

排序模型在廣告、推薦和搜尋系統中扮演了至關重要的角色。在排序模組中,點擊率預估技術又是重中之重。目前工業界的點擊率預估技術大多採用深度學習演算法,基於數據驅動來訓練深度神經網絡,然而數據驅動帶來的相應問題是推薦系統中的新進項目會存在冷啟動問題。
探索與利用(Exploration-Exploitation,E&E)方法通常用於處理大規模線上推薦系統中的資料循環問題。過去的研究通常認為模型預估不確定度高意味著潛在效益也較高,因此大部分研究文獻聚焦到不確定度的估計。對於採用流式訓練的線上推薦系統而言,探索策略會對訓練樣本的收集產生較大影響,進而影響模型的進一步學習。然而,目前大多數探索策略並不能很好的建模被探索的樣本如何對後續模型學習產生影響。因此,我們設計了一個擬探索(Pseudo-Exploration) 模組來模擬樣本被成功探索並展現後對推薦模型後續學習的影響。
擬探索過程透過在模型輸入中加入對抗擾動來實現,我們同時也給出了該過程相應的理論分析以及證明。基於此,我們將此方法命名為基於對抗梯度的探索策略( A dversarial G radient driven E xploration,以下簡稱 AGE )。為了提高探索的效率,我們也提出了一個動態門控單元用來過濾低價值樣本,避免將資源浪費在低價值的探索上。為了驗證AGE演算法的有效性,我們不僅在公開學術資料集上進行了大量的實驗,也將AGE模型部署到了阿里媽媽展示廣告平台上並取得了良好的線上收益。這項工作已被KDD 2022 Research Track收錄為Full Paper,歡迎閱讀交流。
論文: Adversarial Gradient Driven Exploration for Deep Click-Through Rate Prediction
下載: https://arxiv.org/abs/2112.11136
在廣告系統中,點擊率(CTR)預估模式通常採用串流方式加以訓練,而串流資料的來源又是由部署在線上的CTR模式產出,這就產生了所謂的 資料循環問題。冷啟動與長尾廣告由於沒有充分展現,CTR模型缺乏對這部分廣告的訓練數據,這也導致模型對這部分廣告的估計可能存在較大誤差,會使得這些廣告更加難以展現,進而難以完成冷啟動過程。具體而言,圖一給出了廣告真實點擊率與展現數量之間的關係:在我們系統中,一個新廣告的展現平均需要達到約一萬次,其點擊率才能達到收斂態。這給許多線上系統帶來了一個常見的難題,即如何在保證用戶體驗的前提下,為這些廣告做好冷啟動。
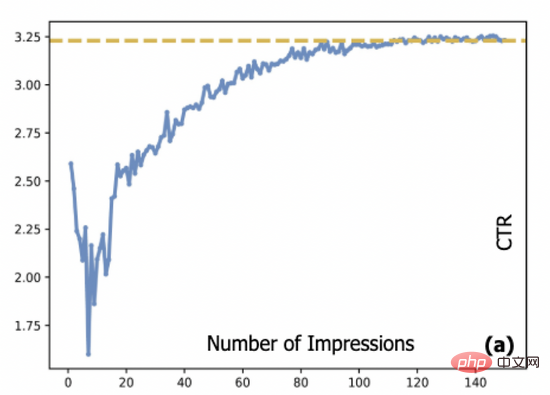
圖一:廣告CTR和展現次數之間的關係
#探索和利用(E&E)演算法通常被用來解決上述問題。在推薦或廣告系統中,常見的方法(如Contextual Multi-Armed Bandits,上下文多臂老虎機)一般會將該問題按照如下方式加以建模。在每個步驟中,系統會基於策略P選擇一個操作(即為使用者推薦一個項目_ _)。為了最大化累積獎勵(通常使用總點擊量來衡量),系統需要權衡目前是偏重探索,還是偏重利用。先前的研究通常認為,高不確定性是潛在回報的衡量指標。一方面,策略P需要優先選擇當前效用較大的項目以最大化本輪收益;另一方面,演算法也需要選擇不確定度較大的操作以實現探索。如果用來表示權衡探索和利用的策略,那麼系統對專案最終評分可以用以下公式表示:
不確定性估計已成為許多E&E演算法的核心模組。不確定性可能源自於資料的變異性、測量雜訊和模型不穩定性(例如:參數的隨機性),典型的估計方法包括蒙特卡羅MC-Dropout、貝葉斯神經網路、預測不確定性的高斯過程,以及基於梯度範數(模型權重)的不確定性建模等。在此基礎上,有兩種典型的探索策略:基於UCB的方法通常採用潛在回報的上限作為最終評分[1,2],而基於湯普森採樣的方法是透過從估計的機率分佈中抽樣來完成[ 3]。
我們認為,上述方法並未考慮一個完整的探索閉環。對於數據驅動的線上系統而言,探索的最終收益來自於從探索過程中獲得的回饋數據,以及回饋數據對於模型的訓練與更新。而模型預估的不確定度本身並不能完全反映整個回饋閉環。為此,我們引入了一個擬探索模組,用於模擬完成探索動作後回饋資料對於模型的影響,並以此來衡量探索的有效性。分析發現,探索的有效性不僅取決於模型的預估不確定度,還取決於「對抗擾動」的大小。所謂對抗擾動,指的是模型的輸入上加入的固定模長的擾動中使得模型輸出變化最大的擾動向量。在論文中,我們也證明了,模型利用被探索的資料進行一次訓練後,模型輸出變化的期望等價於在輸入向量中加入模長為不確定度、擾動向量為對抗梯度的增量向量。我們驗證了以這種方式進行建模,可以閉環地估計出被探索樣本對模型的後續影響,從而估計出被探索樣本的真實價值。
我們將這個方法稱為 基於對抗梯度的探索(Adversarial Gradient driven Exploration) ,簡稱AGE。 AGE模型由擬探索模組(Pseudo-Exploration Module)與動態門控閾值單元(Dynamic Gating Unit)兩部分組成,其整體結構如圖二所示。
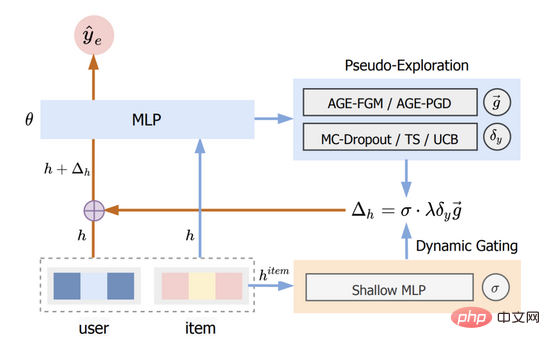
圖二:AGE結構圖
其中部分的詳細介紹詳見3.1節,部分的詳見3.3節。
3.1.1 模組簡介
擬探索模組的主要目的是定量模擬模型使用在探索樣本加以訓練後,對此樣本評分的變化,從而估計探索對於模型的閉環影響。經過推導,我們發現可以透過公式(2)來完成上述過程,其中代表了探索後模型對該樣本的評分,我們將其用於最終的排序。
上式表示我們不需要對原有模型參數進行任何操作,只需要在輸入的表徵中加上對抗梯度,預估不確定度以及手工設定的超參數的乘積,即可完成探索後模型預估分的模擬。 其中參數 與 的計算方法,我們在下一節中介紹。本節後續我們將介紹擬探索模組中公式(2)的詳細推導過程。
3.1.2 詳細推導
對於每個資料樣本而言,模型的訓練將會影響兩部分參數:此樣本對應的表徵(包含商品、用戶embedding等)與模型參數。因為模型參數在訓練中的目標是適應所有樣本而不是單條樣本,所以我們可以認為訓練單條樣本主要會對樣本對應的表徵產生影響,而模型參數本身只需要微小的調整。因此,在後續研究中,我們將忽略的調整,而僅關注樣本對應的表徵的變化。假設包含表徵的樣本真實label為,訓練時,我們需要尋找到的更新量,以最小化損失函數。基於此,我們定義:
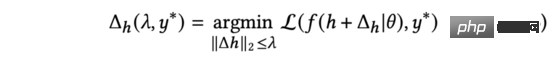
其中代表訓練中使用的損失函數,而在CTR預估任務中一般使用交叉熵損失函數。同時,我們用來約束表徵的最大變化。為了簡化書寫,後續我們將上述公式右側寫為。
依據拉格朗日中值定理,在的二範數接近0的情況下,我們可以將上述損失函數公式(3)推導為:
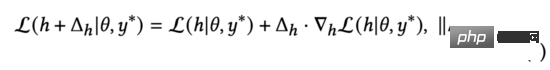
我們觀察公式(4),易發現該損失函數在與兩個向量有相反的方向時,得到最小值。在式(3)中,我們約束對抗擾動。因此,透過求解公式(3),我們得到:
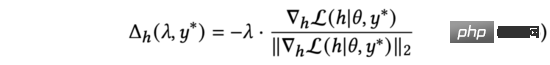
實務中,我們用來取代公式(5)中的歸一化梯度。透過求導鍊式法則,可以展開為和兩部分。進一步計算,得到:
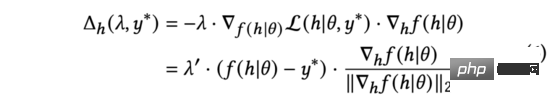
在上式中,我們將重新縮放到以維持等式的成立。儘管意義不同,但它們都是手動調節的超參數,故我們可以直接以完成替換。我們進一步簡化公式(6)為:
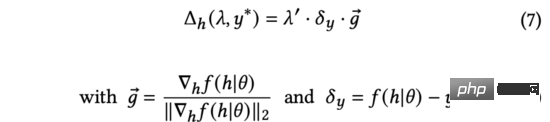
上式中,歸一化梯度表示模型輸出相對於輸入表徵的導數方向。由於真實的使用者回饋在探索時無法得到,我們將使用預估不確定度來衡量預測分數與真實使用者回饋之間的差異。
公式(7)中,我們找到了在的限制下可以最大化改變模型預測輸出的解析解(推導與公式(3)到公式(5)相同)。進一步,我們也發現上述對輸入表徵添加的過程與對抗擾動(見公式(9))的形式相同。
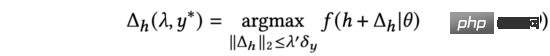
因此,我們利用對抗梯度來的替代公式(7)中的,並將我們的方法命名為基於對抗性梯度的探索演算法。
公式(9)表明,AGE最有效的探索方式為給表徵輸入加入對抗擾動,以擾動後模型的輸出結果為排序因子:以對抗梯度為輸入表徵的擾動向量方向,以及以預測不確定性度的擾動力度。於是,在得到和後,我們可以用下述公式來計算探索後的模型預測分數,該公式即為前述公式(2)。
在AGE中,我們採用MC-Dropout的方法估計不確定度。具體來說來,MC-Dropout為深度模型中的每個神經元賦予隨機Mask權重,具體做法如下公式(11)所示。此方法的一個好處是,我們可以在不改變模型原始結構的基礎上直接獲得不確定性。在實際操作中,可以透過UCB的想法計算dropout的變異數來表示不確定度,或參考湯普森隨機取樣的方式透過計算取樣與平均值的差異來計算不確定度,也即公式(12)和公式(13 )。
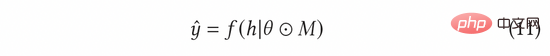
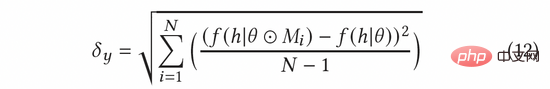
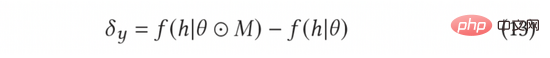
歸一化對抗梯度可以根據公式(8)中的快速梯度法(FGM)來計算。為了更精確地計算出對抗梯度,我們也可以進一步利用近端梯度下降(PGD)方法,多步驟迭代更新梯度,如公式(14)所示。
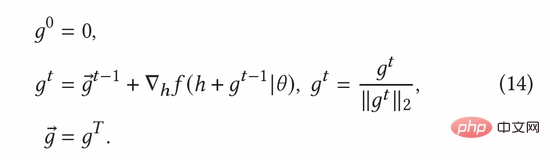
在實務中,我們發現並非所有廣告都值得探索。在一般的Top-K廣告系統中,能夠為最終用戶展現的廣告數量是相對較少。因此,本身點擊率低的廣告(例如廣告本身品質較低),即使模型對這部分廣告的預估存在很高的不確定性,但考慮廣告系統的業務屬性,其探索價值仍然是很低的。雖然我們可以透過探索獲得了這些廣告的大量數據,使得這些廣告被模型充分訓練而估計的更加準確;但因為這些廣告的本身過低的點擊率會使得即使充分探索後,這些廣告依然無法自行獲取流量,這樣的探索無疑是低效率的。在本文中,我們嘗試了一種簡單的啟發式方法來提高探索的效率——如果模型對該廣告的預估分數高於該廣告在所有人群中的平均點擊率,我們將進行探索;否則,探索將不會發生。
為了計算廣告的平均點擊率,我們引入了動態閘控閾值單元(DGU)模組。 DGU僅使用廣告側特徵作為輸入來預估廣告的平均點擊率。當模型的預估點擊率低於DGU模組預估的廣告平均點擊率時,不予探索,反之則進行正常的探索。流程如下式所示:
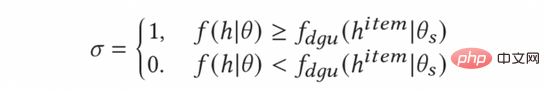
最終,我們將代入公式(10)中,得到以下AGE探索模型最終完整的計算方式。
我們比較了三大類基準方法,包括基於隨機取樣的探索方法,基於深度模型的探索方法,以及基於梯度的探索方法,結果如表1所示。觀察可得,基於湯普森採樣(TS)方法所建構的基線模型均優於基於UCB的模型,證明TS是一種更好的衡量模型不確定度的演算法。此外,我們可以觀察到AGE演算法優於所有的基線方法,這也證明了AGE方法的有效性。具體而言,AGE-TS和AGE-UCB的表現均優於最佳基線UR-gradient-TS和UR-gradient-UCB [4],提升數值分別為5.41%和15.3%。而AGE-TS方法相比於不進行探索的基準方法提高了整整28.0%的點擊量。值得注意的是,基於AGE的UCB和TS演算法AGE-UCB和AGE-TS取得了相似的效果,基於gradient的UCB和TS演算法並非如此,這也證明了AGE可以彌補UCB方法的不穩定性。
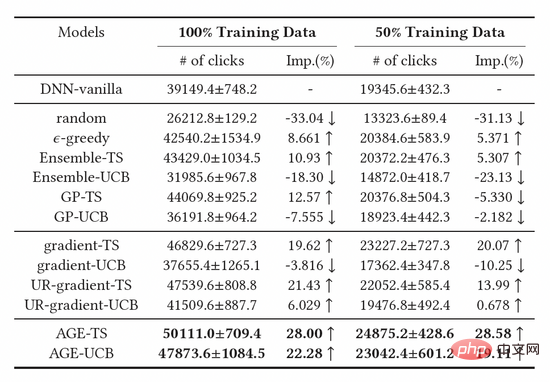
表1:離線實驗結果
我們也進行了大量的消融實驗來證明了各個模組的有效性。如表2所示,閾值單元、對抗梯度、不確定度單元,三者皆不可或缺。為了進一步確定DGU的效果,我們嘗試了不同的固定閾值參數,最後也發現其效果也不如DGU的動態閾值。
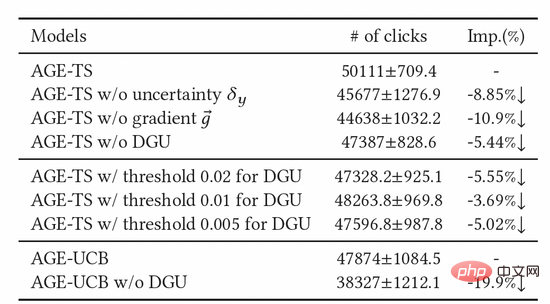
表2:消融實驗結果
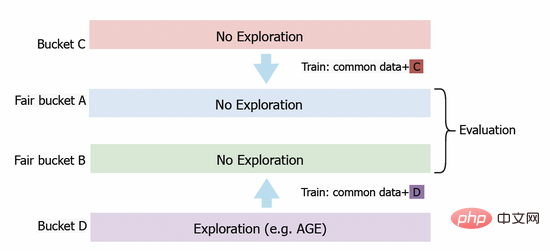
我們也將AGE模型部署到阿里媽媽展示廣告系統中,為了準確評估模型的探索價值,我們設計了基於公平桶的評測方法。如圖三所示,我們首先設定桶C和桶D用於收集資料。在桶D中,我們部署AGE等探索演算法,而在桶C中,我們採用不做探索的常規CTR模型。經過一段時間之後,我們將桶C和桶D所獲得的回饋資料分別應用於公平桶A和B上部署模型的訓練。最終,我們將比較公平桶A和B上的模型效果。在線上實驗中,我們使用幾個標準指標進行評估,包括點擊率CTR、被探索廣告的展現數量PV和預測CTR與真實CTR之比PCOC。此外,我們還引入了一個用於衡量廣告主的滿意度的商業指標(AFR)。
圖三:公平桶實驗方案
如表3所示,上述指標都得到了有效的提升。其中,AGE明顯優於所有其他方法:CTR和PV分別比基線模型高6.4%和3.0%。同時AGE模型的使用也提升了模型的預測精度,即預估準度PCOC更接近1。更重要的是,AFR指標也有5.5%的提升,這顯示我們的探索方法可以有效提升廣告主的體驗。
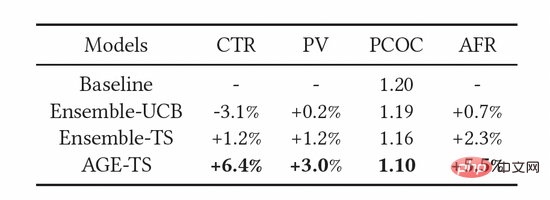
表3:線上實驗結果
與大多數專注於估計潛在回報的探索&利用方法不同,我們的方法AGE從線上學習的數據驅動的角度重新建構了這個問題。除了可以估計目前模型預測的不確定度外,AGE演算法借助擬探索模組,更進一步考慮探索樣本對模型訓練的後續影響。我們在學術研究資料集和生產鏈路都進行了A/B測試實驗,相關結果都證實了AGE方法的有效性。今後我們將AGE部署於更多的應用程式場景中。
以上是基於對抗梯度的探索模型及其在點擊預估中的應用的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















