


論文主要探討的是, 為什麼過參數的神經網路模型還能有不錯的泛化性?即不是簡單記憶訓練集,而是從訓練集中總結出一個通用的規律,從而可以適配於測試集(泛化能力)。

以經典的決策樹模型為例, 當樹模型學習資料集的通用規律時:一種好的情況,假如樹第一個分裂節點時,剛好就可以很好區分開不同標籤的樣本,深度很小,相應的各葉子上面的樣本數是夠的(即統計規律的數據量的依據也是比較多的),那這會得到的規律就更有可能泛化到其他數據。 (即:擬合良好, 有泛化能力)。
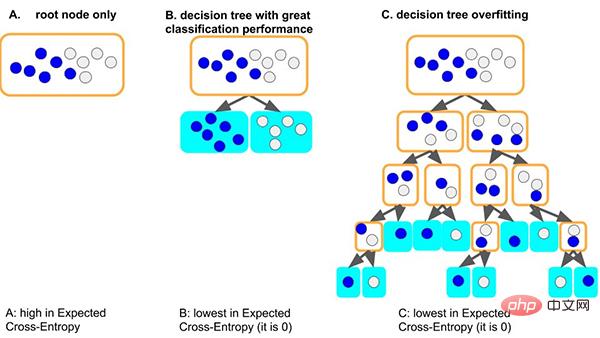
另外一種較差的情況,如果樹學習不好一些通用的規律,為了學習這個資料集,那樹就會越來越深,可能每個葉子節點分別對應著少數樣本(少數據帶來統計資料可能只是雜訊),最後,死記硬背地記住所有資料(即:過擬合無泛化能力)。我們可以看到過深(depth)的樹模型很容易過度擬合。
那麼過參數化的神經網路如何達到良好的泛化性呢?
本文是從一個簡單通用的角度解釋-在神經網路的梯度下降優化過程上,探討泛化能力的原因:
我們總結了梯度相干理論:來自不同樣本的梯度產生相干性,是神經網路能有良好的泛化能力原因。當不同樣本的梯度在訓練過程中對齊良好,即當它們相干時,梯度下降是穩定的,可以很快收斂,並且由此產生的模型可以有良好的泛化性。否則,如果樣本太少或訓練時間過長,可能無法泛化。

基於這個理論,我們可以做出以下解釋。
更寬的神經網路模型具有良好的泛化能力。這是因為,更寬的網絡都有更多的子網絡,對比小網絡更有產生梯度相干的可能,從而有更好的泛化性。換句話說,梯度下降是優先考慮泛化(相干性)梯度的特徵選擇器,更廣泛的網路可能僅僅因為它們有更多的特徵而具有更好的特徵。
但是個人覺得,這還是要區分下網路輸入層/隱藏層的寬度。特別是資料探勘任務的輸入層,由於輸入特徵是通常是人工設計的,需要考慮下做下特徵選擇(即減少輸入層寬度),不然直接輸入特徵噪音,對於梯度相干性影響不也是有乾擾的。
越深的網絡,梯度相干現像被放大,有更好的泛化能力。

在深度模型中,由於層之間的回饋加強了有相干性的梯度,因此存在相干性梯度的特徵(W6)和非相干梯度的特徵( W1)之間的相對差異在訓練過程中呈指數放大。從而使得更深的網路更偏好相干梯度,從而更好地泛化能力。
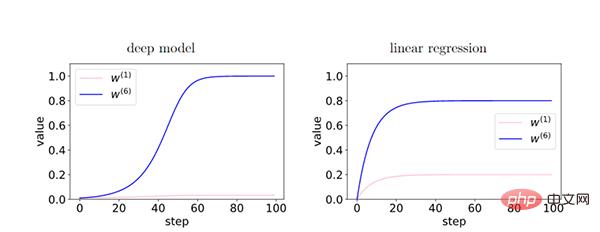
透過早停我們可以減少非相干梯度的過度影響,提高泛化性。
在訓練的時候,有些容易樣本比其他樣本(困難樣本)更早擬合。訓練前期,這些容易樣本的相干梯度做主導,並且很容易擬合。訓練後期,以困難樣本的非相干梯度主導了平均梯度g(wt),從而導致泛化能力變差,這個時候就需要早停。

我們發現全梯度下降也可以有很好的泛化能力。此外,仔細的實驗顯示隨機梯度下降並不一定有更優的泛化,但這並不排除隨機梯度更容易跳出局部最小值、起正則化等的可能性。
#我們認為較低的學習率可能無法降低泛化誤差,因為較低的學習率意味著更多的迭代次數(與早停相反)。
目標函數加入L2、L1正則化,對應的梯度計算, L1正規項需增加的梯度為sign(w) ,L2梯度為w。以L2正規為例,對應的梯度W(i 1)更新公式為:圖片
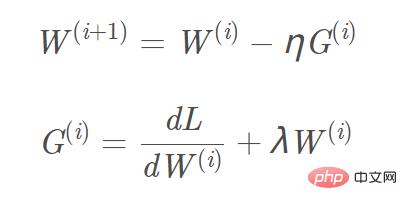
我們可以把「L2正則化(權重衰減)」看成是一種“背景力”,可將每個參數推近於資料無關的零值( L1容易得到稀疏解,L2容易得到趨近0的平滑解) ,來消除在弱梯度方向上影響。只有在相干梯度方向的情況下,參數才比較能脫離“背景力”,並基於數據完成梯度更新。

Momentum 、Adam等梯度下降演算法,其參數W更新方向不僅由目前的梯度決定,也與先前累積的梯度方向有關(即,保留累積的相干梯度的作用)。這使得參數中那些梯度方向變化不大的維度可以加速更新,並減少梯度方向變化較大的維度上的更新幅度,由此產生了加速收斂和減小震盪的效果。
我們可以透過最佳化批次梯度下降演算法,來抑制弱梯度方向的梯度更新,進一步提高了泛化能力。例如,我們可以使用梯度截斷(winsorized gradient descent),排除梯度異常值後的再取平均值。或取梯度的中位數代替平均值,以減少梯度異常值的影響。

文末說兩句,對於深度學習的理論,有興趣可以看下論文提及的相關研究。
以上是一文淺談深度學習泛化能力的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















