

arXiv論文“Unifying Voxel-based Representation with Transformer for 3D Object Detection“,22年6月,香港中文大學、香港大學、曠視科技(紀念孫劍博士)和思謀科技等。

本文提出一個統一的多模態3-D目標偵測框架,稱為UVTR。此方法旨在統一體素空間的多模態表示,實現準確、穩健的單模態或跨模態3-D檢測。為此,首先設計模態特定空間來表示體素特徵空間的不同輸入。在不進行高度資訊(height)壓縮的情況下保留體素空間,減輕語義歧義並實現空間交互作用。基於這種統一方式,提出跨模態交互,充分利用不同感測器的固有特性,包括知識遷移和模態融合。透過這種方式,可以很好地利用點雲的幾何-覺察表達式和影像中上下文豐富的特徵,獲得更好的性能和穩健性。
transformer解碼器用於從具備可學習位置的統一空間中高效取樣特徵,這有助於目標級互動。一般來說,UVTR代表在統一框架中表示不同模態的早期嘗試,在單模態和多模態輸入方面優於以往的工作,在nuScenes測試集上取得了領先的性能,激光雷達、相機和多模態輸出的NDS分別為69.7%、55.1%和71.1%。
程式碼:https://github.com/dvlab-research/UVTR.
如圖所示:
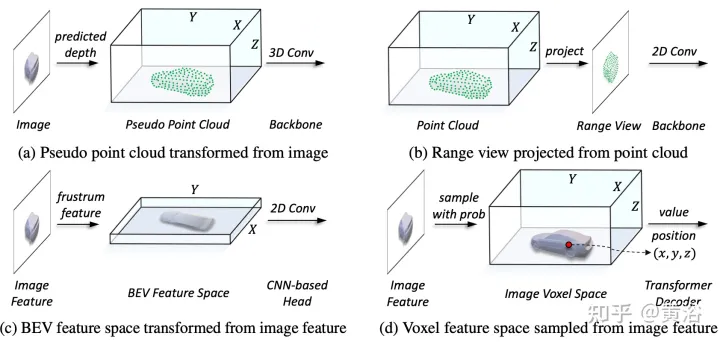
在表徵統一過程中,可以大致分為輸入級流和特徵級流的表示。對於第一種方法,多模態資料在網路開始時對齊。特別是,圖(a)中的偽點雲是從預測深度輔助的影像轉換而來的,而圖(b)中的距離視圖影像是從點雲投影而來的。由於偽點雲的深度不準確和距離視圖影像中的3-D幾何塌陷,資料的空間結構受到破壞,從而導致較差的結果。對於特徵級方法,典型的方法是將影像特徵轉換為截錐(frustum),然後壓縮到BEV空間,如圖(c)所示。然而,由於其類似射線的軌跡,每個位置的高度資訊(height)壓縮聚合了各種目標的特徵,因此引入了語義多義。同時,他隱式方式很難支援3-D空間中的顯式特徵交互,並限制進一步的知識遷移。因此,需要一種更統一的表示法來彌合模態的差距,並促進多方面的互動。
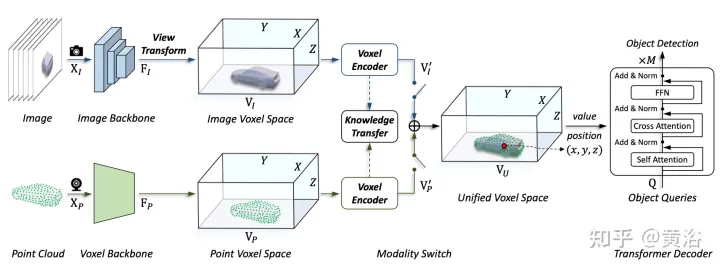
本文所提出的框架,將基於體素的表示與transformer統一。特別是,在基於體素的顯式空間中影像和點雲的特徵表徵和交互作用。對於影像,根據預測的深度和幾何約束,從影像平面採樣特徵來建構體素空間,如圖(d)所示。對於點雲,準確的位置自然允許特徵與體素相關聯。然後,引入體素編碼器進行空間交互,建立相鄰特徵之間的關係。這樣,跨模態交互作用自然地與每個體素空間的特徵進行。對於目標級交互,採用可變形transformer作為解碼器,對統一體素空間中每個位置(x、y、z)的目標查詢特定特徵進行取樣,如圖(d)所示。同時,3-D查詢位置的引入有效地緩解了BEV空間中高度資訊(height)壓縮帶來的語意多義。
如圖是多模態輸入的UVTR架構:給定單幀或多幀影像和點雲,首先在單一主幹處理,並將其轉換為特定於模態的空間VI和VP,其中視圖轉換用於影像。在體素編碼器中,特徵在空間上相互作用,並且 知識遷移在訓練期間易於支援。根據不同的設置,透過模態開關選擇單模態或多模態特徵。最後,從具備可學習位置的統一空間VU中取樣特徵,利用transformer解碼器進行預測。
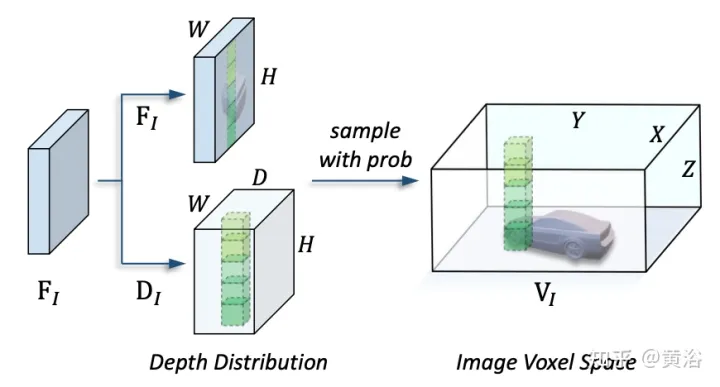
如圖是視圖變換的細節:
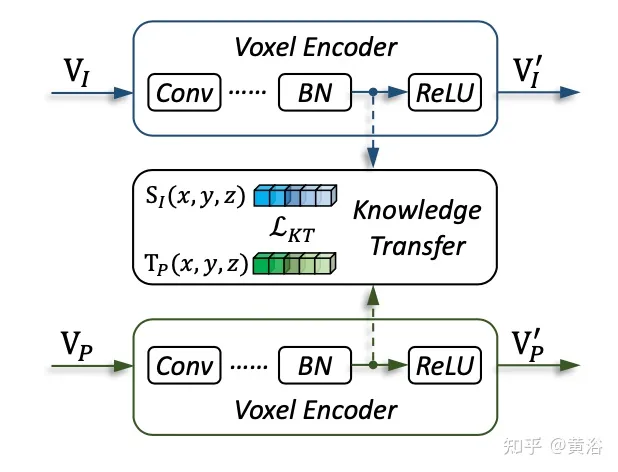
#如圖是知識遷移的細節:
實驗結果如下:
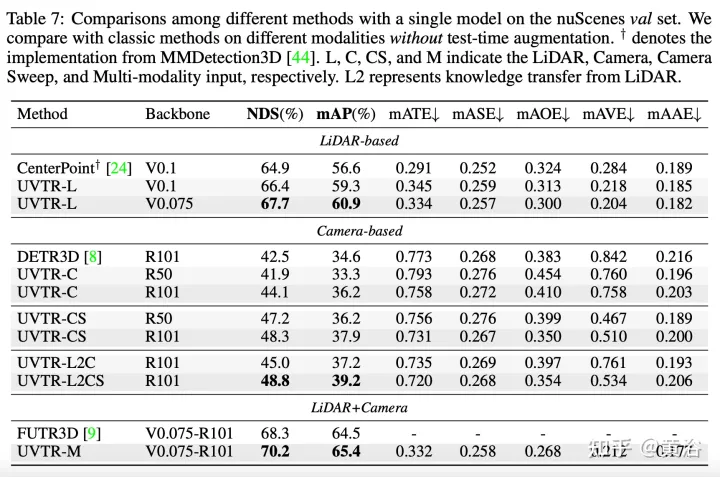
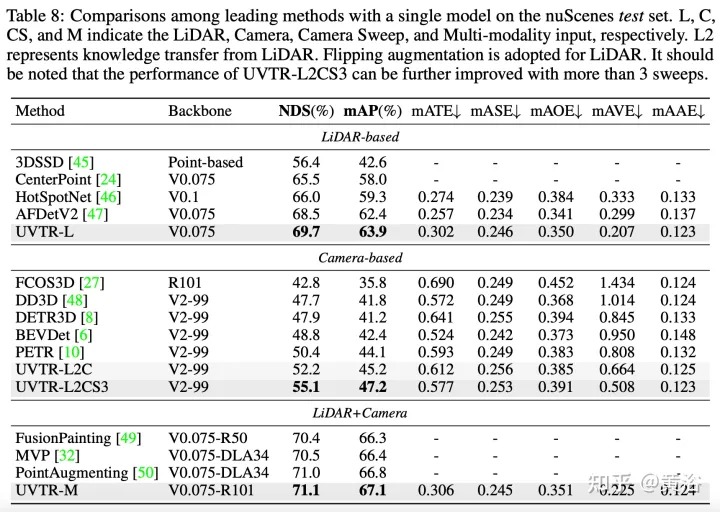
以上是Transformer統一化3D目標偵測基於體素的表徵的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















