

譯者 | 李睿
審校 | 孫淑娟
可以想像一下,你正準備和朋友一起下西洋棋,但他不是人類,而是一個不了解##遊戲規則的電腦程式。 但這個應用程式卻明白自己致力實現一個目標,就是在遊戲中獲 勝。
因為電腦程式不知道規則,所以開始下棋的招數是隨機的。其中有些招數完全沒有意義,而對你來說獲勝很容易。 在這裡假設你非常喜歡和這個朋友下西洋棋,以至於沉迷於這個遊戲。
但電腦程式最終會贏,因為它會逐漸學會擊敗你的方法和招數字。 雖然假設的這個場景看起來有些牽強,但它應該能讓你對強化學習(機器學習的一個領域)的大致工作原理有一個基本的了解。

人類智力包含許多特徵,包括獲得知識、擴展智力能力的願望和直覺思考。當西洋棋冠軍加里·卡斯帕羅夫在輸給IBM公司的一台名為「深藍」(Deep Blue)的電腦時,人類的智慧受到了極大的質疑。除了吸引大眾的注意力之外,描繪機器人在未來統治人類的世界末日場景也佔據了主流意識。
然而,「深藍」並不是一個普通的對手。與這個計算程式下棋就像是與一個千歲的老#人進行比賽,而他一生一直在#不停地下西洋棋。但「深藍」擅長玩一種特定的遊戲,而不是其他智性活動,如演奏樂器、撰寫著作、進行科學實驗、養育子女或修理汽車。
這絕不是想貶#低「深藍色」 取得的成就。 與其相反,電腦在智力能力上超越人類的想法需要仔細的檢驗,首先要分析強化學習的工作機制。
強化學習是如何運作的#如##上所述,強化學習是機器學習的子集,它涉及智慧代理在環境中如何行動以最大化累積獎勵的概念。 簡單地說,強化學習機器人接受獎懲機制的訓練,它們做出正確的動作會得到獎勵,做出錯誤的動作會受到懲罰。 強化學習機器不會「思考」如何採取更的行動, 強化學習的缺點 強化學習的主要缺點是它需要大量的資源來實現它的目標。強化學習在圍棋遊戲中的成功就說明了這一點。這是一款受歡迎的雙人遊戲,目標是使用棋子在棋盤上佔據最大區域,同時避免丟子。 AlphaGo Master是一款在圍棋比賽中擊敗人類棋手的電腦程序,它耗費大量的資金和人力,其中包括許多工程師,非常豐富的遊戲經驗以及256個GPU和128000個CPU。 在學習如何在比賽獲勝的過程中,需要投入大量的資源和精力。這就引出了一個問題:設計不能憑直覺思考的人工智慧是否合理?人工智慧研究不是應該嘗試模仿人類智慧嗎? 量子強化學習 強化學習是一個新興的領域,據說可以解決上述的一些問題。量子強化學習(QRL)是一種加速運算的方法。 首先,量子強化學習(QRL)應該透過最佳化探索(發現策略)和開發(選擇最佳策略)階段來加速學習。目前的一些應用和提出的量子計算改進了數據庫搜索,將大數分解為質數,等等。 強化學習的商業案例 #強化學習的能力可能是有限的,但它不會被高估。此外,隨著強化學習研究和開發專案的增加,幾乎每個經濟部門的潛在用例也在增加。 大規模採用強化學習依賴幾個因素,其中包括最佳化演算法設計、配置學習環境和運算能力的可用性。 原文標題:#Is reinforcement learning overhyped? ,作者:Aleksandras Šulženko 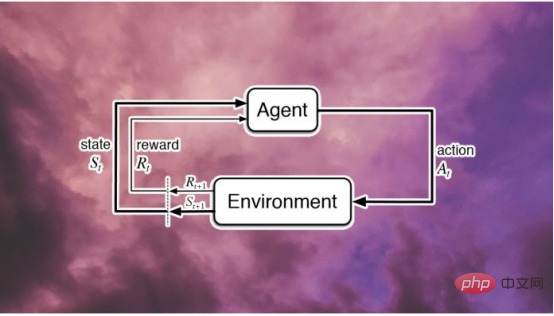
強化學習的反思
以上是強化學習是否言過其實?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















