

CLIP(Contrastive Language-Image Pre-training)是一種機器學習技術,它可以準確地理解和分類圖像和自然語言文本,這對圖像和語言處理具有深遠的影響,並且已經被用作流行的擴散模型DALL-E的底層機制。在這篇文章中,我們將介紹如何調整CLIP來輔助影片搜尋。
這篇文章將不深入研究CLIP模型的技術細節,而是展示CLIP的另一個實際應用(除了擴散模型外)。
首先我們要知道:CLIP使用圖像解碼器和文字編碼器來預測資料集中哪些圖像與哪些文字是匹配的。

透過使用來自hugging face的預訓練CLIP模型,我們可以建立一個簡單而強大的視訊搜尋引擎,並且具有自然語言能力,而且不需要進行特徵工程的處理。
我們需要用到以下的軟體
Python≥= 3.8,ffmpeg,opencv
透過文字搜尋影片的技術有很多。我們可以將搜尋引擎將由兩個部分組成,索引和搜尋。
影片索引通常涉及人工和機器過程的結合。人類透過在標題、標籤和描述中添加相關關鍵字來預處理視頻,而自動化過程則是提取視覺和聽覺特徵,例如物體檢測和音頻轉錄。使用者互動指標等等,這樣可以記錄影片的哪些部分是最相關的,以及它們保持相關性的時間。所有這些步驟都有助於建立影片內容的可搜尋索引。
索引過程的概述如下
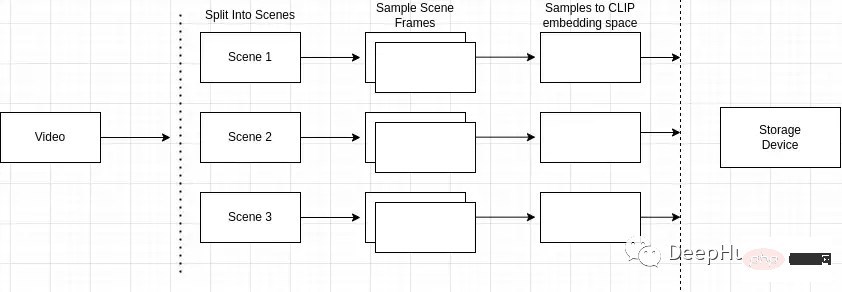
為什麼場景偵測很重要?影片由場景組成,而場景由相似的幀組成。如果我們只對影片中的任意場景進行採樣,可能會錯過整個影片中的關鍵影格。
所以我們就需要準確地辨識和定位影片中的特定事件或動作。例如,如果我搜尋“公園裡的狗”,而我正在搜尋的影片包含多個場景,例如一個男人騎自行車的場景和一個公園裡的狗的場景,場景檢測可以讓我識別出與搜尋查詢最接近的場景。
可以使用「scene detect」python套件來進行這個操作。
mport scenedetect as sd video_path = '' # path to video on machine video = sd.open_video(video_path) sm = sd.SceneManager() sm.add_detector(sd.ContentDetector(threshold=27.0)) sm.detect_scenes(video) scenes = sm.get_scene_list()
然後就需要使用cv2對影片進行幀採樣。
import cv2 cap = cv2.VideoCapture(video_path) every_n = 2 # number of samples per scene scenes_frame_samples = [] for scene_idx in range(len(scenes)): scene_length = abs(scenes[scene_idx][0].frame_num - scenes[scene_idx][1].frame_num) every_n = round(scene_length/no_of_samples) local_samples = [(every_n * n) + scenes[scene_idx][0].frame_num for n in range(3)] scenes_frame_samples.append(local_samples)
在收集樣本之後,我們需要將它們計算成CLIP模型可用的東西。
首先需要將每個樣本轉換為影像張量嵌入。
from transformers import CLIPProcessor
from PIL import Image
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def clip_embeddings(image):
inputs = clip_processor(images=image, return_tensors="pt", padding=True)
input_tokens = {
k: v for k, v in inputs.items()
}
return input_tokens['pixel_values']
# ...
scene_clip_embeddings = [] # to hold the scene embeddings in the next step
for scene_idx in range(len(scenes_frame_samples)):
scene_samples = scenes_frame_samples[scene_idx]
pixel_tensors = [] # holds all of the clip embeddings for each of the samples
for frame_sample in scene_samples:
cap.set(1, frame_sample)
ret, frame = cap.read()
if not ret:
print('failed to read', ret, frame_sample, scene_idx, frame)
break
pil_image = Image.fromarray(frame)
clip_pixel_values = clip_embeddings(pil_image)
pixel_tensors.append(clip_pixel_values)下一步就是平均同一場景中的所有樣本,這樣可以降低樣本的維數,而且還可以解決單一樣本中存在雜訊的問題。
import torch
import uuid
def save_tensor(t):
path = f'/tmp/{uuid.uuid4()}'
torch.save(t, path)
return path
# ..
avg_tensor = torch.mean(torch.stack(pixel_tensors), dim=0)
scene_clip_embeddings.append(save_tensor(avg_tensor))這樣就獲得了一個CLIP嵌入的表示影片內容的的張量清單。
對於底層索引存儲,我們使用LevelDB(LevelDB是由Google維護的鍵/值庫)。我們搜尋引擎的架構將包括3 個獨立的索引:
我們將首先將影片中所有計算出的元資料以及影片的唯一標識符,插入到元資料索引中,這一步都是現成的,非常簡單。
import leveldb
import uuid
def insert_video_metadata(videoID, data):
b = json.dumps(data)
level_instance = leveldb.LevelDB('./dbs/videometadata_index')
level_instance.Put(videoID.encode('utf-8'), b.encode('utf-8'))
# ...
video_id = str(uuid.uuid4())
insert_video_metadata(video_id, {
'VideoURI': video_path,
})然後在場景嵌入索引中建立一個新條目保存影片中的每個像素嵌入,還需要一個唯一的識別碼來識別每個場景。
import leveldb
import uuid
def insert_scene_embeddings(sceneID, data):
level_instance = leveldb.LevelDB('./dbs/scene_embedding_index')
level_instance.Put(sceneID.encode('utf-8'), data)
# ...
for f in scene_clip_embeddings:
scene_id = str(uuid.uuid4())
with open(f, mode='rb') as file:
content = file.read()
insert_scene_embeddings(scene_id, content)最後,我們需要保存哪些場景屬於哪個影片。
import leveldb
import uuid
def insert_video_scene(videoID, sceneIds):
b = ",".join(sceneIds)
level_instance = leveldb.LevelDB('./dbs/scene_index')
level_instance.Put(videoID.encode('utf-8'), b.encode('utf-8'))
# ...
scene_ids = []
for f in scene_clip_embeddings:
# .. as shown in previous step
scene_ids.append(scene_id)
scene_embedding_index.insert(scene_id, content)
scene_index.insert(video_id, scene_ids)現在我們有了一個將影片的索引,下面就可以根據模型輸出對它們進行搜尋和排序。
第一步需要遍歷場景索引中的所有記錄。然後,建立一個影片中所有影片和匹配場景id的清單。
records = []
level_instance = leveldb.LevelDB('./dbs/scene_index')
for k, v in level_instance.RangeIter():
record = (k.decode('utf-8'), str(v.decode('utf-8')).split(','))
records.append(record)下一步需要收集每個影片中存在的所有場景嵌入張量。
import leveldb
def get_tensor_by_scene_id(id):
level_instance = leveldb.LevelDB('./dbs/scene_embedding_index')
b = level_instance.Get(bytes(id,'utf-8'))
return BytesIO(b)
for r in records:
tensors = [get_tensor_by_scene_id(id) for id in r[1]]在我們有了組成影片的所有張量之後,我們可以把它傳遞到模型中。此模型的輸入是“pixel_values”,表示視訊場景的張量。
import torch
from transformers import CLIPProcessor, CLIPModel
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
inputs = processor(text=text, return_tensors="pt", padding=True)
for tensor in tensors:
image_tensor = torch.load(tensor)
inputs['pixel_values'] = image_tensor
outputs = model(**inputs)然後存取模型輸出中的「logits_per_image」獲得模型的輸出。
Logits本質上是對網路的原始非標準化預測。由於我們只提供一個文字字串和一個表示影片中的場景的張量,所以logit的結構將是一個單值預測。
logits_per_image = outputs.logits_per_image probs = logits_per_image.squeeze() prob_for_tensor = probs.item()
將每次迭代的機率相加,並在運算結束時將其除以張量的總數來獲得影片的平均機率。
def clip_scenes_avg(tensors, text): avg_sum = 0.0 for tensor in tensors: # ... previous code snippets probs = probs.item() avg_sum += probs.item() return avg_sum / len(tensors)
最后在得到每个视频的概率并对概率进行排序后,返回请求的搜索结果数目。
import leveldb
import json
top_n = 1 # number of search results we want back
def video_metadata_by_id(id):
level_instance = leveldb.LevelDB('./dbs/videometadata_index')
b = level_instance.Get(bytes(id,'utf-8'))
return json.loads(b.decode('utf-8'))
results = []
for r in records:
# .. collect scene tensors
# r[0]: video id
return (clip_scenes_avg, r[0])
sorted = list(results)
sorted.sort(key=lambda x: x[0], reverse=True)
results = []
for s in sorted[:top_n]:
data = video_metadata_by_id(s[1])
results.append({
'video_id': s[1],
'score': s[0],
'video_uri': data['VideoURI']
})就是这样!现在就可以输入一些视频并测试搜索结果。
通过CLIP可以轻松地创建一个频搜索引擎。使用预训练的CLIP模型和谷歌的LevelDB,我们可以对视频进行索引和处理,并使用自然语言输入进行搜索。通过这个搜索引擎使用户可以轻松地找到相关的视频,最主要的是我们并不需要大量的预处理或特征工程。
那么我们还能有什么改进呢?
可以在这里找到本文的代码:https://github.com/GuyARoss/CLIP-video-search/tree/article-01。
以及这个修改版本:https://github.com/GuyARoss/CLIP-video-search。
以上是使用CLIP建立影片搜尋引擎的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















