


為什麼AI聊天機器人會胡編亂造,我們能完全信任它們的輸出嗎?為此,我們詢問了幾位專家,並深入研究了這些AI模型是如何工作的,以找到答案。
AI聊天機器人(如OpenAI的ChatGPT)依賴一種稱為「大型語言模型」(LLM)的人工智能來產生它們的回應。 LLM是一種電腦程序,經過數百萬個文字來源的訓練,可以閱讀並產生「自然語言」文字語言,就像人類自然地寫作或交談一樣。不幸的是,它們也會犯錯。
在學術文獻中,AI研究者常稱這些錯誤為「幻覺」(hallucinations)。隨著這個主題成為主流,這個標籤也變得越來越具爭議,因為有些人認為它將人工智慧模型擬人化(暗示它們具有類人的特徵),或者在不應該暗示這一點的情況下賦予它們權力(暗示它們可以做出自己的選擇)。此外,商業LLM的創造者也可能以幻覺為藉口,將錯誤的輸出歸咎於AI模型,而不是對輸出本身負責。
儘管如此,生成式AI還是一個很新的領域,我們需要從現有的想法中藉用隱喻,向更廣泛的公眾解釋這些高度技術性的概念。在這種情況下,我們覺得「虛構」(confabulation)這個詞雖然同樣不完美,但比「幻覺」這個比喻要好。在人類心理學中,「虛構」指的是某人的記憶中存在一個空白,大腦以一段令人信服的虛構事實來填補他所遺忘的那段經歷,而非有意欺騙他人。 ChatGPT不像人腦那樣運行,但是術語「虛構」可以說是一個更好的隱喻,因為它是以創造性地填補空白的原則(而非有意欺騙)在工作,這一點我們將在下面探討。
當AI機器人產生虛假資訊時,這是一個大問題,這些資訊可能會產生誤導或誹謗效果。最近,《華盛頓郵報》報導了一名法學教授發現ChatGPT將他列入了性騷擾他人的法律學者名單。但此事是子虛烏有,完全是ChatGPT編的。同一天,Ars也報告了一名澳洲市長發現ChatGPT聲稱他被判受賄並被捕入獄,而這些資訊也完全是捏造的。
ChatGPT推出後不久,人們就開始鼓吹搜尋引擎的終結。然而,與此同時,ChatGPT的許多虛構案例開始在社群媒體上廣為流傳。 AI機器人發明了不存在的書籍和研究,教授沒有寫過的出版物,虛假的學術論文,虛假的法律引用,不存在的Linux系統功能,不真實的零售吉祥物,以及沒有意義的技術細節。
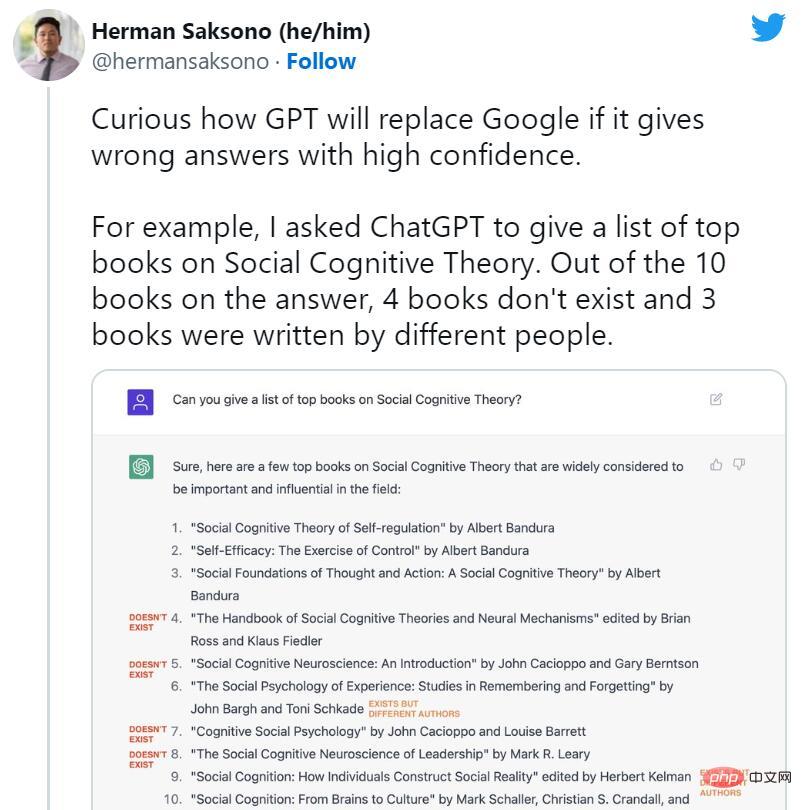
然而,儘管ChatGPT傾向於隨意撒些小謊,但它對虛構的抑制正是我們今天談論它的原因。一些專家指出,ChatGPT在技術上是對普通GPT-3(它的前身模型)的改進,因為它可以拒絕回答一些問題,或者當它的答案可能不準確時讓你知道。
大型語言模型專家、Scale AI的提示工程師(prompt engineer)Riley Goodside表示,「ChatGPT成功的一個主要因素是,它成功地抑制了虛構,使許多常見問題都不引人注意。與它的前輩相比,ChatGPT明顯不太容易編造東西。」
如果用作腦力激盪工具,ChatGPT的邏輯跳躍和虛構可能會導致創造性突破。但當用作事實參考時,ChatGPT可能會造成真正的傷害,而OpenAI也深知這一點。
在該模型發布後不久,OpenAI首席執行官Sam Altman就在推特上寫道,「ChatGPT的功能非常有限,但在某些方面足夠好,足以造成一種偉大的誤導性印象。現在在任何重要的事情上依賴它都是錯誤的。這是進步的預演;在穩健性和真實性方面,我們還有很多工作要做。」
在後來的一條推文中,他又寫道,「它確實知道很多,但危險在於,它在很大一部分時間裡是盲目自信的,是錯誤的。」
這又是怎麼一回事?
為了理解像ChatGPT或Bing Chat這樣的GPT模型是如何進行「虛構」的,我們必須知道GPT模型是如何運作的。雖然OpenAI還沒有發布ChatGPT、Bing Chat甚至GPT-4的技術細節,但我們確實可以在2020年看到介紹GPT-3(它們的前身)的研究論文。
研究人員透過使用一種稱為「無監督學習」的過程來建構(訓練)大型語言模型,如GPT-3和GPT-4,這意味著他們用於訓練模型的資料沒有特別的註釋或標記。在這個過程中,模型被輸入大量的文本(數以百萬計的書籍、網站、文章、詩歌、抄寫本和其他來源),並反覆嘗試預測每個單字序列中的下一個單字。如果模型的預測與實際的下一個單字接近,神經網路就會更新其參數,以加強導致該預測的模式。
相反地,如果預測不正確,模型會調整參數以提高效能並再次嘗試。這種試誤的過程,雖然是一種稱為「反向傳播」(backpropagation)的技術,但可以讓模型從錯誤中學習,並在訓練過程中逐漸改進其預測。
因此,GPT學習資料集中單字和相關概念之間的統計關聯。有些人,例如OpenAI首席科學家Ilya Sutskever,認為GPT模型比這更進一步,建立了一種內部現實模型,這樣他們就可以更準確地預測下一個最佳令牌(token),但這個想法是有爭議的。 GPT模型如何在其神經網路中提出下一個令牌的確切細節仍然不確定。

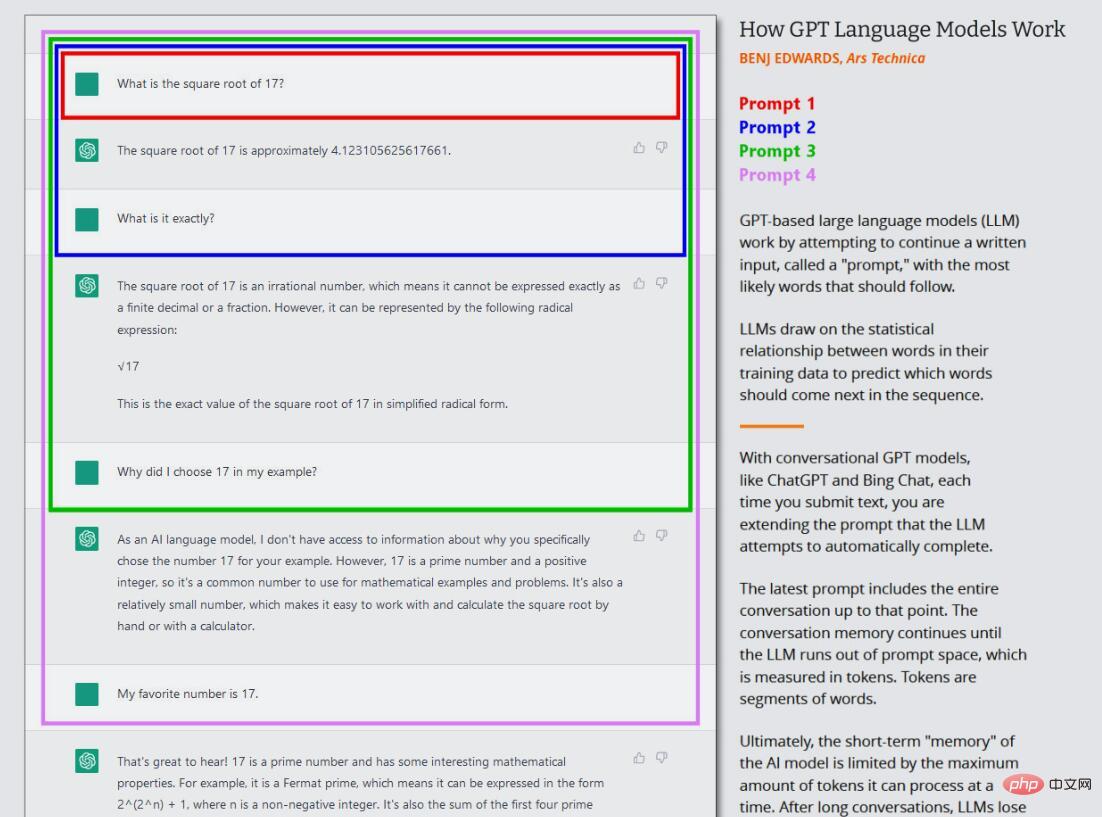
在目前的GPT模型浪潮中,這種核心訓練(現在通常稱為「預訓練」pre-training)只發生一次。在此之後,人們可以在「推斷模式」(inference mode)下使用訓練好的神經網絡,允許使用者將輸入輸進訓練好的網路中並得到結果。在推理期間,GPT模型的輸入序列總是由人類提供的,它被稱為「指令/提示」(prompt)。提示符決定了模型的輸出,即使稍微改變提示符號也會大幅改變模型產生的結果。
例如,如果你提示GPT-3“瑪麗有一個…(Mary had a)”,它通常會用“小羊羔”來完成句子。這是因為在GPT-3的訓練資料集中可能有成千上萬個「瑪麗有隻小羊羔(Mary had a little lamb)」的例子,這使得它成為一個合理的輸出結果。但是如果你在提示符中添加更多上下文,例如“在醫院,瑪麗有了一個(In the hospital, Mary had a)”,結果將會改變並返回“嬰兒”或“一系列檢查”之類的單字。
這就是ChatGPT的有趣之處,因為它被設定為與代理(agent)的對話,而不僅僅是一個直接的文字生成工作。在ChatGPT的情況下,輸入提示是你與ChatGPT進行的整個對話,從你的第一個問題或陳述開始,包括在模擬對話開始之前提供給ChatGPT的任何具體指示。在這個過程中,ChatGPT對它和你所寫的所有內容保持短期記憶(稱為「上下文視窗」),當它與你「交談」時,它正試圖完成對話的文本生成任務。
此外,ChatGPT不同於普通的GPT-3,因為它也接受了人類所寫的對話文本的訓練。 OpenAI在其最初的ChatGPT發布頁面中寫道,「我們使用監督微調(supervised fine-tuning)來訓練一個初始模型:人類AI訓練師提供對話,在對話中,他們會扮演雙方——用戶和人工智慧助手。我們為訓練師提供了模型編寫的建議,以幫助他們撰寫自己的答案。」
ChatGPT也使用一種稱為「基於人類回饋強化學習」(RLHF)的技術進行了更大的調整,在這種技術中,人類評分者會根據偏好對ChatGPT的回答進行排序,然後將這些資訊回饋到模型中。透過RLHF,OpenAI能夠在模型中灌輸「避免回答無法準確應答的問題」的目標。這使得ChatGPT能夠以比基礎模型更少的虛構產生一致的反應。但不準確的資訊仍會漏過。
從本質上講,GPT模型的原始資料集中沒有任何東西可以將事實與虛構區分開。
LLM的行為仍然是一個活躍的研究領域。即便是創建這些GPT模型的研究人員仍然在發現這項技術的驚人特性,這些特性在它們最初被開發時沒有人預測到。 GPT能夠做我們現在看到的許多有趣的事情,例如語言翻譯、程式設計和下棋,這一度讓研究人員感到驚訝。
所以當我們問為什麼ChatGPT會產生虛構時,很難找到一個確切的技術答案。由於神經網路權重有一個「黑盒子」(black box)元素,在給出一個複雜的提示時,很難(甚至不可能)預測它們的準確輸出。儘管如此,我們還是知道一些虛構發生的基本原因。
The key to understanding ChatGPT’s fictional capabilities is understanding its role as a prediction machine. When ChatGPT makes up, it's looking for information or analysis that doesn't exist in the data set and filling in the gaps with plausible-sounding words. ChatGPT is particularly good at making stuff up because of the sheer volume of data it has to process and its ability to gather word context so well, which helps it place error messages seamlessly into the surrounding text.
Software developer Simon Willison said, "I think the best way to think about fiction is to think about the nature of large language models: the only thing they know how to do is choose the next best thing based on the training set based on statistical probability. words."
In a 2021 paper, three researchers from the University of Oxford and OpenAI identified two main types of lies that LLMs like ChatGPT can produce. The first comes from inaccurate source material in its training data set, such as common misconceptions (e.g., “eating turkey will make you sleepy”). The second arises from making inferences about specific situations that do not exist in its training data set; this falls under the "hallucination" label mentioned earlier.
Whether a GPT model makes wild guesses depends on what AI researchers call a "temperature" attribute, which is often described as a "creativity" setting. If creativity is set high, the model will make wild guesses; if it's set low, it will spit out data deterministically based on its data set.
Recently, Microsoft employee Mikhail Parakhin took to Twitter to talk about Bing Chat’s tendency to hallucinate and what causes hallucinations. He wrote, "This is what I tried to explain before: illusion = creativity. It tries to produce the highest probability continuation of the string using all the data it processes. It's usually correct. Sometimes people have never made such a continuation. ”
Parakhin added that these crazy creative leaps are what makes LLM fun. You can suppress the hallucinations, but you'll find it super boring. Because it always answers "I don't know", or only returns what's in the search results (which is also sometimes incorrect). What's missing now is tone: it shouldn't come across as confident in these situations. ”
When it comes to fine-tuning a language model like ChatGPT, balancing creativity and accuracy is a challenge. On the one hand, the ability to come up with creative responses makes ChatGPT a powerful tool for generating new ideas or eliminating writer’s block. This also makes the model sound more human. On the other hand, accuracy of the source material is crucial when it comes to producing reliable information and avoiding fiction. For language model development, finding the right balance between the two The balance of information, but the resulting neural network is only a fraction of the size. In a widely read New Yorker article, author Ted Chiang called it a "blurred network JPEG." This means a large Some of the factual training data is lost, but GPT-3 makes up for this by learning relationships between concepts, which it can later use to reformulate new arrangements of those facts. Just like a person with a defective memory works from hunches , it sometimes gets it wrong. Of course, if it doesn't know the answer, it gives its best guess.
We can't forget the role prompts play in fiction. In some ways, ChatGPT is a mirror: What you give it, it gives you. If you feed it lies, it will tend to agree with you and "think" along those lines. This is why it doesn't respond when changing the topic or encountering an unwanted response. It is important to start over with a new prompt. ChatGPT is probabilistic, which means it is partially random in nature. What it outputs may change between sessions, even with the same prompt .
All of this leads to one conclusion, one that OpenAI agrees with: ChatGPT, as currently designed, is not a reliable source of factual information and cannot be trusted. Researcher and Chief Ethics Scientist at AI company Hugging Face Dr. Margaret Mitchell believes, “ChatGPT can be very useful for certain things, such as reducing writer’s block or coming up with creative ideas. It was not built for truth and therefore cannot be truth. It's that simple. ”
Can lying be corrected?
So how does OpenAI plan to make ChatGPT more accurate? In the past few We contacted OpenAI multiple times over the course of the month about this issue, but received no response. But we can find clues in documents released by OpenAI and news reports about the company's attempts to guide ChatGPT to align with human employees.
As mentioned before, one of the reasons why ChatGPT is so successful is because of its extensive training using RLHF. OpenAI explains, “To make our models safer, more helpful, and more consistent, we use an existing technology called ‘Reinforcement Learning with Human Feedback (RLHF).’ According to tips submitted by customers to the API, Our tagger provides a demonstration of the desired model behavior and sorts several outputs from the model. We then use this data to fine-tune GPT-3."
OpenAI's Sutskever believes that through RLHF Additional training can address hallucinations. "I very much hope that simply improving this follow-up RLHF will teach it not to hallucinate," Sutskever told Forbes earlier this month.

He continued, "The way we do things today is we hire people to teach our neural networks how to react, teach the chat tool how to react. You just interact with it and it learns from your reactions , oh, this is not what you want. You are not happy with the output of it. So the output is not very good and should do something different next time. I think this is a big change and this method will be able to fully Solve the hallucination problem."
Others disagree. Yann LeCun, chief artificial intelligence scientist at Meta, believes that the current LLM using the GPT architecture cannot solve the hallucination problem. But there is an emerging method that may bring higher accuracy to LLM under current architecture. He explains, “One of the most actively researched approaches to adding realism in LLM is retrieval augmentation—providing models with external documents as sources and supporting context. With this technique, the researchers hope to teach the model to use external documents like Google’s Search engines, like human researchers, cite reliable sources in answers and rely less on unreliable factual knowledge learned during model training."
Bing Chat and Google Bard already enable web search With this in mind, soon, a browser-supported version of ChatGPT will also be implemented. Additionally, the ChatGPT plugin is designed to complement GPT-4’s training data by retrieving information from external sources such as the web and purpose-built databases. This enhancement is analogous to how people with an encyclopedia will describe facts more accurately than people without an encyclopedia.
Also, it is possible to train a model like GPT-4 so that it realizes when it is making things up and adjusts accordingly. Mitchell believes that "there are some deeper things that people could do to make ChatGPT and things like it more realistic from the start, including more sophisticated data management and using a PageRank-like approach to align training data with 'trust' The scores are tied together... and the model can also be fine-tuned to hedge the risk when it's less confident in the responses."
So while ChatGPT is currently in trouble with its fictitious issues, maybe there's a way to A way out, as more and more people start to rely on these tools as basic assistants, it is believed that reliability improvements should come soon.
以上是為什麼ChatGPT和Bing Chat如此擅長編造故事的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















