


#模型可解釋性和可理解性一直是許多研究論文和開源專案的關注的重點。而且很多專案中都配備了資料專家和訓練有素的專業人員。
Shapash 適用於大多數 sklearn、lightgbm、xgboost、catboost 模型,並可用於分類和迴歸任務。它利用 Shap 後端來計算特徵的局部貢獻度,但是,這可以用其他一些計算局部貢獻度的策略來取代。資料科學家可以利用 Shapash 解釋器對他們的模型進行調查和故障排除,或部署以提供每個推測的可視化。並且它還可以用於製作可以為最終客戶和企業家帶來巨大價值的 Web 應用程式。

shabash 函式庫
繪圖與輸出使用每個元件及其模式的標籤:
資料科學家可以透過使用Web 應用程式輕鬆探索全域和局部鄰域之間的邏輯,從而快速理解他們的模型,並了解各種關鍵點如何發揮作用:
#shapash 庫webapp
Shapash 提出了一個簡短而清晰的解釋。它允許每個客戶(無論他們的背景是什麼),都能理解對託管模型清晰的解釋,因為對 Shapash 特徵進行了總結和清晰的說明。
這裡有完整的資料報告可以查看:https://shapash-demo.ossbymaif.fr/
Shapash 的一些功能如下所示:
1.機器學習模式:它適用於分類(二元或多類別問題)和迴歸問題。它支援多種模型,如 Catboost、Xgboost、LightGBM、Sklearn Ensemble、線性模型和 SVM。
2.特徵編碼:它支援大量的編碼技術來處理我們資料集中的分類特徵,如單熱編碼、序數編碼、Base N 編碼、目標編碼或二進位編碼等。
3.SklearnColumnTransformer: OneHotEncoder、OrdinalEncoder、StandardScaler、QuantileTransformer 或 PowerTransformer
# 4.視覺化: 提供一組視覺效果以輕鬆解釋你的結果,並顯示可理解和清晰的結果。
5.它與 Lime 和 Shap 相容。它使用 Shap 後端只需幾行程式碼即可顯示結果。
6.它為參數提供了許多選項,以簡潔地獲得結果。
7.Shapash 安裝簡單且使用方便: 它提供了一個 SmartExplainer 類別來理解你的模型並用簡單的語法總結澄清。
8.部署: 對於操作使用的調查和部署(透過 API 或批次模式)很重要。輕鬆建立 Web 應用程式以從全域導航到本機。
9.高度通用性:要顯示結果,需要進行非常多次的爭論。但如果你在清理和歸檔資料方面做得越多,最終客戶得到的結果就越清楚。
Shapash 是一個使機器學習易於理解和解釋的Python函式庫。數據愛好者可以輕鬆理解並分享他們的模型。 Shapash 使用 Lime 和 Shap 作為後端,只需幾行程式碼即可顯示結果。 Shapash 依賴於建立機器學習模型以使結果合理的各種重要進展。下圖顯示了 shapash 套件的工作流程:
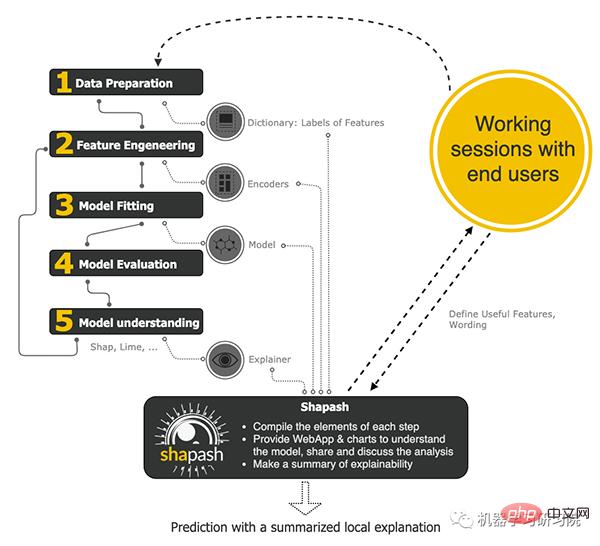
Shapash 是如何運作的
可以使用以下程式碼安裝Shapash:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">shapash</span>
對於Jupyter Notebook: 如果你正在使用jupyter notebook 並且想要查看內聯圖,那麼你需要使用另一個指令:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">ipywidgets</span>
在這裡我們將使用資料集房價預測來探索Shapash 。這是一個回歸問題,我們必須預測房價。首先我們分析資料集,包括單變量和雙變量分析,然後使用特徵重要性、特徵貢獻、局部和比較圖對可解釋性建模,然後是模型效能,最後是 WebApp。
單變數分析
使用可以查看下圖,了解名為First Floor Square Feet的要素。我們可以看到一個表格,其中顯示了我們的訓練和測試資料集的多種統計數據,例如平均值、最大值、最小值、標準差、中位數等等。在右側圖中可以看到訓練和測試資料集的分佈圖。 Shapash 也提到了我們的特徵是分類的還是數位的,它還提供了下拉選項,在下拉式選單中所有功能都可用。
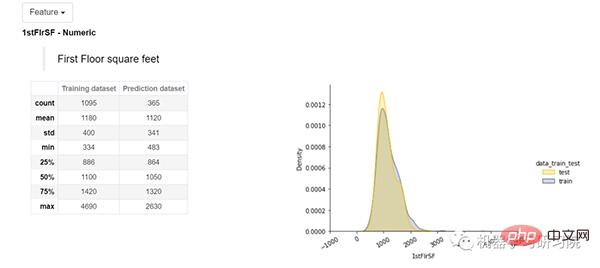
單變數分析
對於分類特徵,訓練和測試資料集顯示了非重複值和缺失值。在右側,顯示了一個長條圖,其中顯示了各要素中相應類別的百分比。
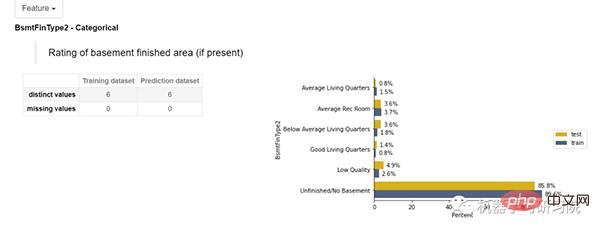
特徵中的類別
目標分析
也可以看到名為Sales Price 的目標變數的詳細分析。在左側,顯示了所有統計數據,如計數、平均值、標準差、最小值、最大值、中位數等,用於訓練和預測數據集。在右側,顯示了訓練和預測資料集的分佈。
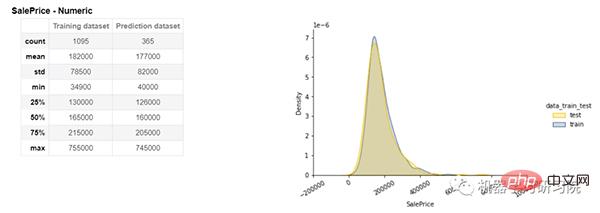
目標分析
多元變數分析
上面我們 詳細討論了單變數分析。在本節中,我們將看到多元分析。下圖顯示了訓練和測試資料集的前 20 個特徵的相關矩陣。也根據不同的顏色顯示了相關性標度。這就是我們如何使用 Shapash 視覺化特徵之間的關係。
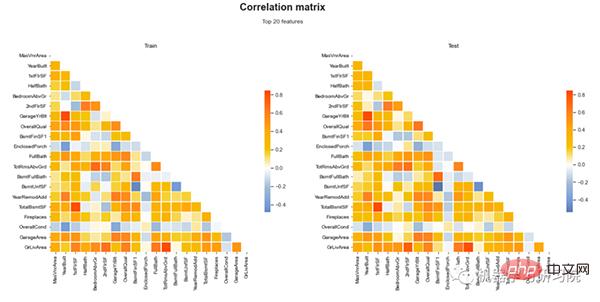
多元分析
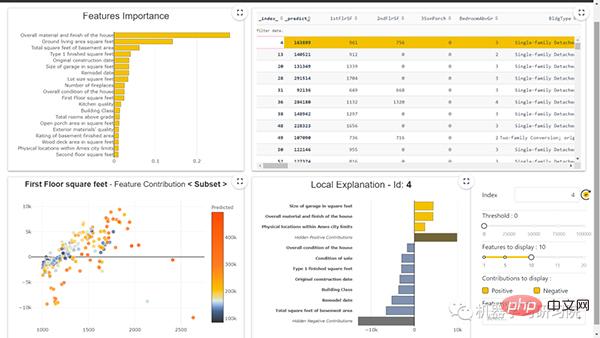
#特徵重要性圖
##透過使用這個庫,我們可以看到該特徵的重要性。特徵重要性是一種尋找輸入特徵在預測輸出值中的重要性的方法。下圖顯示了特徵重要性曲線: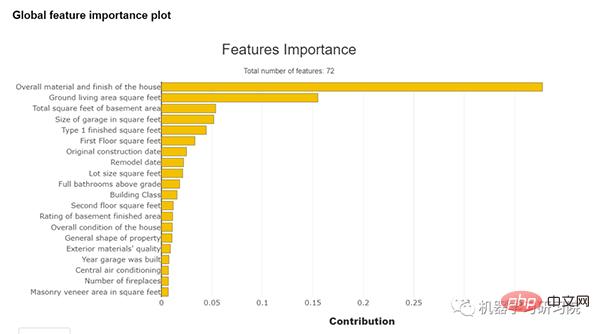
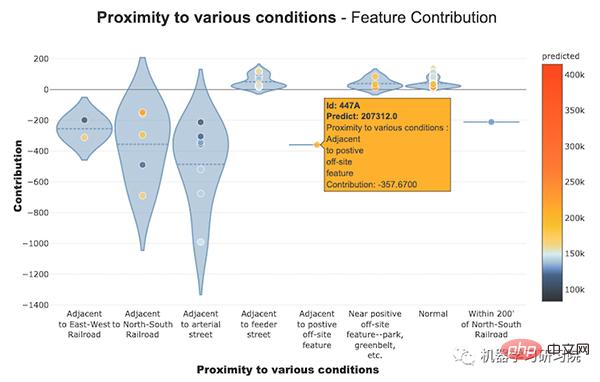
#特徵貢獻圖##這些曲線幫助我們回答諸如特徵如何影響我的預測、它的貢獻是正面的還是負面的等等。這個圖完成了模型的可解釋性的重要性,模型的整體一致性更有可能理解特徵對模型的影響。
我們可以看到數值和分類特徵的貢獻圖。
對於數值特徵
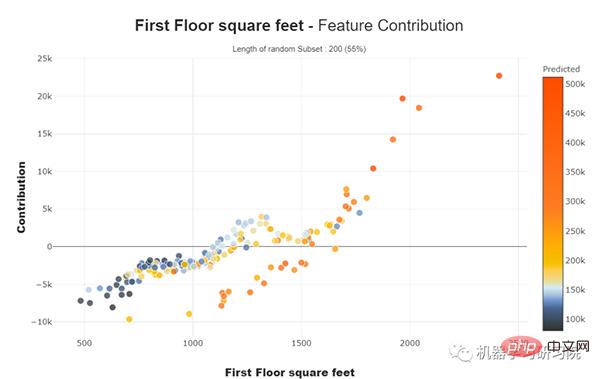 徵貢獻圖
徵貢獻圖
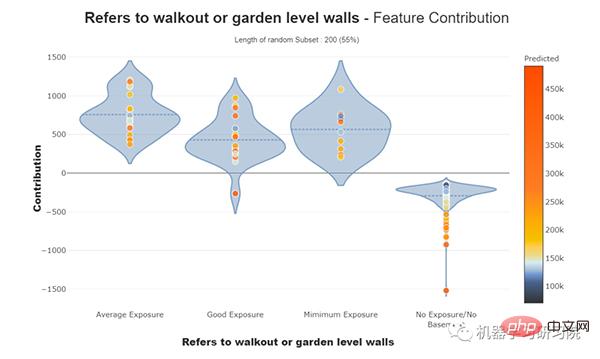 對於分類特徵
對於分類特徵
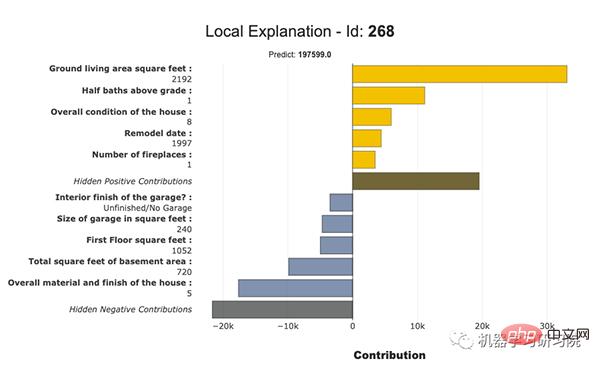
我們可以繪製局部圖。下圖顯示了局部圖:
局部圖
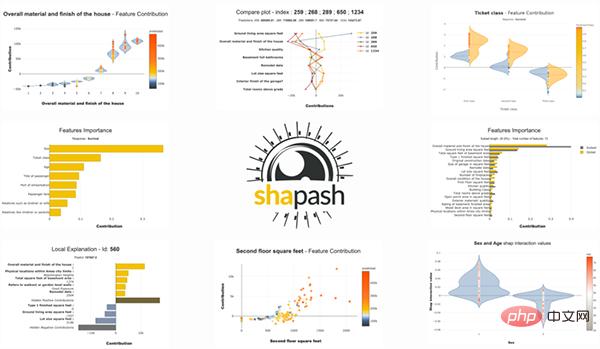
比較圖
我們可以繪製比較圖。下圖顯示了比較圖:
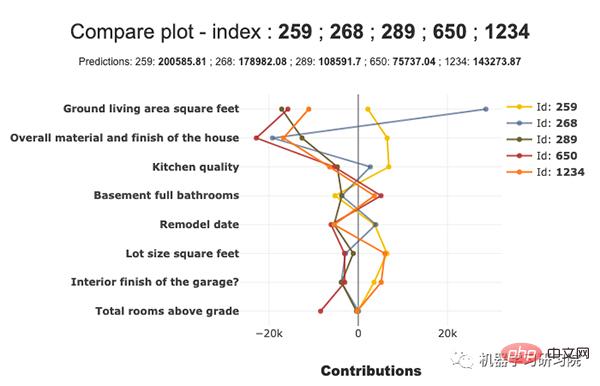
比較圖
在資料分析之後,我們正在訓練機器學習模型。下圖顯示了我們預測的輸出。在左側,顯示了真實值和預測值的統計數據,如計數、最小值、最大值、中位數、標準偏差等。在右側,顯示了預測值和實際值的分佈。
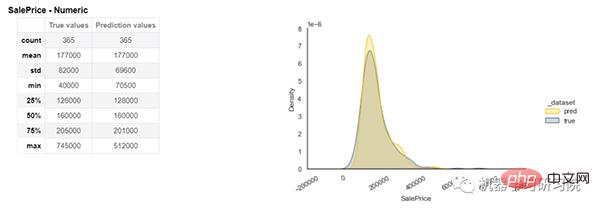
模型效能
經過模型訓練後,我們也可以建立一個WebApp。這個網路應用程式顯示了我們資料的完整儀表板,包括我們迄今為止所涵蓋的內容。下圖顯示了儀表板。
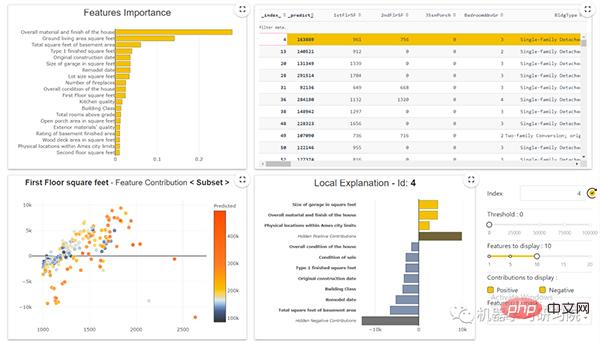
WebApp
專案位址:https://github.com/MAIF/shapash
本篇文章簡單介紹了shapash 的基本功能及繪圖展示,相信大家對該python函式庫有一定的認識。
以上是又一機器學習模型解釋神器:Shapash的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















