環境地圖可獲得的場景,有很好的表現。
優點:
缺點:
#基於規劃的方法本質上是map-aware 與 abstacle-aware,自然地使用語義線索進行擴展。通常情況下,他們會將情境複雜性編碼到目標/獎勵方程中,但這可能無法適當地整合動態線輸入。因此,作者必須設計具體的修改,將動態輸入納入預測演算法(Jump Markov Processes、local adaptations of the predicted trajectory、game-theoretic)。與基於學習的方法不同,目標輸入很容易合併,因為前向與逆向的規劃過程都基於同一個目標動態模型。
問題2:軌跡預測的問題現在已經解決了嗎?
軌跡預測的需求很大程度上取決於應用領域和其中的特定用例場景。短期內可能不能說軌跡預測這個問題已經解決了。以汽車產業舉例,因為有專門的標準規定,定義了最大速度、交通規則、行人速度和加速度的分佈,以及車輛舒適加速/減速率的規範,其在製定需求和提出的解決方案方面似乎是最成熟的。可以說對於智慧汽車的AEB功能,解決方案已經達到了允許工業化生產消費產品的性能水平,對於其所需用例已經解決。至於其他用例,則需要在不久的將來對需求進行更多的標準化和明確的表達。而對於魯棒性與穩定性還需要演進。
所以在回答軌跡預測是否已經解決這個問題之前,最起碼應該先定了標準。
目前對機器人領域來說
目前對於自動駕駛領域:
問題3:目前衡量軌跡預測效能的評估技術是否夠好?
目前對於預測演算法缺乏系統性的方法,特別是對於考慮上下文輸入以及預測任意數量的目標的軌跡預測方法。
現在大多數作者只使用幾何度量(AED, FDE)作為衡量演算法好壞的指標。然而對於長時間預測,預測通常是多模態的,並且與不確定性有關,對此種方法的性能評估應該使用考慮到這一點的指標,例如從KLD得到的負對數似然或對數損失。
此外也需要機率度量,可以更好地反映了人體運動的隨機性以及感知缺陷所涉及的不確定性。
還有穩健性的評估,需要考慮在感知端出現偵測錯誤,追蹤缺陷,自我定位不確定性或地圖變化此類場景時系統的穩定性。
同時目前所使用資料集,雖然包含的場景十分的全面,但是這些資料集通常是半自動註解的,因此只能提供不完整和有雜訊真值估計。此外,在一些需要長期預測的應用領域中,軌跡長度往往不足。最後,資料集中的目標之間的交互作用通常是有限的,例如在稀疏的環境裡面,目標之間很難有影響。
綜上:為了評估預測質量,研究者應該選擇更複雜的資料集(包括非凸的障礙、長軌跡和複雜的interaction)以及完整的度量指標(幾何機率)。比較好的方法是根據不同的預測時間、不同的觀測週期,不同的場景複雜度設定不同的精確度要求。並且應該有魯棒性評估以及即時性評估。此外應該有相關的指標可以衡量ADAS系統對後端影響程度的指標[18]以及衡量對危險場景敏感性的指標[1]。
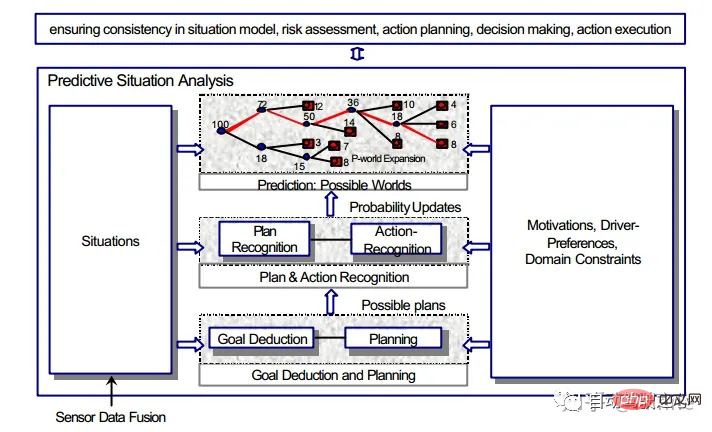
來自於[2]中的討論,此處為引用。
當前的趨勢時用更複雜的方法去超越使用單一模型KF的方法
##方向:
綜上:簡潔來說就是上下文資訊用的要更深入、最好對不同目標有不同行為模型、博弈論、基於更多資訊做更魯棒的意圖預測、對終點的自動推論、對新環境的泛化問題、魯棒性與可整合性。
以上是探討自動駕駛軌跡預測技術的現況及發展趨勢的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















