

譯者 | 朱先忠
審校 | 孫淑娟
一般來說,軟體測試往往是比較簡單的:每個輸入=>已知輸出。然而,縱觀整個軟體測試的歷史,會發現許多測試往往都停留在猜測層面。也就是說,測試時由開發者構思出使用者的操作流程,估計可能出現的負載並分析需要耗費的時間,然後執行測試,並將目前結果與基準答案進行比較。如果我們發現不存在迴歸,那麼就認為目前建置方案是正確的;然後,繼續後面的測試。如果存在回歸,就返回。大多數時候,我們已經知道了輸出結果,儘管它需要更好的定義——回歸的邊界清晰,而且不那麼模糊。其實,這正是機器學習(ML)系統和預測分析的切入點——結束歧義。
測試完成後,性能工程師所做的工作不僅是查看結果的算術平均值和幾何平均值,他們還會查看有關百分比數據。例如,系統運作過程中,往往10%最慢的請求都是由系統錯誤導致的-這個錯誤會產生一個總是影響程式運作速度的條件。
雖然我們可以手動關聯資料中可用的屬性,但是ML可能會比您以更快的速度連結資料屬性。在確定導致10%的錯誤請求的條件後,效能工程師便可以建立測試場景來重現該行為。在修復之前和之後執行測試能夠幫助確定修復已經修正。

圖1:對績效指標的整體信心
機器學習有助於促進軟體開發,使相關開發技術更堅固、更好地滿足使用者在不同領域和行業的需求。我們可以透過將管道和環境中的資料輸入到深度學習演算法來揭露因果模式。預測分析演算法與效能工程方法結合,可實現更有效率、更快的吞吐量,深入了解終端用戶如何在自然場景下使用軟體,並幫助開發者降低帶有缺陷的產品應用於生產環境的可能性。透過及早發現問題及其原因,您可以在開發生命週期的早期進行問題糾正,並防止對生產產生影響。整體來看,您可以透過以下方式利用預測分析來提高應用程式效能。
「大數據」通常指的是資料集。不錯,是大數據集,速度提升很快,內容變化也很大。對於這樣數據的分析需要專門的方法,以便我們能夠從中提取模式和資訊。近年來,儲存、處理器、進程並行化以及演算法設計的改進都使得系統能夠在合理的時間內處理大量數據,從而允許更廣泛地使用這些方法。為了獲得有意義的結果,您必須確保數據的一致性。
例如,每個項目必須使用相同的排名系統,因此,如果一個項目使用1作為關鍵值,而另一個項目使用5——就像人們使用「DEFCON 5 」表示「DEFCON 1」時一樣;那麼,必須在處理之前對這些值進行規範化處理。預測演算法由演算法及其輸入的數據組成,而軟體開發產生了大量數據,直到最近,這些數據仍處於閒置狀態,等待刪除。然而,預測分析演算法可以處理這些文件,針對我們無法檢測到的模式,根據這些數據提出和回答問題,例如:
這些問題及其答案就是預測分析的用途——更能理解可能發生的事情。
預測分析的另一個主要組成部分是演算法;您需要仔細選擇或實作它。從簡單開始是至關重要的,因為模型往往會變得越來越複雜,對輸入資料的變化越來越敏感,並有可能扭曲預測。它們可以解決兩類問題:分類和迴歸(見圖2)。
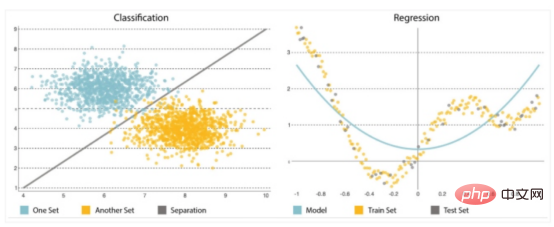
#圖2:分類與迴歸
#神經網路透過實例學習,並使用歷史資料和當前資料來預測未來價值。它們的架構允許它們識別隱藏在資料中的複雜關係,以複製我們大腦偵測模式的方式。它們包含許多層,這些層接受數據、計算預測並作為單一預測提供輸出。
決策樹是一種分析方法,它將結果呈現在一系列「if/then」選項中,以預測特定選項的潛在風險和收益。它可以解決所有分類問題並回答複雜問題。
如圖3所示,決策樹類似於由演算法產生的自頂向下的樹,該演算法能夠識別將資料分割成分支狀劃分的各種方式,以說明未來的決策並協助識別決策路徑。
如果載入時間超過三秒,樹中的一個分支可能是放棄購物車的使用者。在這一條之下,另一個分支可能會指示她們是否屬於女性。 「yes」的回答會增加風險,因為分析表明,女性更容易衝動購買,而這種延遲會讓人陷入沉思。
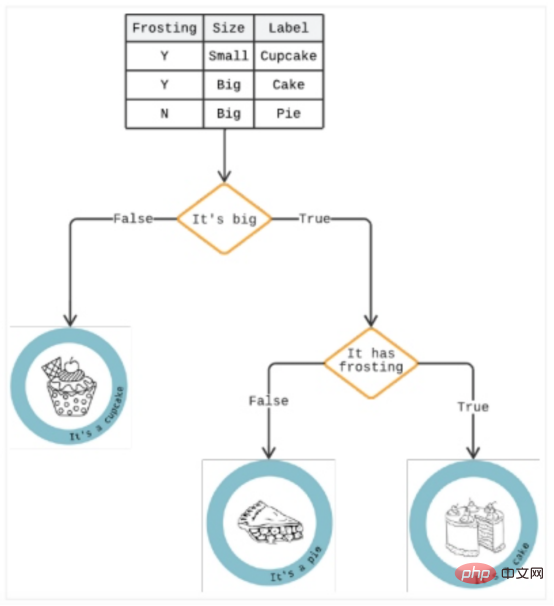
圖3:決策樹範例
迴歸是最受歡迎的統計方法之一。在估算數字時,這一點至關重要,例如在「黑色星期五」大促活動期間,我們需要為每項服務增加多少資源。許多迴歸演算法被設計來估計變數之間的關係,在龐大的和混合的資料集中找到關鍵模式,以及它們之間的關係。它的範圍從簡單的線性迴歸模型(計算擬合資料的直線函數)到邏輯迴歸(計算曲線)(圖4)。
#線性與邏輯迴歸#總體對比 | |
|
#線性回歸 # |
邏輯迴歸 |
| 用於定義連續範圍內的值,例如接下來幾個月用戶流量峰值的風險。 |
這是一種統計方法,其中參數是根據舊的集合預測的。它最適合二進位分類:y=0或1的資料集,其中1表示預設類別別。它的名字來自於它的轉換函數(是一個邏輯函數#)。 |
它表示為y=a bx,其中x是用來決定輸出y的輸入集。係數a和b用來量化x和y之間的關係,其中a是截距,b是直線的斜率。 |
它由邏輯函數表示: 其中,β0是截距,β1#是速率。它使用訓練資料來計算係數,將預測結果與實際結果之間的誤差最小化。 |
目標是擬合最接近大多數點的直線,減少y和直線之間的距離或誤差。 |
它形成S形曲線,其中應用閾值將機率轉換為二進位分類。 |
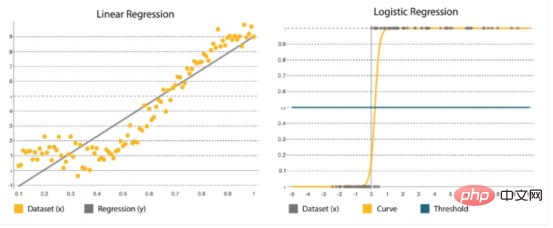
圖4:線性迴歸與邏輯迴歸
#這些是監督學習方法,因為演算法解決了特定的屬性。當你心中沒有特定的結果,但想確定可能的模式或趨勢時,可以使用無監督學習。在這種情況下,該模型將分析盡可能多的特徵組合,以找到人類可以採取行動的相關性。
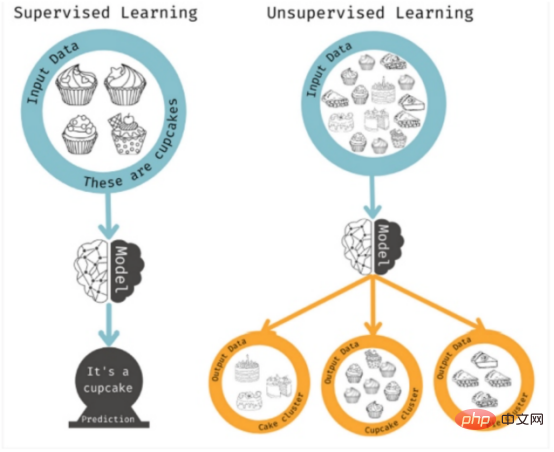
圖5:有監督與無監督學習
使用先前的演算法來衡量消費者對產品和應用程式的看法,使得效能工程更加以消費者為中心。收集所有資訊後,必須透過適當的工具和演算法對其進行儲存和分析。這些數據可以包括錯誤日誌、測試案例、測試結果、生產事件、應用程式日誌檔案、專案文件、事件日誌、跟踪,等等。然後,我們可以將其應用於資料中,以獲得各種見解:
此技術支援品質方面的左移(shift-left)方法,可讓您預測執行效能測試所需的時間、可能識別的缺陷數量以及可能導致生產的缺陷數量,從而實現效能測試的更好覆蓋,並創建真實的用戶體驗。可防止和修正可用性、相容性、效能和安全性等問題,而不會影響使用者。
以下是一些有助於提高品質的資訊類型的範例:
一旦您了解了這一點,就可以進行更改並建立測試,以更快地防止類似問題。
自從程式設計誕生以來,軟體工程師已經做出了成百上千的假設。但是,今天的數位用戶們更加意識到這一點,而且對錯誤和失敗的容忍度也進一步降低。另一方面,企業也在競相通過量身訂製的服務和越來越難測試的複雜軟體,試圖提供更具吸引力和完美的使用者體驗。
今天,一切都需要無縫運作,並支援所有流行的瀏覽器、行動裝置和應用程式。即使是幾分鐘的撞車事故也可能造成數千或數百萬美元的損失。為了防止問題,團隊必須在整個軟體生命週期中整合可觀測性解決方案和使用者體驗。管理複雜系統的品質和效能需要的不僅僅是執行測試案例和運行負載測試。趨勢可以幫助您判斷情況是否受到控制、改善或惡化,以及改善或惡化的速度。機器學習技術可以幫助預測效能問題,使團隊能夠正確進行方案調整。最後,讓我們來引用本傑明·富蘭克林(Benjamin Franklin)的一句話作為結束語:「一盎司預防抵得上一磅治療。」
朱先忠,51CTO社群編輯,51CTO專家部落格、講師,濰坊一所大學電腦教師,自由程式設計界老兵一枚。
原文標題:#Performance Engineering Powered by Machine Learning,作者:
以上是機器學習助力高品質軟體工程的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















