

譯者| 李睿
審校| 孫淑娟
BigScience研究計畫日前發布了一個大型語言模型BLOOM,乍一看,它看起來像是複製OpenAI的GPT-3的另一個嘗試。
但BLOOM與其他大型自然語言模型(LLM)的不同之處在於,它在研究、開發、培訓和發布機器學習模型方面所做的努力。
近年來,大型科技公司將大型自然語言模式(LLM)就像嚴守商業機密一樣隱藏起來,而BigScience團隊從專案一開始就把透明與開放放在了BLOOM的中心。
其結果是一個大型語言模型,可供研究和學習,並可供所有人使用。 BLOOM所建立的開源和開放合作範例對大型自然語言模型(LLM)和其他人工智慧領域的未來研究非常有益。但仍有一些需要解決的大型語言模型固有的一些挑戰。
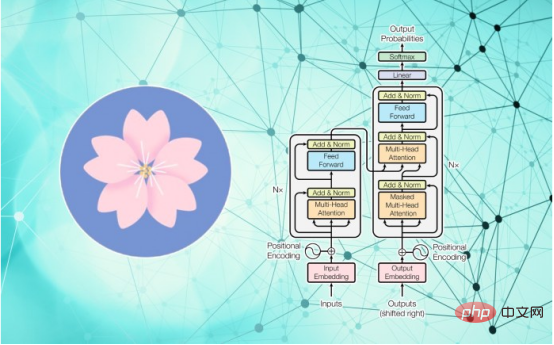
BLOOM是「BigScience大型開放科學開放取用多語言模型」的簡稱。從數據來看,它與GPT-3和OPT-175B並沒有太大的差別。它是一個非常大的Transformer 模型,擁有1760億個參數,使用1.6TB的資料進行訓練,其中包括自然語言和軟體原始碼。
與GPT-3一樣,它可以透過零鏡頭或少鏡頭學習執行許多任務,其中包括文字生成、摘要、問題回答和程式設計等。
但BLOOM的重要性在於背後的組織與建構過程。
BigScience是一個研究項目,由機器學習模型中心「Hugging Face」於2021年啟動。根據其網站的描述,該專案「旨在展示在人工智慧/自然語言處理研究社群內創建、學習和共享大型語言模型和大型研究工件的另一種方式。」
在這方面,BigScience從歐洲核子研究中心(CERN)和大型強子對撞機(LHC)等科學創造計劃中獲得了靈感,在這些計劃中,開放的科學合作促進了對整個研究社區有用的大規模人工製品的創造。
從2021年5月以來的一年裡,來自60個國家和250多個機構的1000多名研究人員在BigScience共同創造了BLOOM。
雖然大多數主要的大型自然語言模型(LLM)都只接受英語文本的訓練,但BLOOM的訓練語料庫包括46種自然語言和13種程式語言。這對於主要語言不是英語的許多地區都很有用。
BLOOM也打破了對大型科技訓練公司模型的實際依賴。大型自然語言模型(LLM)的主要問題之一是訓練和調整成本過高。這項障礙使得具有1000億個參數大型自然語言模型(LLM)成為擁有雄厚資金的大型科技公司的專屬領域。近年來,人工智慧實驗室被大型科技公司吸引,以獲得補貼的雲端運算資源,並為其研究提供資金。
相比之下,BigScience研究團隊獲得了法國國家科學研究中心的300萬歐元資助,用於在超級電腦Jean Zay上訓練BLOOM。而沒有任何協議授予商業公司這項技術的獨家許可,也沒有承諾將該模型實現商業化,並將其轉化為可獲利的產品。
此外,BigScience團隊對模型訓練的整個過程是完全透明的。他們發布了資料集、會議記錄、討論和程式碼,以及訓練模型的日誌和技術細節。
研究人員正在研究該模型的數據和元數據,並發布有趣的發現。
例如,研究人中David McClure於2022年7月12日在推特上表示,「我一直在研究來自Bigscience和Hugging Face的非常酷的BLOOM模型背後的訓練資料集。其中有來自英語語料庫的1000萬塊樣本,大約佔總數的1.25%、用'all-distilroberta-v1'編碼,然後從UMAP到2d。」
當然,經過訓練的模型本身可以在Hugging Face的平台上下載,這減輕了研究人員花費數百萬美元進行訓練的痛苦。
Facebook公上個月在一些限制下開源了其中一個大型自然語言模型(LLM)。然而,BLOOM帶來的透明度是前所未有的,並有望為該行業設立一個新的標準。
BLOOM訓練聯合負責人Teven LeScao表示,「與工業人工智慧研究實驗室的保密性相比,BLOOM證明了最強大的人工智慧模式可以由更廣泛的研究社群負責和開放的方式進行訓練和發布。」
雖然BigScience為人工智慧研究和大型語言模型帶來開放性和透明度的努力值得稱讚,但該領域固有的挑戰仍然沒有改變。
大型自然語言模型(LLM)研究正朝著越來越大的模型發展,這將進一步增加訓練和運行成本。 BLOOM使用384個Nvidia Tesla A100 GPU (每個價格約3.2萬美元)進行訓練。而更大的模型將需要更大的計算集群。 BigScience團隊已經宣布將繼續創建其他開源大型自然語言模型(LLM),但該團隊將如何為其日益昂貴的研究提供資金還有待觀察。例如,OpenAI最初是一家非營利組織,後來變成了一個銷售產品、依賴微軟資金的獲利性組織。
另一個有待解決的問題是運行這些模型的巨大成本。壓縮後的BLOOM模型的大小為227GB,運行它需要擁有數百GB記憶體的專用硬體。作為比較,GPT-3需要的計算集群相當於Nvidia DGX 2,其價格約為40萬美元。 「Hugging Face」計劃推出一個API平台,使研究人員能夠以每小時40美元左右的價格使用該模型,這是一筆不小的成本。
運行BLOOM的成本也將影響希望建構由大型自然語言模型(LLM)支持的產品的應用機器學習社群、新創公司和組織。目前,OpenAI提供的GPT-3API更適合產品開發。而了解BigScience和Hugging Face將朝哪個方向發展,使開發者能夠在其有價值的研究基礎上開發產品,這將成為一件有趣的事情。
在這方面,人們期待BigScience在未來發布的模型中有更小的版本。與媒體經常描述的相反,大型自然語言模型(LLM)仍然遵循「沒有免費的午餐」的原則。這意味著在應用機器學習時,一個針對特定任務進行微調的更緊湊的模型比一個在許多任務上具有平均性能的非常大的模型更有效。例如,Codex是GPT-3的一個修改版本,它以GPT-3的一小部分規模和成本為程式設計提供了很好的幫助。 GitHub目前提供以Codex為基礎的產品Copilot,每月收費10美元。
隨著BLOOM希望建立的新文化,而研究未來學術和應用人工智慧走向何方將是一件有趣的事情。
原文標題:#BLOOM can set a new culture for AI research—but challenges remain#,作者:Ben Dickson
以上是BLOOM可以為人工智慧研究創造一種新的文化,但挑戰依然存在的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















