

在發布DALL·E的15個月後,OpenAI在今年春天帶了續作DALL·E 2,以其更加驚豔的效果和豐富的可玩性迅速佔領了各大AI社區的頭條。近年來,隨著生成對抗網路(GAN)、變分自編碼器(VAE)、擴散模型(Diffusion models)的出現,深度學習已向世人展現其強大的圖像生成能力;加上GPT-3、BERT等NLP模型的成功,人類正逐步打破文字與圖像訊息的界線。
在DALL·E 2中,只要輸入簡單的文字(prompt),它就可以產生多張1024*1024的高清影像。這些圖像甚至可以將不合常理的語義表示,以超現實主義的形式創造出天馬行空的視覺效果,例如圖1中「寫實風格的騎馬的太空人(An astronaut riding a horse in a photorealistic style)」。
 圖1. DALL·E 2生成範例
圖1. DALL·E 2生成範例
本文將深入解讀DALL·E等新範式如何透過文字創造出眾多驚人的圖像,文中涵蓋大量背景知識和基礎技術的介紹,同樣適合初涉影像生成領域的讀者。
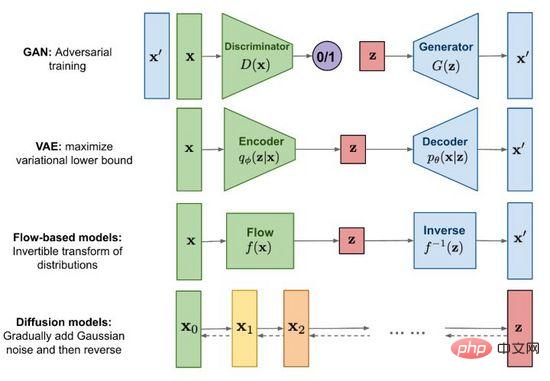
圖2.主流影像生成方法
自2014年生成對抗網路(GAN)誕生以來,影像生成研究成為了深度學習乃至整個人工智慧領域的重要前沿課題,現階段技術發展之強已達到以假亂真的程度。除了為人所知的生成對抗網絡(GAN),主流方法還包括變分自編碼器(VAE)和基於流的生成模型(Flow-based models),以及近期頗受關注的擴散模型(Diffusion models)。借助圖2我們探尋一下各個方法的特點和差異。
GAN的全名是 G enerative A# dversarial N etworks,從名稱不難唸出「對抗(Adversarial)」是其成功之精髓。對抗的想法受博弈論啟發,在訓練生成器(Generator)的同時,訓練一個判別器(Discriminator)來判斷輸入是真實圖像還是生成圖像,兩者在一個極小極大遊戲中相互博弈不斷變強,如式(1)。當從隨機雜訊產生足以「騙」過的影像時,我們認為較好地擬合出了真實影像的資料分佈,透過取樣可以產生大量逼真的影像。
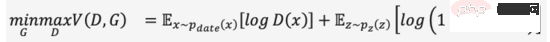
#GAN是生成式模型中應用最廣泛的技術,在影像、視訊、語音和NLP等眾多資料合成場景中大放異彩。除了直接從隨機雜訊產生內容外,我們還可以將條件(例如分類標籤)作為輸入加入生成器和判別器,使得產生結果符合條件輸入的屬性,讓生成內容得以控制。雖然GAN效果出眾,但由於博弈機制的存在,其訓練穩定性差且容易出現模式崩潰(Mode collapse),如何讓模型平穩地達到博弈均衡點,也是GAN的熱點研究話題。
變分自編碼器(Variational Autoencoder)是自編碼器的變體,傳統的自編碼器旨在以無監督的方式訓練一個神經網絡,完成將原始輸入壓縮成中間表示和將恢復成兩個過程,前者通過編碼器(Encoder)將原始高維輸入轉換為低維隱層編碼,後者通過解碼器(Decoder )從編碼中重建資料。不難看出,自編碼器的目標是學習一個恆等函數,我們可以使用交叉熵(Cross-entropy)或均方差(Mean Square Error)來建構重建損失量化輸入和輸出的差異。如圖3所示,在上述過程中我們獲得了低緯度的隱層編碼,它捕捉了原始資料的潛在屬性,可以用於資料壓縮和特徵表示。
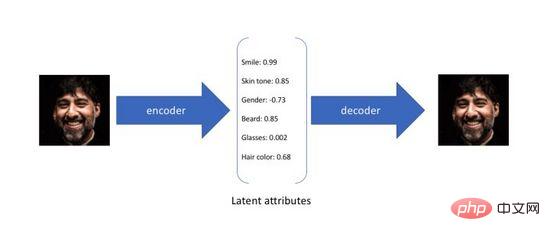
圖3. 自編碼器的潛在屬性編碼
由於自編碼器僅關注隱層編碼的重建能力,其隱層空間分佈往往是無規律且不均勻的,在連續的隱層空間隨機採樣或插值得到一組編碼通常會產生無意義和不可解釋的生成結果。為了建構一個規律的隱層空間,使得我們可以在不同潛在屬性上隨機地採樣和平滑地插值,最後透過解碼器產生有意義的圖像,研究者們在2014年提出了變分自編碼器。
變分自編碼器不再將輸入映射成隱層空間中的一個固定編碼,而是轉換成對隱層空間的機率分佈估計,為了方便表示我們假設先驗分佈是一個標準高斯分佈。同樣的,我們訓練一個機率解碼器建模,實現從隱層空間分佈到真實資料分佈的映射。當給定一個輸入,我們透過後驗分佈估計出關於分佈的參數(多元高斯模型的均值和協方差),並在此分佈上採樣,可使用重參數化技巧使採樣可導(為隨機變量) ,最後透過機率解碼器輸出關於的分佈,如圖4所示。為了讓生成影像盡量真實,我們需要解後驗分佈,目標是最大化真實影像的對數似然。
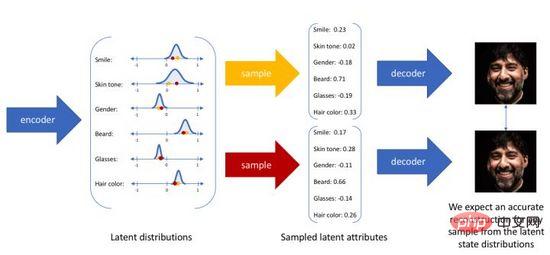
圖4. 變分自編碼器的取樣產生過程
遺憾的是,真實的後驗分佈根據貝葉斯模型包含對在連續空間上的積分,是不可直接解的。為了解決上述問題,變分自編碼器使用了變分推理的方法,引入一個可學習的機率編碼器去近似真實的後驗分佈,使用KL散度量兩個分佈的差異,將這個問題從求解真實的後驗分佈轉換為如何縮小兩個分佈之間的距離。
我們省略中間推導過程,將上式展開得到式(2),
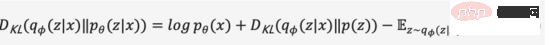
由於KL散度非負,我們可以將我們的最大化目標轉寫成式(3),
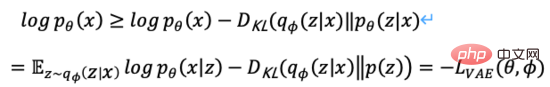
綜上,我們將關於機率編碼器和機率解碼器的定義為模型的損失函數,其負數形式稱為的證據下界(Evidence Lower Bound),最大化證據下界等效於最大化目標。上述變分過程是VAE及各種變體的核心思想,透過變分推理將問題轉化為最大化生成真實數據的證據下界。
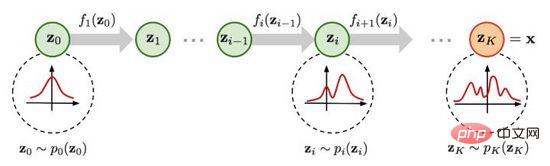
#圖5.基於流的生成過程
如圖5所示,假設原始資料分佈可以透過一系列可逆的轉換函數從已知分佈獲得,即。透過雅各布矩陣行列式和變數變化規則,我們可以直接估計真實資料的機率密度函數(式(4)),最大化可計算的對數似然。
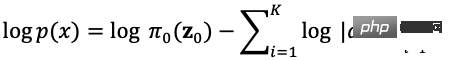
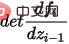 是轉換函數的雅各行列式,因此要求可逆之外還要求容易計算出其雅各布行列式。基於流的生成模型如Glow採用1x1可逆卷積進行精確的密度估計,在人臉生成上取得不錯的效果。
是轉換函數的雅各行列式,因此要求可逆之外還要求容易計算出其雅各布行列式。基於流的生成模型如Glow採用1x1可逆卷積進行精確的密度估計,在人臉生成上取得不錯的效果。

圖6. 擴散模型的擴散與逆向過程
擴散模型定義了正向和逆向兩個過程,正向過程或稱擴散過程是從真實資料分佈採樣,逐步向樣本添加高斯噪聲,生成噪聲樣本序列,加噪過程可用方差參數控制,當時,可近似等同於一個高斯分佈。其擴散過程是預設的可控過程,加噪過程可用條件分佈表示為式(5),
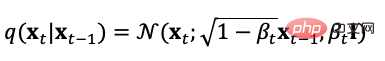
從擴散過程的定義可以看出,我們可以在任意步長上使用上式取樣,
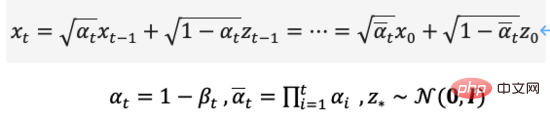
同樣我們也可以把擴散過程逆向,從高斯雜訊中取樣,學習一個模型來估計真實的條件機率分佈,因此逆向過程可定義為式(7),
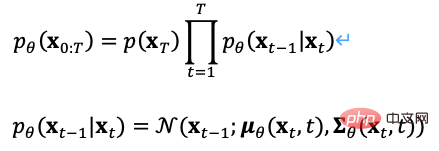
擴散模型的最佳化目標有多種選擇,例如在訓練過程中由於可以從正向過程直接計算,於是我們可以從預測的分佈中採樣,採樣過程可以加入影像分類和文字標籤作為條件輸入,以最小均方差優化重建損失,這個過程等效於自編碼器。
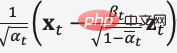
在去雜訊擴散機率模型DDPM中,作者透過重參數化技術建構了簡化版的雜訊預測模型損失(式(8)),在步長時輸入加噪資料 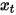 訓練模型去預測雜訊
訓練模型去預測雜訊 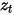 ,在推理過程中使用
,在推理過程中使用
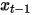
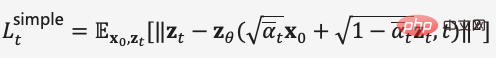
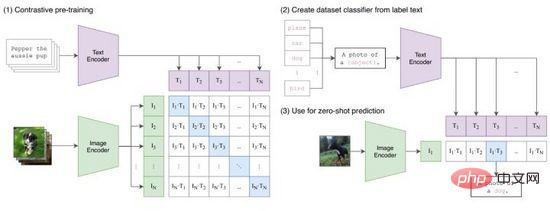
CLIP將文字和圖像的特徵表示映射到同一空間,雖然沒有實現跨模態的信息傳遞,但作為特徵壓縮、相似性度量和跨模態表示學習的方法,是十分有效的。直觀的,我們把圖像Tokens在標籤範圍生成的所有文本提示中與之特徵最相似的輸出,即完成了一次圖像分類(圖9(2)),特別當圖像和標籤的數據分佈未曾在訓練集出現過,CLIP仍有零樣本(zero-shot)學習的能力。
經過前面兩章的介紹,我們系統性地回顧了影像產生和多模態表示學習相關基礎技術,本章將介紹三個最新的跨模態影像生成方法,解讀它們如何使用這些基礎技術進行建模。
DALL·E由OpenAI在2021年初提出,旨在訓練一個輸入文字到輸出影像的自回歸解碼器。由CLIP的成功經驗可知,文字特徵和圖像特徵可以編碼在同一特徵空間中,因此我們可以使用Transformer將文字和圖像特徵自回歸建模為單一資料流(「autoregressively models the text and image tokens as a single stream of data」)。
DALL·E的訓練過程分成兩個階段,一是訓練一個變分自編碼器用於圖像編解碼,二是訓練一個文字和圖像的自回歸解碼器用於預測生成圖像的Tokens,如圖10所示。
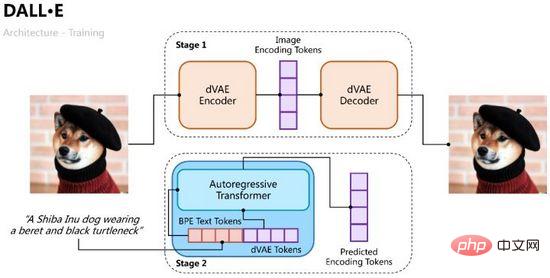
圖10. DALL·E的訓練過程
推理過程則比較直觀,將文字Tokens用自回歸Transformer逐步解碼出圖像Tokens,解碼過程中我們可以透過分類機率取樣多組樣本,再將多組樣本Tokens輸入變分自編碼中解碼出多張生成影像,並透過CLIP相似性計算排序擇優,如圖11所示。
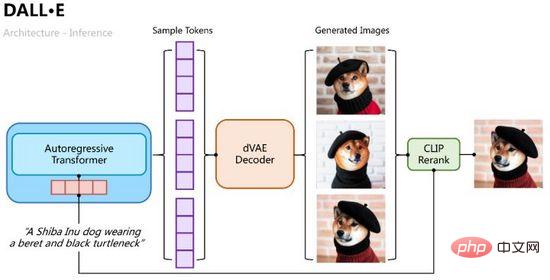
圖11. DALL·E的推理過程
#和VAE一樣我們用機率編碼器和機率解碼器,分別建模隱層特徵的後驗機率分佈和產生影像的似然機率分佈,使用建模由Transformer預測的文字和影像的聯合機率分佈作為先驗(在第一階段初始化為均勻分佈),同理可得優化目標的證據下界,
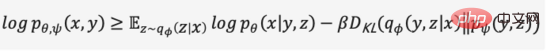
在第一階段的訓練過程中,DALL·E使用了一個離散變分自編碼器(Discrete VAE)簡稱dVAE,是Vector Quantized VAE(VQ -VAE)的升級版。在VAE中我們用一個機率分佈刻畫了連續的隱層空間,透過隨機取樣得到隱層編碼,但是這個編碼並不像離散的語言文字具有確定性。為了學習影像隱層空間的“語言”,VQ-VAE使用了一組可學習的向量量化表示隱層空間,這個量化的隱層空間我們稱為Embedding Space或Codebook/Vocabulary。 VQ-VAE的訓練過程與預測過程旨在尋找與影像編碼向量距離最近的隱層向量,再將映射得到的向量語言解碼成影像(圖12),損失函數由三個部分構成,分別優化重構損失、更新Embedding Space和更新編碼器,梯度終止。
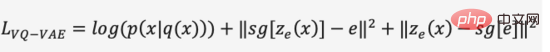
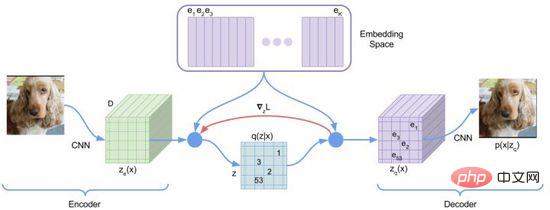
圖12. VQ-VAE
VQ-VAE由於最近鄰選擇假設使其後驗機率是確定的,即距離最近的隱層向量機率為1其餘為0,不具有隨機性;距離最近的向量選擇過程不可導,使用了straight-through estimator方法將的梯度傳遞給。
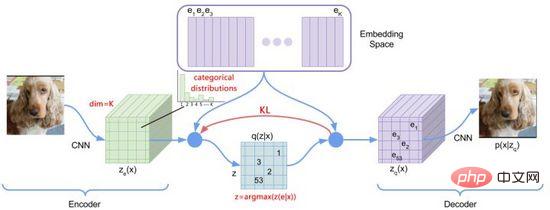
圖13. dVAE
為了優化上述問題,DALL·E使用Gumbel-Softmax建構了新的dVAE(圖13),解碼器的輸出變為Embedding Space上32*32個K=8192維分類機率,在訓練過程中對分類機率的Softmax計算加入噪音引入隨機性,使用逐步減小的溫度讓機率分佈近似one-hot編碼,對隱層向量的選擇重參數化使其可導(式(11)),推理過程中仍取最近鄰。
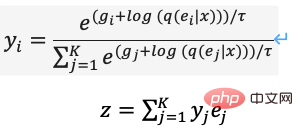
PyTorch實作中可設定hard=True輸出近似的one-hot編碼,同時透過 y_hard = y_hard - y_soft.detach() y_soft 保持可導。
當第一階段訓練完成後,我們可以固定dVAE對於每對文字-圖像產生預測目標的圖像Tokens。在第二階段訓練過程中,DALL·E使用BPE方法將文字先編碼成和圖像Tokens相同維度d=3968的文字Tokens,再將文字Tokens和圖像Tokens Concat到一起,加入位置編碼和Padding編碼,使用Transformer Encoder進行自迴歸預測,如圖14所示。為了提升運算速度,DALL·E也採用了Row、Column、Convolutional三種稀疏化的attention mask機制。
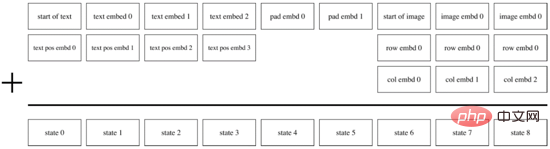
圖14. DALL·E的自回歸解碼器
基於上述實現,DALL·E可根據文字輸入不僅可產生「真實」的影像,還可進行融合創作、場景理解和風格轉化,如圖15。此外,DALL·E在零樣本和專業領域的效果可能變差,且產生的影像解析度(256*256)較低。

圖15. DALL·E的多種生成場景
為了進一步提升影像生成品質和探求文本-圖像特徵空間的可解釋性,OpenAI結合擴散模型和CLIP在2022年4月提出了DALL·E 2,不僅將生成尺寸增加到了1024*1024,還透過特徵空間的插值操作,可視化了文本-影像特徵空間的遷移過程。
如圖16所示,DALL·E 2將CLIP對比學習得到的text embedding、image embedding作為模型輸入和預測對象,具體過程是學習一個先驗Prior,從text預測對應的image embedding ,文章分別用自回歸Transformer和擴散模型兩種方式訓練,後者在各資料集上表現較好;再學習一個擴散模型解碼器UnCLIP,可看做是CLIP影像編碼器的逆向過程,將Prior預測得到的image embedding作為條件加入中實現控制,text embedding和文本內容作為可選條件,為了提升分辨率UnCLIP還增加了兩個上採樣解碼器(CNN網絡)用於逆向生成更大尺寸的圖像。
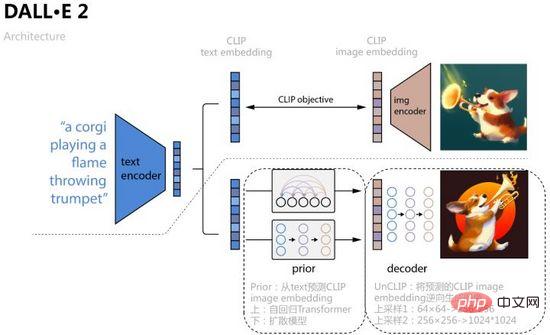
圖16. DALL·E 2
在Prior的擴散模型訓練中,DALL·E 2使用了一個Transformer Decoder預測擴散過程,輸入序列為BPE-encoded text text embedding timestep embedding 目前加噪的image embedding,預測去噪的image embedding,以MSE建構損失函數,
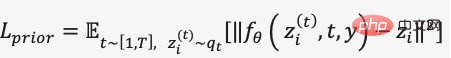

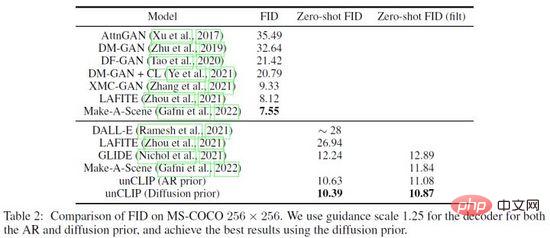
圖18. DALL·E 2在MS-COCO資料集上的對比結果
ERNIE-VILG是百度文心在2022年初提出的中文場景的文字-圖像雙向生成模型。
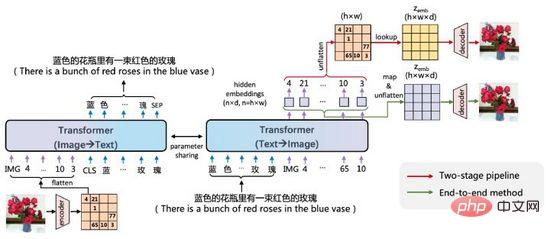
圖19. ERNIE-VILG
ERNIE-VILG的思路和DALL·E相似,透過預訓練的變分自編碼器編碼影像特徵,使用Transformer將文字Tokens和圖像Tokens自回歸預測,主要不同點在於:
ERNIE-VILG的另一個強大之處是,在中文場景可以處理多個物件和複雜位置關係的生成問題,如圖20。

圖20. ERNIE-VILG的生成範例
本文透過實例解讀了最新的以文生圖的新範式,包含變分自編碼器和擴散模型等生成方法的應用,CLIP等文本-圖像潛在空間表示學習的方法,以及離散化和重參數化等建模技術。
現今文字到影像的生成技術有較高的門檻,其訓練成本遠超人臉辨識、機器翻譯、語音合成等單模態方法,以DALL·E為例,OpenAI收集並標註了2.5億對樣本,使用了1024塊V100 GPU訓練了120億參數量的模型。此外,圖像生成領域一直存在種族歧視、暴力情色、敏感隱私等問題。從2020年開始,越來越多的AI團隊投入到跨模態生成研究中,不久的將來我們可能在真實世界和生成世界中真假難分。
以上是從VAE到擴散模型:一文解讀以文生圖新範式的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















