

arXiv論文“JPerceiver: Joint Perception Network for Depth, Pose and Layout Estimation in Driving Scenes“,上傳於22年7月,報道關於澳大利亞悉尼大學陶大程教授和北京京東研究院的工作。

深度估計、視覺測程計(VO)和鳥瞰圖(BEV)場景佈局估計是駕駛場景感知的三個關鍵任務,這是自主駕駛中運動規劃和導航的基礎。雖然相互補充,但通常側重於單獨的任務,很少同時處理這三個任務。
一種簡單的方法是以順序或並行的方式獨立地完成,但有三種缺點,即1)深度和VO結果受到固有的尺度多義問題的影響;2) BEV佈局通常單獨估計道路和車輛,而忽略明確疊加-下墊關係;3)雖然深度圖是用於推斷場景佈局的有用幾何線索,但實際上直接從前視圖影像預測BEV佈局,並沒有使用任何深度相關資訊。
本文提出一個共同感知框架JPerceiver來解決這些問題,從單眼視訊序列中同時估計尺度-覺察深度、VO以及BEV佈局。以跨視圖幾何變換(cross-view geometric transformation,CGT),根據精心設計的尺度損失,將絕對尺度從道路佈局傳播到深度和VO。同時,設計一個跨視圖和模態轉換(cross-view and cross-modal transfer,CCT)模組,用深度線索透過注意機制推理道路和車輛佈局。
JPerceiver以端到端的多任務學習方式進行訓練,其中CGT尺度損失和CCT模組促進任務間知識遷移,利於每個任務的特徵學習。
程式碼與模型可下載https://github.com/sunnyHelen/JPerceiver.
如圖所示,JPerceiver分別由深度、姿態和道路佈局三個網路組成,都基於編碼器-解碼器架構。深度網路旨在預測目前幀It的深度圖Dt,其中每個深度值表示3D點與相機之間的距離。姿態網路的目標是預測在當前幀It及其相鄰幀It m之間姿態變換Tt→t m。道路佈局網路的目標是估計目前影格的BEV佈局Lt,即俯視笛卡爾平面中道路和車輛的語意佔用率。這三個網路在訓練期間聯合優化。
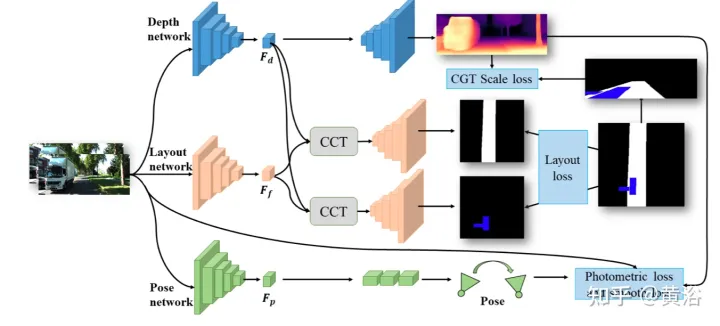
預測深度和姿態的兩個網路以自監督方式以光度損失和平滑度損失進行聯合最佳化。此外,也設計CGT尺度損失來解決單目深度和VO估計的尺度多義問題。
為實現尺度-覺察的環境感知,以BEV佈局中的尺度訊息,提出CGT的尺度損失用於深度估計和VO。由於BEV佈局顯示了BEV笛卡爾平面中的語意佔用,分別涵蓋自車前面Z米和左右(Z/2)米的範圍。其提供一個自然距離場(natural distance field)z,每個像素相對於自車的度量距離zij,如圖所示:
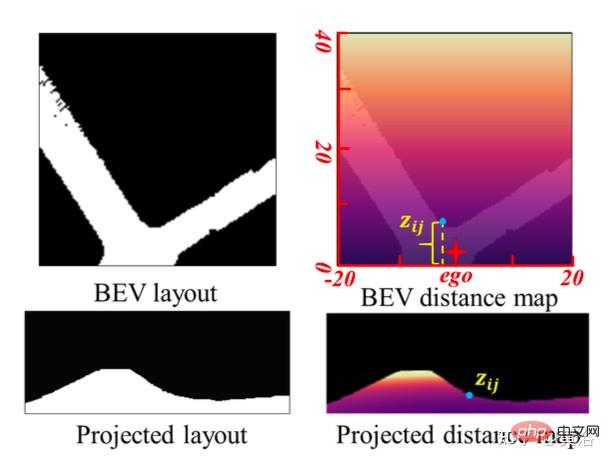
假設BEV平面是地面,其原點剛好在自車座標係原點下面,基於攝影機外參可以透過單應性變換將BEV平面投影到前向攝影機。因此,BEV距離場z可以投影到前向攝影機中,如上圖所示,用它來調節預測深度d,從而導出CGT尺度損失:
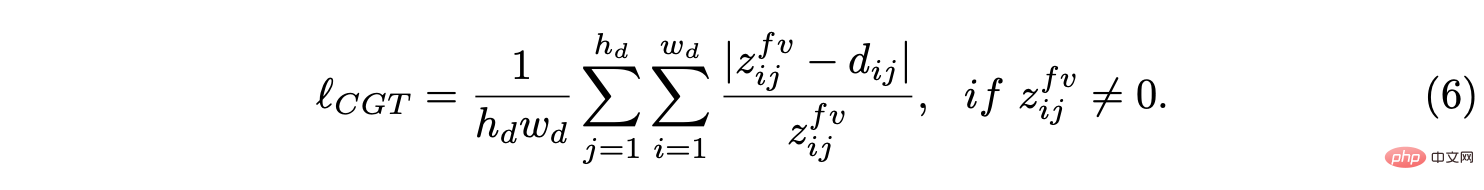
對於道路佈局估計,採用了編碼器-解碼器網路結構。值得注意的是,用一個共享編碼器作為特徵提取器和不同的解碼器來同時學習不同語義類別的BEV佈局。此外,設CCT模組,以加強任務間的特徵互動與知識遷移,並為BEV的空間推理提供3-D幾何資訊。為了正則化道路佈局網絡,將各種損失項組合在一起,形成混合損失,並實現不同類的平衡優化。
CCT是研究前向視圖特徵Ff、BEV佈局特徵Fb、重轉換的前向特徵Ff′和前向深度特徵FD之間的相關性,並相應地細化佈局特徵,如圖所示:分兩部分,即跨視圖模組和跨模態模組的CCT-CV和CCT-CM。
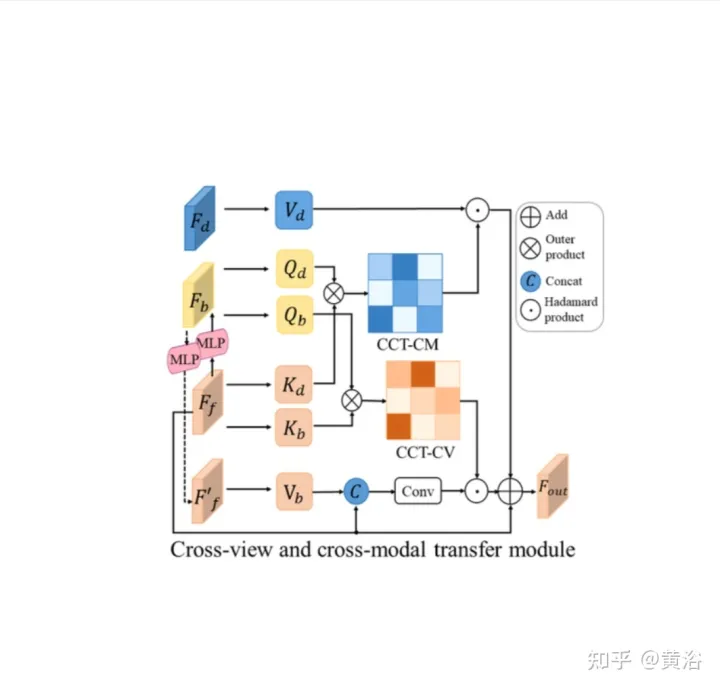
在CCT中,Ff和Fd由相應感知分支的編碼器提取,而Fb透過一個視圖投影MLP將Ff轉換為BEV獲得,一個循環損失約束的相同MLP將其重新轉換為Ff′。
在CCT-CV,交叉注意機制用於發現前向視圖和BEV特徵之間的幾何對應關係,然後指導前向視圖資訊的細化,並為BEV推理做好準備。為了充分利用前向視圖影像特徵,將Fb和Ff投影到patches:Qbi和Kbi,分別作為query和 key。
除了利用前向視圖特徵外,還部署CCT-CM來施加來自Fd的3-D幾何資訊。由於Fd是從前向視圖影像中提取的,因此以Ff為橋來減少跨模態間隙並學習Fd和Fb之間的對應關係是合理的。 Fd起Value的作用,由此獲得與BEV資訊相關有價值的3-D幾何訊息,並進一步提高道路佈局估計的準確性。
在探索同時預測不同版面的共同學習框架過程中,不同語意類別的特徵和分佈有很大差異。對於特徵,駕駛場景中的道路佈局通常需要連接,而不同的車輛目標必須分割。
對於分佈,觀察到的直線道路場景比轉彎場景多,這在真實資料集中是合理的。這種差異和不平衡增加了BEV佈局學習的難度,尤其是聯合預測不同類別,因為在這種情況下,簡單的交叉熵(CE)損失或L1損失會失效。將幾種分割損失(包括基於分佈的CE損失、基於區域的IoU損失和邊界損失)合併為混合損失,預測每個類別的佈局。
實驗結果如下:
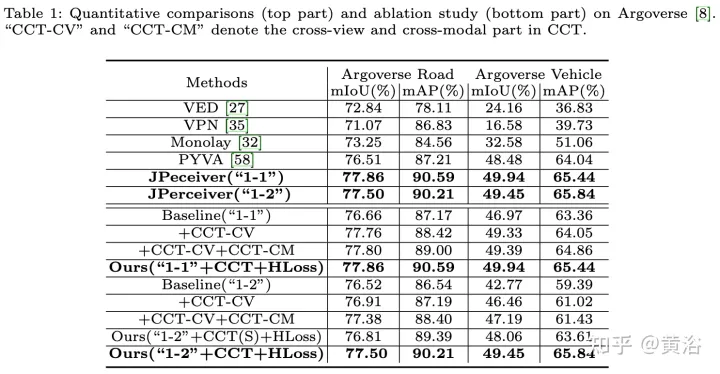
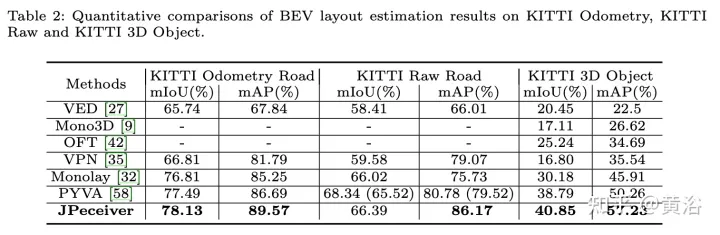
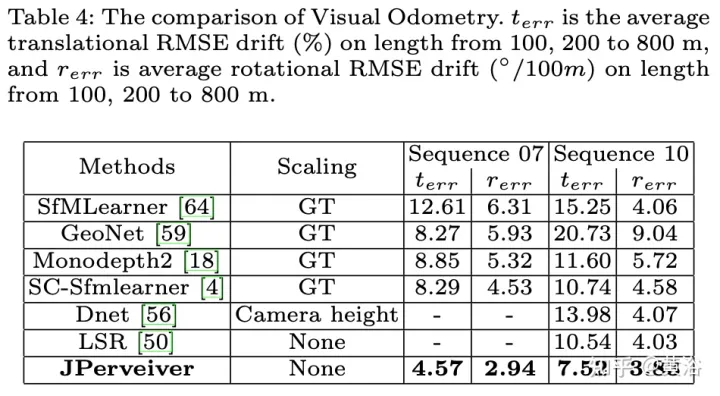
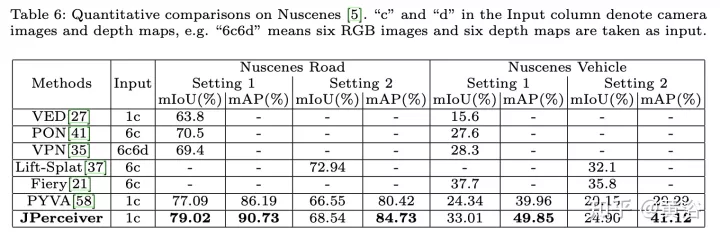
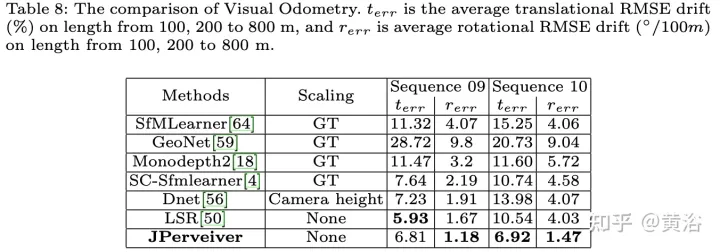
以上是聯合駕駛場景中深度、姿態和道路估計的感知網絡的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















