

過去十年,學術和商業機器翻譯系統(MT)的品質已經得到了大幅的提升。這些提升很大程度上得益於機器學習的進展和可用的大規模 web 挖掘資料集。同時,深度學習(DL)和E2E 模型的出現、從web 挖掘得到的大型並行單語言資料集、回譯和自訓練等資料增強方法以及大規模多語言建模等帶來了能夠支援超過100 種語言的高品質機器翻譯系統。
然而,雖然低資源機器翻譯出現了巨大進展,但已經構建廣泛可用且通用的機器翻譯系統的語言被限制在了大約100 種,顯然它們只是當今全世界使用的7000 多種語言中的一小部分。除了語言數量受限之外,目前機器翻譯系統所支援的語言的分佈也極大地向歐洲語言傾斜。
我們可以看到,儘管人口眾多,非洲、南亞和東南亞所說的語言以及美洲原住民語言相關的服務卻較少。例如,Google翻譯支援弗里西亞語、馬耳他語、冰島語和柯西嘉語,以它們為母語的人口均少於 100 萬。相較之下,Google翻譯沒有提供服務的比哈爾方言人口約為5,100 萬、奧羅莫語人口約2,400 萬、蓋丘亞語人口約900 萬、提格里尼亞語人口約為900 萬(2022 年)。這些語言稱為「長尾」語言,資料缺乏需要應用一些可以泛化到擁有充足訓練資料的語言之外的機器學習技術。
建構這些長尾語言的機器翻譯系統在很大程度上受到可用數位化資料集和語言辨識(LangID)模型等 NLP 工具缺失的限制。這些對高資源語言來說卻是無所不在的。
在近日谷歌一篇論文《Building Machine Translation Systems for the Next Thousand Languages》中,二十幾位研究者展示了他們努力建立支援超過1000 種語言的實用機器翻譯系統的成果。

論文網址:https://arxiv.org/pdf/2205.03983.pdf
具體而言,研究者從以下三個研究領域中描述了他們的成果。
第一,透過用於語言識別的半監督預訓練以及資料驅動的過濾技術,為 1500 語言創建了乾淨、web 挖掘的資料集。
第二,透過用於100 多種高資源語言的、利用監督並行資料訓練的大規模多語言模型以及適用於其他1000 語言的單語言資料集,為服務水平低的語言創建了切實有效的機器翻譯模型。
第三,研究這些語言的評估指標有哪些限制,並對機器翻譯模型的輸出進行定性分析,並重點關注這類模型的幾種常見的誤差模式。
對於致力於為當前研究不足的語言建立機器翻譯系統的從業者,研究者希望這項工作可以為他們提供有用的洞見。此外,研究者也希望這項工作可以引領人們聚焦那些彌補資料稀疏設定下大規模多語言模型弱點的研究方向。
在5 月12 日的I/O 大會上,Google宣布自家的翻譯系統新增了24 種新的語言,其中包括一些小眾的美洲原住民語言,例如前文提到的比哈爾方言、奧羅莫語、蓋丘亞語和提格里尼亞語。

#這項工作主要分為四大章節展開,這裡只對每個章節的內容進行簡單介紹。
本章詳細介紹了研究者在為1500 語言爬取單語言文字數據集的過程中所採用的方法。這些方法重點在於恢復高精度資料(即高比例的乾淨、語言內文字),因此很大一部分是各種各樣的過濾方法。
總的來說,研究者採用的方法包含如下:
如下是使用 1745-language 的 CLD3 LangID 模型在 web 文字上的文件一致性分數直方圖。
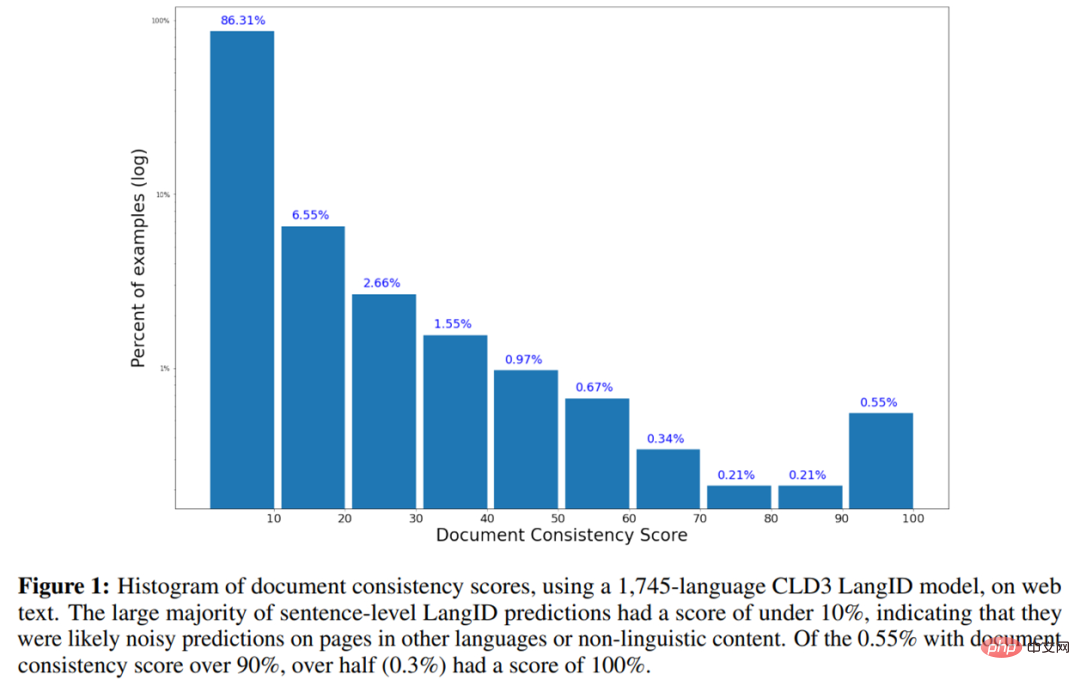
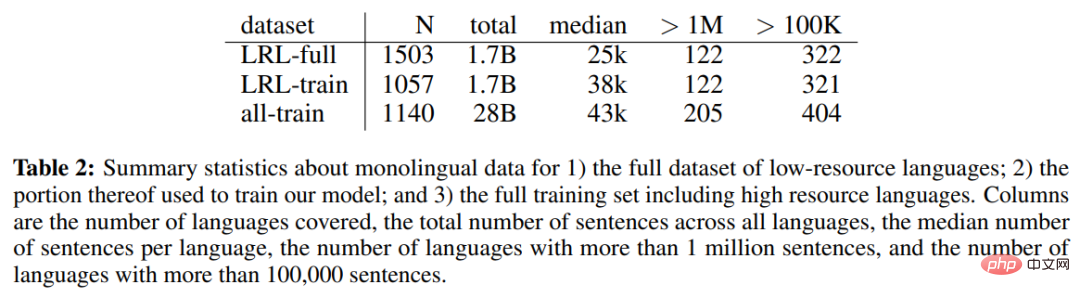
下表2 為低資源語言(LRL)完整資料集的單語言資料、用於訓練模型的部分單語言資料以及包含高資源語言在內的完整訓練集的單語言資料統計。
章節目錄如下:

對於從web 挖掘的單語言數據,下一個挑戰是從數量有限的單語言訓練數據中創建高品質的通用機器翻譯模型。為此,研究者採用了這樣一種實用方法,即利用所有可用於更高資源語言的並行資料來提升只有單語言資料可用的長尾語言的品質。他們將這項設定稱為「零資源」(zero-resource),這是因為長尾語言沒有直接的監督。
研究者利用過去幾年為機器翻譯開發的幾種技術來提升長尾語言零資源翻譯的品質。這些技術包括從單語言資料中進行自我監督學習、大規模多語言監督學習、大規模回譯和自我訓練、高容量模型。他們利用這些工具創建了能夠翻譯 1000 種語言的機器翻譯模型,並利用現有覆蓋大約 100 種語言的平行語料庫和從 web 中構建的 1000-language 的單語言資料集。
具體地,研究者首先透過比較15 億和60 億參數Transformers 在零資源翻譯上的表現來強調模型容量在高度多語言模型中的重要性(3.2) ,然後將自監督語言的數量增加到1000 種,驗證了隨著來自相似語言中更多單語言資料變得可用,大多數長尾語言的效能也相應提高(3.3)。雖然研究者的 1000-language 模型表現出了合理的性能,但為了了解使用方法的優點和局限性,他們融入了大規模資料增強。
此外,研究者透過自訓練和回譯對包含大量合成資料的 30 種語言的子集上的生成模型進行微調(3.4)。他們進一步描述了過濾合成資料的實用方法以增強這些微調模型對幻覺(hallucinations)和錯誤語言翻譯的穩健性(3.5)。
研究者也使用序列級蒸餾將這些模型提煉成更小、更易於推理的架構,並強調了教師和學生模型之間的表現差距(3.6)。
章節目錄如下:

為了評估自己的機器翻譯模型,研究者首先將英文句子翻譯成了這些語言,為所選的38 種長尾語言建構了一個評估集(4.1)。他們強調了 BLEU 在長尾設定中的局限性,並使用 CHRF 評估這些語言(4.2)。
研究者也提出了一個近似的、基於往返(round-trip)翻譯的無參考指標,用來了解模型在參考集不可用的語言上的質量,並報告了以此指標衡量的模型的品質(4.3)。他們對模型在 28 種語言的子集上進行人工評估並報告了結果,確認可以按照文中描述的方法建立有用的機器翻譯系統(4.4)。
為了了解大規模多語言零資源模型的弱點,研究者在幾種語言上進行了質性誤差分析。結果發現,模型經常混淆分佈上相似的單字和概念,例如「老虎」變成了「小型鱷魚」(4.5)。並且在更低資源的設定下(4.6),模型翻譯 tokens 的能力在出現頻率降低的 tokens 上下降。
研究者也發現,這些模型通常無法準確地翻譯短的或單字輸入(4.7)。對提煉模型的研究結果表明,所有模型都更有可能放大訓練資料中存在的偏見或雜訊(4.8)。
章節目錄如下:

#研究者對上述模型進行了一些額外的實驗,表明它們在相似語言之間直接進行翻譯通常效果更好,而不使用英語作為支點(5.1),並且它們可以用於不同scripts 之間的零樣本音譯(5.2)。
他們描述了一種將終端標點符號附加到任何輸入的實用技巧,稱為「句號技巧」(period trick),可以用它來提升翻譯品質(5.3) 。
此外,研究者也證明了這些模型對一些而不是所有語言的非標準Unicode 字形使用都是穩健的(5.4),並探索了幾種non-Unicode 字體(5.5)。
章節目錄如下:

#想要了解更多研究細節,請參考原文。
以上是谷歌為1000+「長尾」語言創建機器翻譯系統,已支援部分小眾語言的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















