

arXiv論文“ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning“,22年7月,作者來自上海交大、上海AI實驗室、加州聖地亞哥分校和京東公司的北京研究院。

提出一種時空特徵學習方案,可以同時為感知、預測和規劃任務提供一組更具代表性的特徵,稱為ST-P3。具體而言,提出一種以自車為中心對齊(egocentric-aligned)的累積技術,在感知BEV轉換之前保留3-D空間中的幾何信息;作者設計一種雙路(dual pathway )模型,將過去的運動變化考慮在內,用於未來的預測;引入一個基於時域的細化單元,補償為規劃的基於視覺元素識別。原始碼、模型和協定詳細資料開源https://github.com/OpenPerceptionX/ST-P3.
開創性的LSS方法從多視圖攝影機中提取透視特徵,透過深度估計將其提升到3D,並融合到BEV空間。兩個視圖之間的特徵轉換,其潛深度預測至關重要。
將二維平面資訊提升到三維需要附加維度,也就是適合三維幾何自主駕駛任務的深度。為了進一步改進特徵表示,自然要將時域資訊合併到框架中,因為大多數場景的任務是視訊來源。
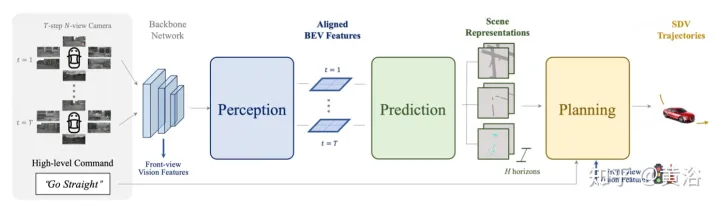
如圖描述ST- P3整體框架:具體來說,給定一組周圍的攝影機視頻,將其輸入主幹生成初步的前視圖特徵。執行輔助深度估計將2D特徵轉換到3D空間。以自車為中心對齊累積方案,首先將過去的特徵對齊到目前視圖座標系。然後在三維空間中聚合當前和過去的特徵,在轉換到BEV表示之前保留幾何資訊。除了常用的預測時域模型外,透過建構第二條路徑來解釋過去的運動變化,表現也進一步提升。這種雙路徑建模確保了更強的特徵表示,推斷未來的語義結果。為了實現軌跡規劃的最終目標,整合網路早期的特徵先驗知識。設計了一個細化模組,在不存在高清地圖的情況下,借助高級命令產生最終軌跡。
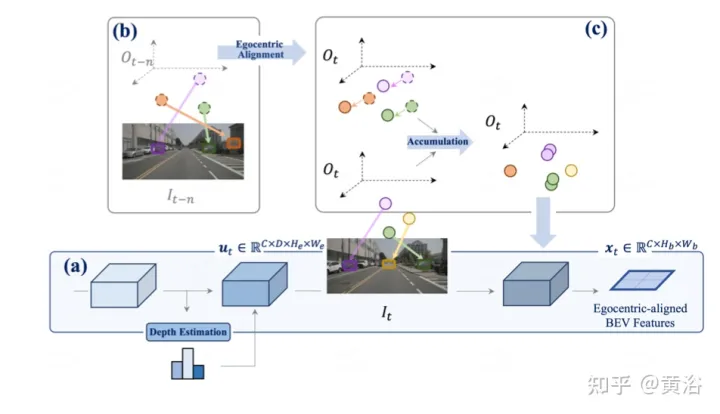
如圖是感知的以自我為中心對齊累計方法。 (a) 利用深度估計將當前時間戳處的特徵提升到3D,並在對齊後合併到BEV特徵;(b-c)將先前幀的3D特徵與當前幀視圖對齊,並與所有過去和當前狀態融合,從而增強特徵表示。
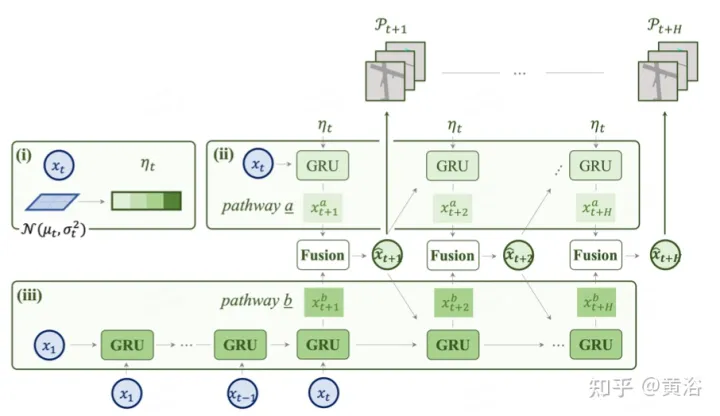
如圖是用於預測的雙路模型:(i) 潛碼是來自特徵圖的分佈;(ii iii)路a結合了不確定性分佈,指示未來的多模態,而路b從過去的變化中學習,有助於路a的資訊進行補償。
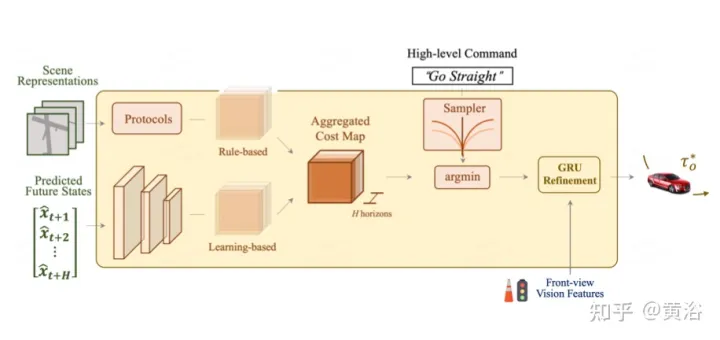
作為最終目標,需要規劃一條安全舒適的軌跡,到達目標點。這個運動規劃器對一組不同的軌跡進行取樣,並選擇一個最小化學習成本函數的軌跡。然而,透過一個時域模型來整合目標(target)點和交通燈的信息,加上額外的最佳化步驟。
如圖是為規劃的先驗知識整合與細化:總體成本圖包含兩個子成本。使用前視特徵進一步重新定義最小成本軌跡,從攝影機輸入中聚合基於視覺的資訊。
懲罰具有較大橫向加速度、急動或曲率的軌跡。希望這條軌跡能夠有效地到達目的地,因此向前推進的軌跡將會獎勵。然而,上述成本項不包含通常由路線地圖提供的目標(target)資訊。採用進階命令,包括前進、左轉和右轉,並且只根據相應的命令評估軌跡。
此外,交通號誌對SDV至關重要,透過GRU網路優化軌跡。以編碼器模組的前攝影機特徵初始化隱藏狀態,並以成本項的每個取樣點作為輸入。
實驗結果如下:
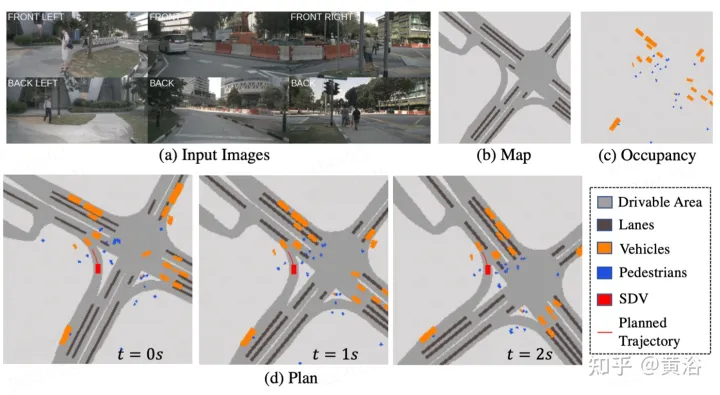
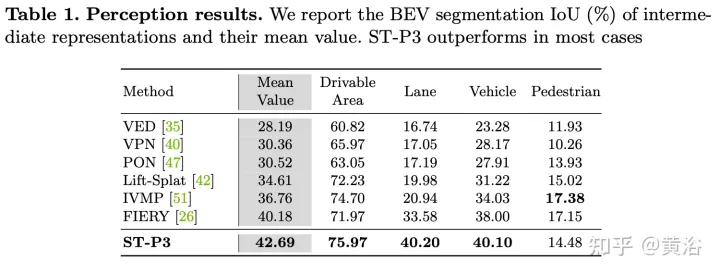
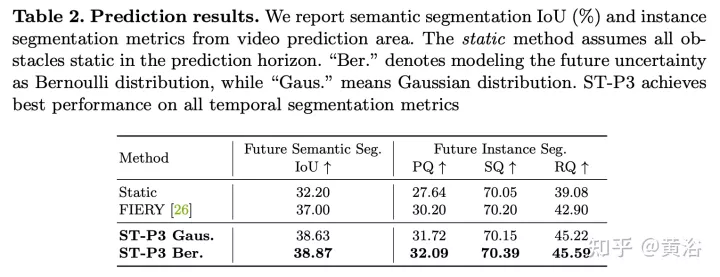
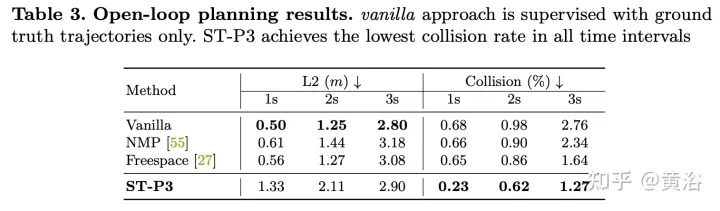
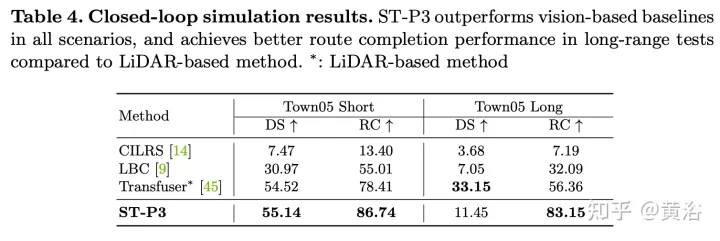
以上是ST-P3:端到端時空特徵學習的自動駕駛視覺方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















