

在本文中,我們將詳細介紹決策樹和隨機森林模型。此外,我們將展示決策樹和隨機森林的哪些超參數對它們的表現有重要影響,使我們能夠在欠擬合和過擬合之間找到最佳方案。在了解了決策樹和隨機森林背後的理論後。 ,我們將使用Scikit-Learn來實現它們。
決策樹是預測建模機器學習的重要演算法。經典的決策樹演算法已經存在了幾十年,而像隨機森林這樣的現代變體是最強大的可用技術之一。
通常,這種演算法被稱為“決策樹”,但在R等一些平台上,它們被稱為CART。 CART演算法為bagged決策樹、隨機森林和boosting決策樹等重要演算法提供了基礎。
與線性模型不同,決策樹是非參數模型:它們不受數學決策函數的控制,也沒有要最佳化的權重或截距。事實上,決策樹將透過考慮特徵來劃分空間。
CART模型的表示是二元樹。這是來自演算法和資料結構的二元樹。每個根節點表示一個輸入變數(x)和該變數上的一個分割點(假設變數是數值型的)。
樹的葉節點包含一個輸出變數(y),用於進行預測。給定一個新的輸入,透過從樹的根節點開始計算特定的輸入來遍歷樹。
決策樹的一些優點是:
決策樹的缺點包括:
隨機森林是最受歡迎和最強大的機器學習演算法之一。它是一種整合機器學習演算法,稱為Bootstrap Aggregation或bagging。
為了提高決策樹的效能,我們可以使用許多具有隨機特徵樣本的樹。
我們將使用決策樹和隨機森林來預測您有價值的員工的流失
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set_style("whitegrid")
plt.style.use("fivethirtyeight")
df = pd.read_csv("WA_Fn-UseC_-HR-Employee-Attrition.csv")
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
df.drop(['EmployeeCount', 'EmployeeNumber', 'Over18', 'StandardHours'], axis="columns", inplace=True)
categorical_col = []
for column in df.columns:
if df[column].dtype == object and len(df[column].unique()) 50:
categorical_col.append(column)
df['Attrition'] = df.Attrition.astype("category").cat.codes
categorical_col.remove('Attrition')
label = LabelEncoder()
for column in categorical_col:
df[column] = label.fit_transform(df[column])
X = df.drop('Attrition', axis=1)
y = df.Attrition
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
def print_score(clf, X_train, y_train, X_test, y_test, train=True):
if train:
pred = clf.predict(X_train)
print("Train Result:n================================================")
print(f"Accuracy Score: {accuracy_score(y_train, pred) * 100:.2f}%")
print("_______________________________________________")
print(f"Confusion Matrix: n {confusion_matrix(y_train, pred)}n")
elif train==False:
pred = clf.predict(X_test)
print("Test Result:n================================================")
print(f"Accuracy Score: {accuracy_score(y_test, pred) * 100:.2f}%")
print("_______________________________________________")
print(f"Confusion Matrix: n {confusion_matrix(y_test, pred)}n")
5.1 決策樹分類器
from sklearn.tree import DecisionTreeClassifier
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train, y_train)
print_score(tree_clf, X_train, y_train, X_test, y_test, train=True)
print_score(tree_clf, X_train, y_train, X_test, y_test, train=False)
5.2決策樹分類器超參數調優
超參數max_depth控制決策樹的整體複雜性。這個超參數允許在欠擬合和過擬合決策樹之間進行權衡。讓我們為分類和迴歸建立一棵淺樹,然後再建立一棵更深的樹,以了解參數的影響。
###超參數min_samples_leaf、min_samples_split、max_leaf_nodes或min_implitity_reduce允許在葉級或節點級應用約束。超參數min_samples_leaf是葉子允許有最少樣本數,否則將不會搜尋進一步的分割。這些超參數可以作為max_depth超參數的補充方案。 ###from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
params = {
"criterion":("gini", "entropy"),
"splitter":("best", "random"),
"max_depth":(list(range(1, 20))),
"min_samples_split":[2, 3, 4],
"min_samples_leaf":list(range(1, 20)),
}
tree_clf = DecisionTreeClassifier(random_state=42)
tree_cv = GridSearchCV(tree_clf, params, scoring="accuracy", n_jobs=-1, verbose=1, cv=3)
tree_cv.fit(X_train, y_train)
best_params = tree_cv.best_params_
print(f"Best paramters: {best_params})")
tree_clf = DecisionTreeClassifier(**best_params)
tree_clf.fit(X_train, y_train)
print_score(tree_clf, X_train, y_train, X_test, y_test, train=True)
print_score(tree_clf, X_train, y_train, X_test, y_test, train=False)
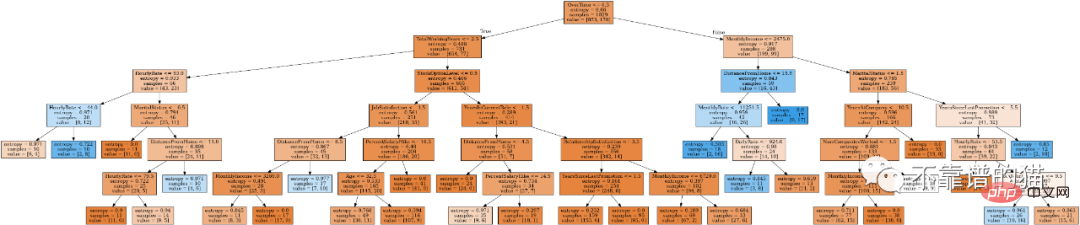
from IPython.display import Image
from six import StringIO
from sklearn.tree import export_graphviz
import pydot
features = list(df.columns)
features.remove("Attrition")
dot_data = StringIO()
export_graphviz(tree_clf, out_file=dot_data, feature_names=features, filled=True)
graph = pydot.graph_from_dot_data(dot_data.getvalue())
Image(graph[0].create_png())
随机森林是一种元估计器,它将多个决策树分类器对数据集的不同子样本进行拟合,并使用均值来提高预测准确度和控制过拟合。
随机森林算法参数:
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(n_estimators=100)
rf_clf.fit(X_train, y_train)
print_score(rf_clf, X_train, y_train, X_test, y_test, train=True)
print_score(rf_clf, X_train, y_train, X_test, y_test, train=False)
调优随机森林的主要参数是n_estimators参数。一般来说,森林中的树越多,泛化性能越好,但它会减慢拟合和预测的时间。
我们还可以调优控制森林中每棵树深度的参数。有两个参数非常重要:max_depth和max_leaf_nodes。实际上,max_depth将强制具有更对称的树,而max_leaf_nodes会限制最大叶节点数量。
n_estimators = [100, 500, 1000, 1500]
max_features = ['auto', 'sqrt']
max_depth = [2, 3, 5]
max_depth.append(None)
min_samples_split = [2, 5, 10]
min_samples_leaf = [1, 2, 4, 10]
bootstrap = [True, False]
params_grid = {'n_estimators': n_estimators, 'max_features': max_features,
'max_depth': max_depth, 'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf, 'bootstrap': bootstrap}
rf_clf = RandomForestClassifier(random_state=42)
rf_cv = GridSearchCV(rf_clf, params_grid, scoring="f1", cv=3, verbose=2, n_jobs=-1)
rf_cv.fit(X_train, y_train)
best_params = rf_cv.best_params_
print(f"Best parameters: {best_params}")
rf_clf = RandomForestClassifier(**best_params)
rf_clf.fit(X_train, y_train)
print_score(rf_clf, X_train, y_train, X_test, y_test, train=True)
print_score(rf_clf, X_train, y_train, X_test, y_test, train=False)
本文主要讲解了以下内容:
以上是決策樹與隨機森林的理論、實現與超參數調整的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































