

近日,阿里雲機器學習PAI關於大模型稀疏訓練的論文《Parameter-Efficient Sparsity for Large Language Models Fine-Tuning》被人工智慧頂會IJCAI 2022接收。
論文提出了一種參數高效的稀疏訓練演算法PST,透過分析權重的重要性指標,得出了其擁有兩個特性:低秩性和結構性。根據這個結論,PST演算法引入了兩組小矩陣來計算權重的重要性,相較於原本需要與權重一樣大的矩陣來保存和更新重要性指標,稀疏訓練需要更新的參數量大大減少。比較常用的稀疏訓練演算法,PST演算法可以在僅更新1.5%的參數的情況下,達到相近的稀疏模型精度。
近年來各大公司和研究機構提出了各式各樣的大模型,這些大模型擁有的參數從百億級別到萬億級別不等,甚至於已經出現十萬億級別的超大模型。這些模型需要耗費大量的硬體資源進行訓練和部署,導致它們面對著難以落地應用的困境。因此,如何減少大模型訓練和部署所需的資源成為了一個急需解決的問題。
模型壓縮技術可以有效的減少模型部署所需的資源,其中稀疏透過移除部分權重,使得模型中的計算可以從稠密計算轉換為稀疏計算,從而達到減少記憶體佔用,加快計算速度的效果。同時,稀疏相比於其他模型壓縮方法(結構化剪枝/量化),可以在確保模型精度的情況下達到更高的壓縮率,更適合擁有大量參數的大模型。
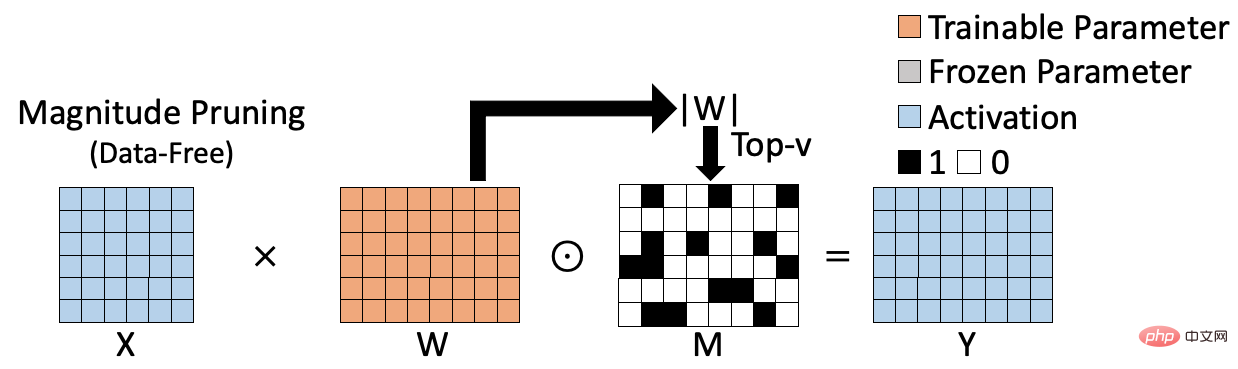
現有的稀疏訓練手段可以分為兩類,一類是基於權重的data-free稀疏演算法;一類是基於資料的data -driven稀疏演算法。基於權重的稀疏演算法如下圖所示,如magnitude pruning[1],透過計算權重的L1範數來評估權重的重要性,並基於此產生對應稀疏結果。基於權重的稀疏演算法計算高效,無需訓練資料參與,但是計算出來的重要性指標不夠準確,進而影響最終稀疏模型的精確度。
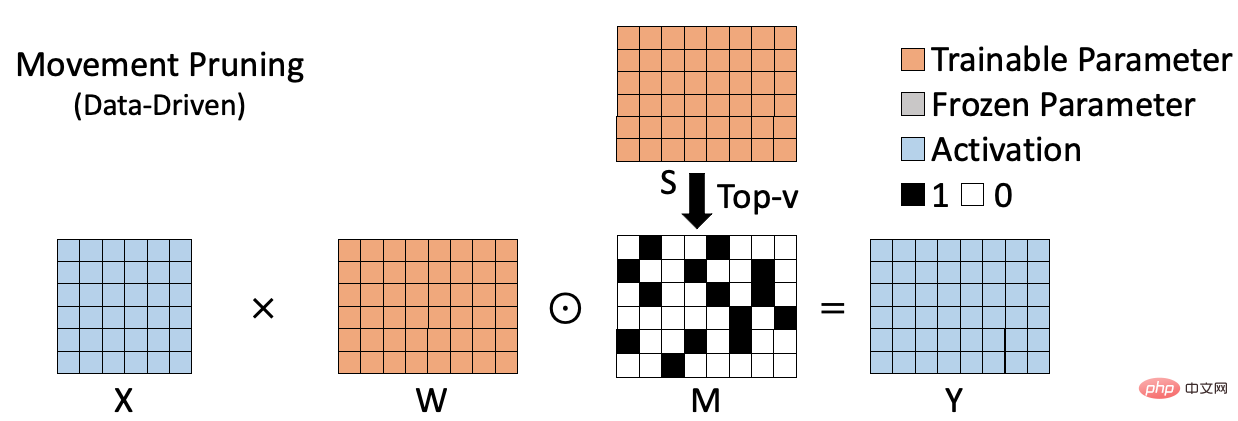
基於資料的稀疏演算法如下圖所示,如movement pruning[2],透過計算權重和對應梯度的乘積作為衡量權重重要性的指標。這類方法考慮了權重在具體資料集上的作用,因此能夠更準確的評估權重的重要性。但由於需要計算並保存各個權重的重要性,因此這類方法往往需要額外的空間來儲存重要性指標(圖中S)。同時相較於基於權重的稀疏方法,往往計算過程更加複雜。這些缺點隨著模型的規模變大,會變得更加明顯。
綜上所述,之前的稀疏演算法要麼高效但是不夠準確(基於權重的演算法),要麼準確但是不夠高效(基於數據的演算法)。因此我們期望提出一種高效的稀疏演算法,能夠準確且高效的對大模型進行稀疏訓練。
基於資料的稀疏演算法的問題是它們一般會引入額外的與權重相同大小的參數來學習權重的重要性,這讓我們開始思考如何減少引入的額外參數來計算權重的重要性。首先,為了能夠最大化利用已有資訊來計算權重的重要性,我們將權重的重要性指標設計成以下公式:
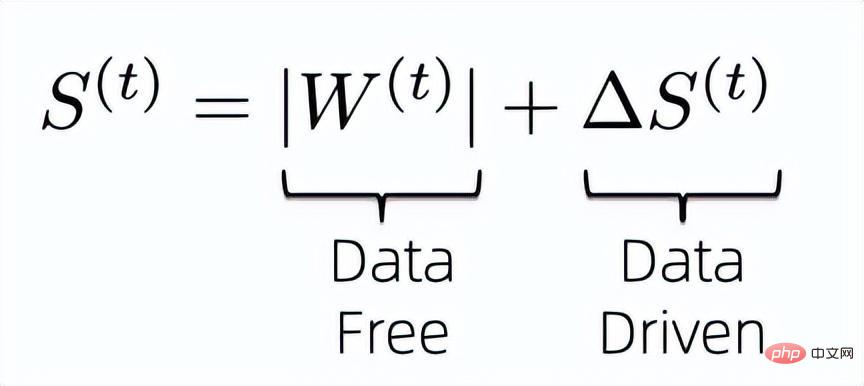
即我們結合了data-free和data-driven的指標來共同決定最終模型權重的重要性。已知前面data-free的重要性指標無需額外的參數來保存且計算高效,因此我們需要解決的就是如何壓縮後面那項data-driven重要性指標所引入的額外訓練參數。
基於先前的稀疏演算法,data-driven重要性指標可以設計成

,因此我們開始分析透過該公式計算出來的重要性指標的冗餘性。首先,基於先前的工作已知,權重和對應的梯度均具有明顯的低秩性[3,4],因此我們可以推導出此重要性指標也具有低秩性,因此我們可以引入兩個低秩小矩陣來表示原始與權重一樣大的重要性指標矩陣。
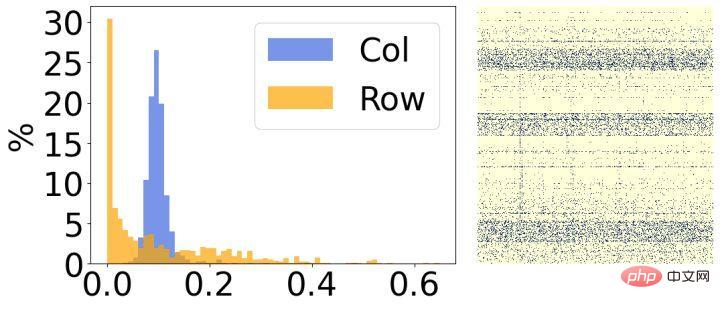
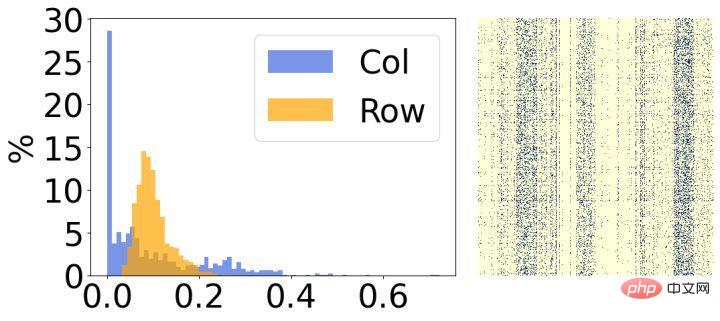
其次,我們分析了模型稀疏後的結果,發現它們具有明顯的結構性特徵。如上圖所示,每張圖的右邊是最終稀疏權重的視覺化結果,左邊是統計每一行/列對應稀疏率的直方圖。可以看出,左邊圖有30%的行中的大部分權重都被移除了,反之,右邊圖有30%的列中的大部分權重都被移除了。基於這樣的現象,我們引入了兩個小結構化矩陣來評估權重每一行/列的重要性。
基於上述的分析,我們發現data-driven的重要性指標存在低秩性和結構性,因此我們可以將其轉換成如下表示:
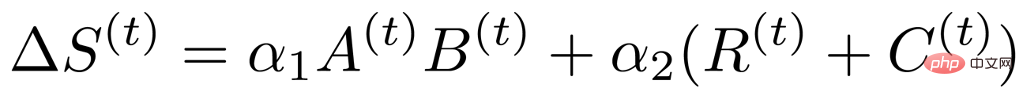
#其中A和B表示低秩性,R和C表示結構性。透過這樣的分析,原本和權重一樣大的重要性指標矩陣就被分解成了4個小矩陣,從而大大減少了參與稀疏訓練的訓練參數。同時,為了進一步減少訓練參數,我們基於先前的方法將權重的更新也分解成了兩個小矩陣U和V,因此最後的重要性指標公式變成如下形式:
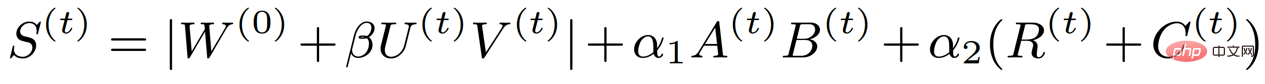
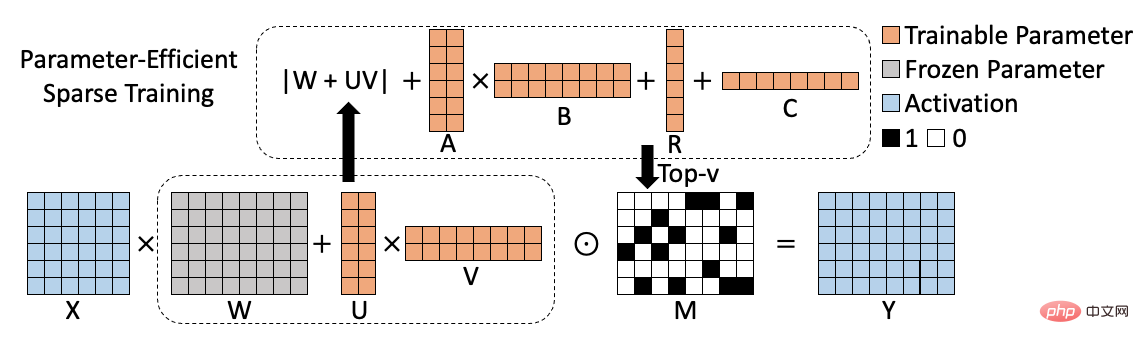
對應演算法框架圖如下所示:
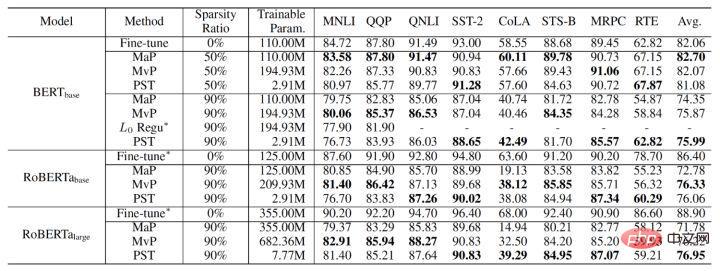
#最終PST演算法實驗結果如下,我們在NLU(BERT、RoBERTa)和NLG(GPT-2)任務上與magnitude pruning和movement pruning進行比較,在90%的稀疏率下,PST可以在大部分數據集上達到與之前算法相當的模型精度,但是僅需1.5%的訓練參數。

PST技術已經整合在阿里雲機器學習PAI的模型壓縮庫,以及Alicemind平台大模型稀疏訓練功能中。為阿里巴巴集團內部落地使用大模型帶來了性能加速,在百億大模型PLUG上,PST相比於原本的稀疏訓練可以在模型精度不下降的情況下,加速2.5倍,內存佔用減少10倍。目前,阿里雲機器學習PAI已被廣泛應用於各行各業,提供AI開發全鏈路服務,實現企業自主可控的AI方案,全面提升機器學習工程效率。
論文名稱:Parameter-Efficient Sparsity for Large Language Models Fine-Tuning
論文作者:Yuchao Li , Fuli Luo , Chuanqi Tan , Mengdi Wang , Songfang Huang , Shen Li , Junjie Bai
論文pdf連結:https://arxiv.org/pdf/2205.11005.pdf
#以上是這種精確度高,消耗資源少的大模型稀疏訓練方法找到了的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















