

「Making large models smaller」這是許多語言模型研究人員的學術追求,針對大模型昂貴的環境和訓練成本,陳丹琦在智源大會在青源學術年會上做了題為「Making large models smaller」的特邀報告。報告中重點提及了基於記憶增強的TRIME演算法和基於粗細粒度聯合剪枝和逐層蒸餾的CofiPruning演算法。前者能夠在不改變模型結構的基礎上兼顧語言模型困惑度和檢索速度方面的優勢;而後者可以在保證下游任務準確度的同時實現更快的處理速度,具有更小的模型結構。

#陳丹琦 普林斯頓大學電腦科學系助理教授
陳丹琦於2012年畢業於清華大學姚班,2018年獲得史丹佛大學電腦科學博士學位,師從史丹佛大學語言學和電腦科學教授Christopher Manning。
近年來,自然語言處理領域正快速地被大語言模式所主導。自從GPT 3問世以來,語言模型的規模呈現指數級成長。大型科技公司不斷發布越來越大的語言模式。近期,Meta AI發布了OPT語言模型(一個蘊含了1750億參數的大型語言模型),並向大眾開放了原始碼和模型參數。

研究學者之所以如此推崇大語言模型,是因為它們出色的學習能力和表現表現,但是人們對於大語言模型的黑盒性質仍了解甚少。向語言模型輸入一個問題,透過語言模型一步一步推理,能夠解決非常複雜的推理問題,例如推導出計算題的答案。但同時,大型語言模型也存在著風險,特別是它們的環境和經濟成本,例如:GPT-3 等大規模語言模型的能源消耗和碳排放規模驚人。  面對大語言模型訓練成本昂貴、參數量龐大等問題,陳丹團隊希望透過學術研究縮減預訓練模型的計算量並且讓語言模型更有效率地適用於下層應用。為此重點介紹了團隊的兩個工作,一個是一種語言模型的新型訓練方法稱為TRIME,另一個是一種適用於下游任務的有效模型剪枝方法稱為CofiPruning。
面對大語言模型訓練成本昂貴、參數量龐大等問題,陳丹團隊希望透過學術研究縮減預訓練模型的計算量並且讓語言模型更有效率地適用於下層應用。為此重點介紹了團隊的兩個工作,一個是一種語言模型的新型訓練方法稱為TRIME,另一個是一種適用於下游任務的有效模型剪枝方法稱為CofiPruning。

論文地址:https:/ /arxiv.org/abs/2205.12674
傳統語言模型的訓練流程如下:給定一段文檔,將其輸入到Transformer編碼器中得到隱向量,進而將這些隱向量被輸送到softmax層,該層輸出為由V個字嵌入向量組成的矩陣,其中V代表詞彙量的規模,最後可以用這些輸出向量對原先的文本進行預測,並與給定文檔的標準答案進行比較計算梯度,實現梯度的反向傳播。然而這樣的訓練範式會帶來以下問題:(1)龐大的Transformer編碼器會帶來高昂的訓練代價;(2)語言模型輸入長度固定,Transformer的計算量規模會隨著序列長度的變化呈平方級增長,因此Transformer很難處理長文本;(3)如今的訓練範式是將文本投影到一個固定長度的向量空間內來預測接下來的單詞,這種訓練範式實際上是語言模型的一個瓶頸。

為此,陳丹琦團隊提出了新的訓練範式-TRIME#,主要利用批次記憶進行訓練,並在此基礎之上提出了三個共享相同訓練目標函數的語言模型,分別是TrimeLM,TrimeLMlong以及TrimeLMext。 TrimeLM可以看作是標準語言模型的替代方案;TrimeLMlong 針對長範圍文字設計,類似於Transformer-XL;TrimeLMext結合了一個大型的資料儲存區,類似於kNN-LM。在前文所述的訓練範式下,TRIME先將輸入文字定義為 ,接著將輸入傳送到Transformer編碼器
,接著將輸入傳送到Transformer編碼器 ##中,得到隱向量
##中,得到隱向量 ,經過softmax層
,經過softmax層 之後得到需要預測的下一個單字
之後得到需要預測的下一個單字 ,在整個訓練範式中可訓練的參數為
,在整個訓練範式中可訓練的參數為 和E。 陳丹琦團隊的工作受到了以下兩個工作的啟發:(1)2017年Grave等人提出的連續緩存(Continuous cache)演算法。 該演算法在訓練過程中訓練一個普通的語言模型
和E。 陳丹琦團隊的工作受到了以下兩個工作的啟發:(1)2017年Grave等人提出的連續緩存(Continuous cache)演算法。 該演算法在訓練過程中訓練一個普通的語言模型 ;在推斷過程中,給定輸入的文本
;在推斷過程中,給定輸入的文本 ,首先列舉給定文本先前出現的所有單字和其中所有等於下一個需要預測單字的標記位置,然後利用隱變數之間的相似度和溫度參數計算快取分佈。在測試階段,語言模型分佈和快取分佈進行線性內插可以獲得更好的實驗效果。
,首先列舉給定文本先前出現的所有單字和其中所有等於下一個需要預測單字的標記位置,然後利用隱變數之間的相似度和溫度參數計算快取分佈。在測試階段,語言模型分佈和快取分佈進行線性內插可以獲得更好的實驗效果。

(2)2020年Khandelwal等人提出的k近鄰語言模型(kNN-LM),該方法與連續快取演算法類似,二者之間最大的不同在於kNN-LM為所有的訓練範例建構了一個資料儲存區,在測試階段將對資料儲存區的資料進行k近鄰搜索,從而選擇最佳的top -k數據。 
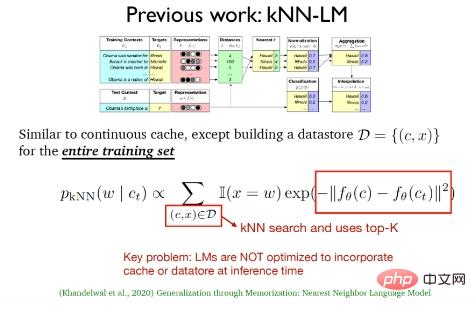
上述兩個工作其實只是在測試階段採用了快取分佈和k近鄰分佈,在訓練過程中只是延續了傳統的語言模型,在推斷階段語言模型並沒有優化快取和資料儲存區的結合。
除此之外,還有一些針對超長文本的語言模型工作值得關注,例如在2019年提出的結合注意力循環(Attention recurrence)機制的Transformer-XL和2020年提出的基於記憶壓縮(Memory compression)的Compressive Transformers等。
在先前介紹的幾項工作基礎之上,陳丹琦團隊建立了一個基於批次記憶的語言模型訓練方法,主要想法是針對相同的訓練批(training batch)建立一個工作記憶(working memory)。 針對給定文字預測下一個單字的任務,TRIME的想法與對比學習十分類似,不僅僅考慮利用softmax詞嵌入矩陣預測下一個單字出現機率的任務,還新增了一個模組,在這個模組中考慮所有出現在訓練記憶(training memory)中且與給定文本需要預測的單字相同的所有其他文本。

因此整個TRIME的訓練目標函數包含兩個部分:
(1)基於輸出詞嵌入矩陣的預測任務。
(2)在訓練記憶(training memory)中共享同一個待預測單字文字的相似度,其中需要衡量相似度的向量表示是在通過最終前饋層的輸入,採用縮放點積衡量向量相似度。
演算法希望最終訓練的網路能夠實現最終預測的單字盡可能準確,同時同一訓練批內共享同一個待預測單字的文字盡可能相似,以使得正在訓練過程中讓所有的文本記憶表示透過反向傳播實現端到端的神經網路學習。演算法的實現思想在很大程度上受到2020年提出的稠密檢索(dense retrieval)所啟發,稠密檢索在訓練階段對齊詢問和正相關文檔並且利用同一批內的文檔作為負樣本,在推斷階段從大型數據儲存區中檢索相關文件。

TRIME的推理階段幾乎與訓練過程相同,唯一的差異在於可能會採用不同的測試記憶,包括局部記憶(Local memory) ,長期記憶(Long-term memory)和外在記憶(External memory)。局部記憶指的是出現在當前片段中的所有單詞,並且已經被注意力機制向量化;長期記憶指的是由於輸入長度限制導致無法直接獲取但與待處理文本來源於相同文檔的文本表示,外部記憶指的是儲存所有訓練樣本或額外語料庫的大型資料儲存區。 
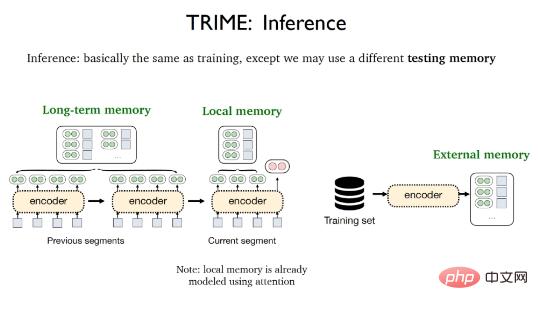
為了能夠盡可能減少訓練和測試階段的不一致性,需要採取一定的資料處理策略來更好地構建訓練記憶。局部記憶指的是同一個資料片段中的先前標記(tokens),使用代價極為低廉。可以採用隨機取樣的批次方式就能直接在訓練階段和測試階段同時利用局部記憶,這就得到了基於局部記憶的基礎版TrimeLM模型。

長期記憶指的是同一個文件先前片段中的標記,需要依賴同一個文件的先前片段。為此將同一個文件中的連續片段(consecutive segments)放入同一個訓練批次中,這就得到了集合長期記憶的TrimeLMlong模型。

外部記憶需要結合大型資料儲存區進行檢索。為此可以利用BM25將訓練資料中的相似片段放入同一個訓練批次中,這就得到了結合外部記憶的TrimeLMext模型。

綜上所述,傳統的語言模型在訓練階段和測試階段都沒有利用記憶;連續緩存方法只在測試階段採用了局部記憶或長期記憶;k近鄰語言模型在測試階段採用了外在記憶;而針對TRIME演算法的三種語言模型,在訓練階段和測試階段都採用了記憶增強的方式,其中TrimeLM在訓練階段和測試階段都採用了局部記憶,TrimeLMlong在訓練階段針對相同文件的連續片段放入同一批訓練,在測試階段結合了局部記憶和長期記憶,TrimeLMext在訓練階段針對相似文件放入同一批訓練,在測試階段結合了局部記憶、長期記憶和外部記憶。

在實驗階段,在WikiText-103資料集上進行模型參數247M,切片長度3072的測試時,基於TRIME演算法的三種版本的語言模型都能取得比傳統Transformer更好的困惑度(perplexity)效果,其中基於實際距離的TrimeLMext模型可以取得最佳實驗效果。同時TrimeLM和TrimeLMlong也能保持和傳統Transformer 接近的檢索速度,同時兼具了困惑度和檢索速度的優勢。

在WikiText-103資料集上進行模型參數150M,切片長度150的測試時,可以看到由於TrimeLMlong在訓練階段針對相同文件的連續片段放入同一批訓練,在測試階段結合了局部記憶和長期記憶,因此儘管切片長度只有150,但是在測試階段實際可利用的數據可以達到15000,實驗效果遠遠好於其他基線模型。

針對字元層級的語言模型構建,基於TRIME演算法的語言模型在enwik8資料集上同樣取得了最好的實驗效果,同時在機器翻譯的應用任務中,TrimeMT_ext也取得了超過基準模型的實驗效果。

綜上所述,基於TRIME演算法的語言模型採用了三種記憶建構的方式,充分利用同一批內的相關資料實現記憶增強,在引入記憶的同時卻沒有引入大量的計算代價,並且沒有改變模型的整體結構,相比於其他基線模型取得了較好的實驗效果。
陳丹琦也著重提到了基於檢索的語言模型,實際上TrimeLMext可以看作是k近鄰語言模型的一個更好的版本,但是在推斷過程中這兩種演算法相較於其他的基線模型速度則慢接近10到60倍,顯然是難以接受的。陳丹琦指出了基於檢索的語言模型未來可能的發展方向之一:是否可以利用一個更小的檢索編碼器和一個更大的資料儲存區,從而實現計算代價縮減到最近鄰搜尋。
相比於傳統的語言模型,基於檢索的語言模型有顯著的優勢,例如:基於檢索的語言模型可以更好的實現更新和維護,而傳統的語言模型由於利用先前知識進行訓練無法實現知識的動態更新;同時基於檢索的語言模型還可以更好的利用到隱私敏感的領域中去。至於如何更好的利用基於檢索的語言模型,陳丹琦老師認為或許可以採用fine-tuning、prompting或in-context learning的方式來輔助解決。 

論文網址:https://arxiv.org/abs/2204.00408
#模型壓縮技術被廣泛應用於大語言模型,讓更小的模型能夠更快地適用於下游應用,其中傳統的主流模型壓縮方法為蒸餾(Distillation)和剪枝(pruning)。對於蒸餾而言,往往需要預先定義一個固定的學生模型,這個學生模型通常是隨機初始化的,然後將知識從教師模型傳送到學生模型中去,實現知識蒸餾。
例如,從原始版本的BERT出發,經過通用蒸餾,即在大量無標註的語料庫上進行訓練之後,可以得到基礎版本的TinyBERT4,針對基礎版本的TinyBERT4,也可以透過任務驅動的蒸餾方法得到微調過的TinyBERT4,最終得到的模型在犧牲輕微的準確度基礎之上可以比原先的BERT模型更小且處理速度更快。然而這種基於蒸餾的方法也存在著一定的缺陷,例如針對不同的下游任務,模型的架構往往是固定不變的;同時需要利用無標註資料從零開始訓練,計算代價太大。

對於剪枝而言,往往需要從一個教師模型出發,然後不斷地從原始模型中移除不相關的部分。在2019年提出的非結構化剪枝可以得到更小的模型但是在運行速度方面提升很小,而結構化剪枝通過移除例如前饋層等參數組實現實際應用的速度提升,例如2021年提出的塊剪枝可以達到2-3倍的速度提升。


針對傳統蒸餾和剪枝方法存在的局限性,陳丹琦團隊提出了一種名為CofiPruning的演算法,同時針對粗粒度單元和細粒度單元進行剪枝,並設計了一個逐層蒸餾的目標函數將知識從未剪枝模型傳送到剪枝後的模型中去,最終能夠在保持超過90 %準確率的基礎之上達到超過10倍的速度提升,比傳統的蒸餾方法計算代價更小。
CofiPruning的提出建立在兩個重要的基礎工作之上:
(1)針對整層剪枝可以獲得速度上的提升,相關工作指出大概50%左右的神經網路層是可以被剪枝的,但是粗粒度的剪枝對準確率的影響比較大。
(2)是對更小單元例如頭部進行剪枝可以獲得更好的靈活性,但是這種方法在實作上會是更有難度的最佳化問題,且不會有太大的速度提升。
為此陳丹琦團隊希望能夠在粗粒度單元和細粒度單元同時剪枝,從而兼具兩種粒度的優勢。除此之外,為了解決從原始模型到剪枝模型的資料傳送,CofiPruning在剪枝過程中採用逐層對齊的方式實現知識的傳送,最終的目標函數包括了蒸餾損失和基於稀疏度的拉格朗日損失。

在實驗階段,在句子分類任務的GLUE資料集和問答任務的SQuAD1.1資料集上,可以發現CofiPruning在在相同的速度和模型規模基礎之上比所有的蒸餾和剪枝基線方法表現更好。

針對TinyBERT,如果沒有經過通用蒸餾,實驗效果會大打折扣;但是如果利用通用蒸餾,儘管實驗效果可以有所提升但是訓練時間代價會非常昂貴。而CofiPruning演算法不但能夠獲得與基準模型近乎持平的效果,在運行時間和計算代價方面還都有很大提升,可以用更少的計算代價獲得更快的處理速度。實驗表明,針對粗粒度單元,第一層和最後一層前饋層在最大程度上會被保留而中間層更有可能會被剪枝;針對細粒度單元,上層神經網絡的頭部和中間維度更有可能會被剪枝。

綜上所述,CofiPruning是一種非常簡單有效的模型壓縮演算法,透過對粗粒度單元和細粒度單元聯合剪枝,結合逐層蒸餾的目標函數可以聯通結構剪枝和知識蒸餾這兩種演算法的優勢,從而實現更快的處理速度和更小的模型結構。針對模型壓縮的未來趨勢,陳丹琦也重點提及了是否能夠對例如GPT-3這樣的大型語言模型進行剪枝,同時是否能夠對上游任務進行剪枝,這些都是未來可以重點關注的研究思路。
大型語言模型如今取得了非常喜人的實際應用價值,但是由於昂貴的環境和經濟成本,隱私和公平性方面的困擾以及難以即時更新的問題,導致大型語言模型仍有許多待改進之處。 陳丹琦認為,未來的語言模型或許可以用作大型的知識庫,同時在未來語言模型的規模需要大幅度削減,或許可以利用基於檢索的語言模型或者稀疏語言模型來代替稠密檢索,模型壓縮的工作也需要研究者們重點關注。
#以上是普林斯頓陳丹琦:如何讓「大模型」變小的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















