

arXiv論文“ViP3D: End-to-end Visual Trajectory Prediction via 3D Agent Queries“,22年8月2日上傳,清華、上海(姚)期智研究院、CMU、復旦、理想汽車和MIT等的聯合工作。

現有的自主駕駛管線將感知模組與預測模組分開。這兩個模組透過人工選擇的特徵進行通信,如智體框和軌跡作為介面。由於這種分離,預測模組僅從感知模組接收部分資訊。更糟的是,來自感知模組的錯誤可能會傳播和累積,從而對預測結果產生不利影響。
這項工作提出ViP3D,一種視覺軌跡預測管線,利用原始影片的豐富資訊預測場景中智體的未來軌跡。 ViP3D在整個管線中使用稀疏智體query,使其完全可微分和可解釋。此外,提出一種新的端到端視覺軌跡預測任務的評估指標,端到端預測精度(EPA,End-to-end Prediction Accuracy),其在綜合考慮感知和預測精度的同時,對預測軌跡與地面真實軌跡進行評分。
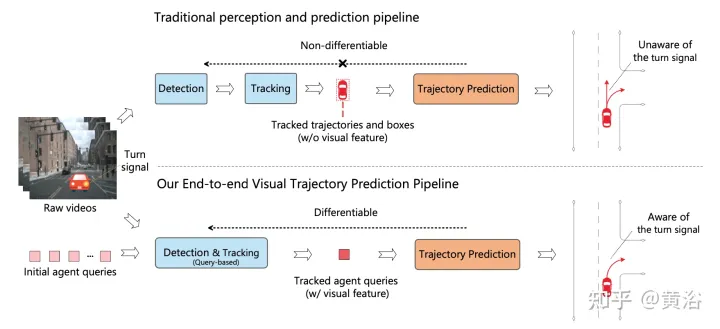
如圖是傳統多步驟級聯流水線與ViP3D的比較:傳統的管線涉及多個不可微模組,例如偵測、追蹤和預測;ViP3D將多視圖視訊作為輸入,以端到端的方式產生預測軌跡,可有效利用視覺訊息,例如車輛轉向訊號。
ViP3D旨在以端到端的方式解決原始影片的軌跡預測問題。具體而言,給定多視圖視訊和高清地圖,ViP3D預測場景中所有智體的未來軌跡。
ViP3D的整體流程如圖所示:首先,基於查詢的追蹤器處理來自周圍攝影機的多視圖視頻,獲得有視覺特徵所追蹤智體的query。智體query中的視覺特徵,捕捉智體的運動動力學和視覺特徵,以及智體之間的關係。之後,軌跡預測器將追蹤智體的query作為輸入,並與HD地圖特徵相關聯,最後輸出預測的軌跡。
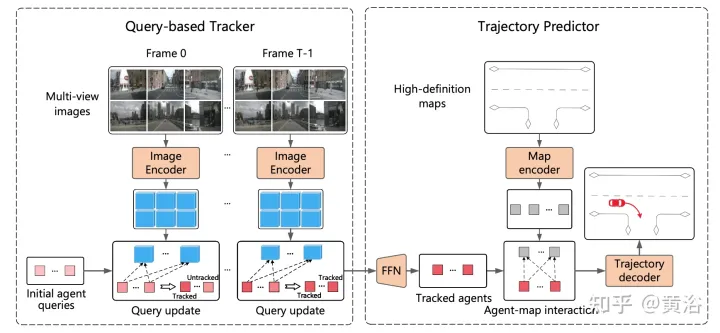
基於query的追蹤器從環繞攝影機的原始影片中提取視覺特徵。具體而言,對於每一幀,請按照DETR3D提取影像特徵。對於時域特徵聚合,依照MOTR(「Motr: End-to-end multiple-object tracking with transformer「. arXiv 2105.03247, 2021)設計了一個基於query的追蹤器,包括兩個關鍵步驟:query特徵更新和query監督。智體query會隨時間更新,建模智體的運動動力學。
大多數現有的軌跡預測方法可分為三個部分:智體編碼、地圖編碼和軌跡解碼。在基於query的追蹤之後,獲得被追蹤智體的query,該query可以被視為透過智體編碼獲得的智體特徵。因此,剩下的任務是地圖編碼和軌跡解碼。
分別將預測和真值智體表示為無序集Sˆ和S,其中每個智體由當前時間步的智體座標和K個可能的未來軌跡表示。對於每個智體類型c,計算Scˆ和Sc之間的預測精度。將預測智體和真值智體之間的成本定義為:

這樣Scˆ和Sc之間的EPA定義為:

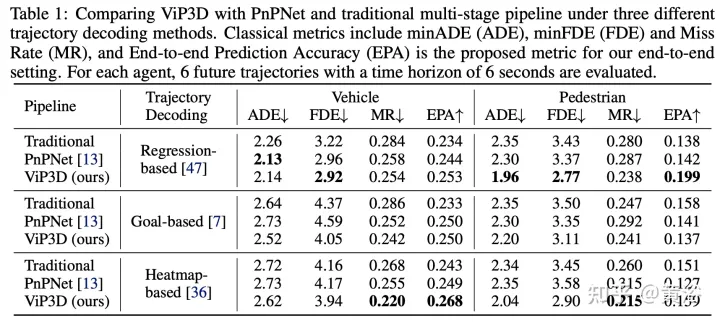
#實驗結果如下:
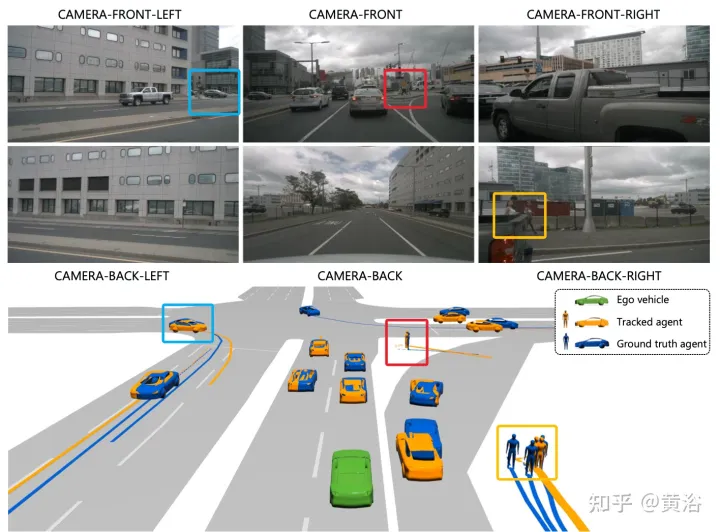
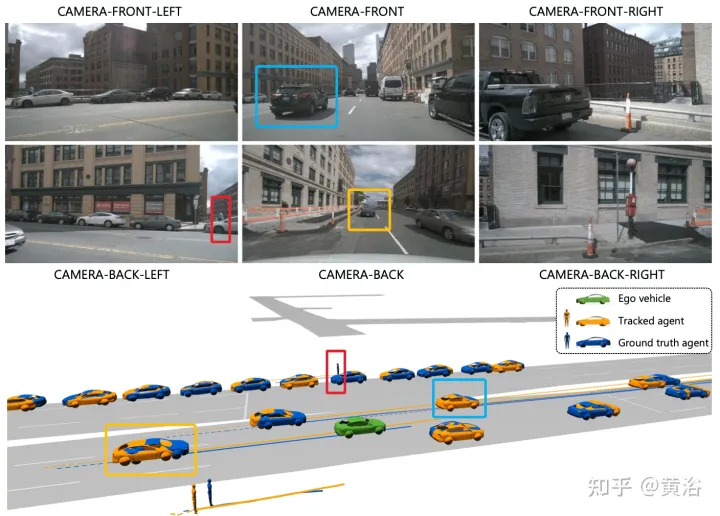
#註:這個目標渲染做的不錯。
以上是ViP3D: 透過3D智體query實現端到端視覺軌跡預測的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















