


SQL Server還原完整備份與差異備份的作業過程

這篇文章為大家帶來了關於SQL server的相關知識,其中主要介紹了SQL Server 還原完整備份和差異備份的詳細操作,本文透過圖文並茂的形式給大家介紹的非常詳細,下面一起來看一下,希望對大家有幫助。

推薦學習:《SQL教學》
1.首先右鍵資料庫,點選還原資料庫:
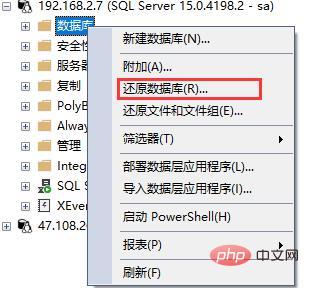
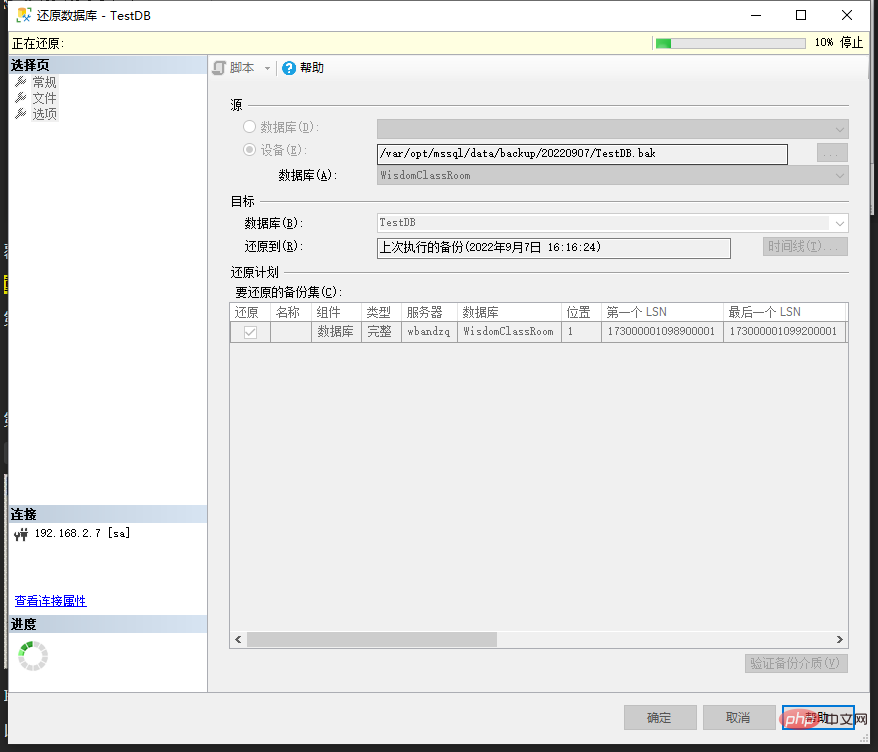
然後會開啟還原資料庫窗口,如圖所示:
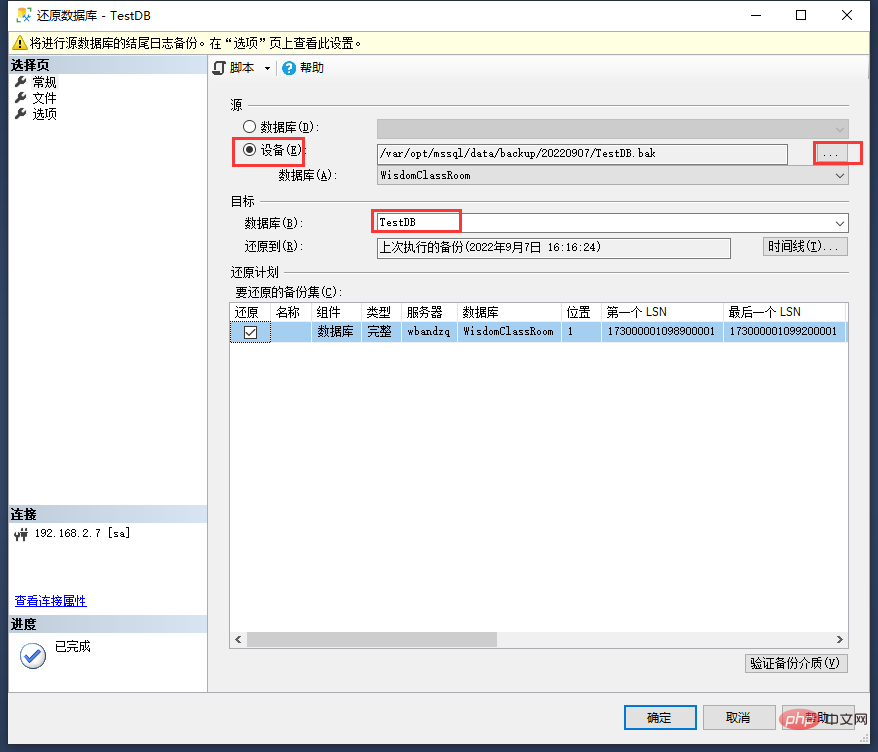
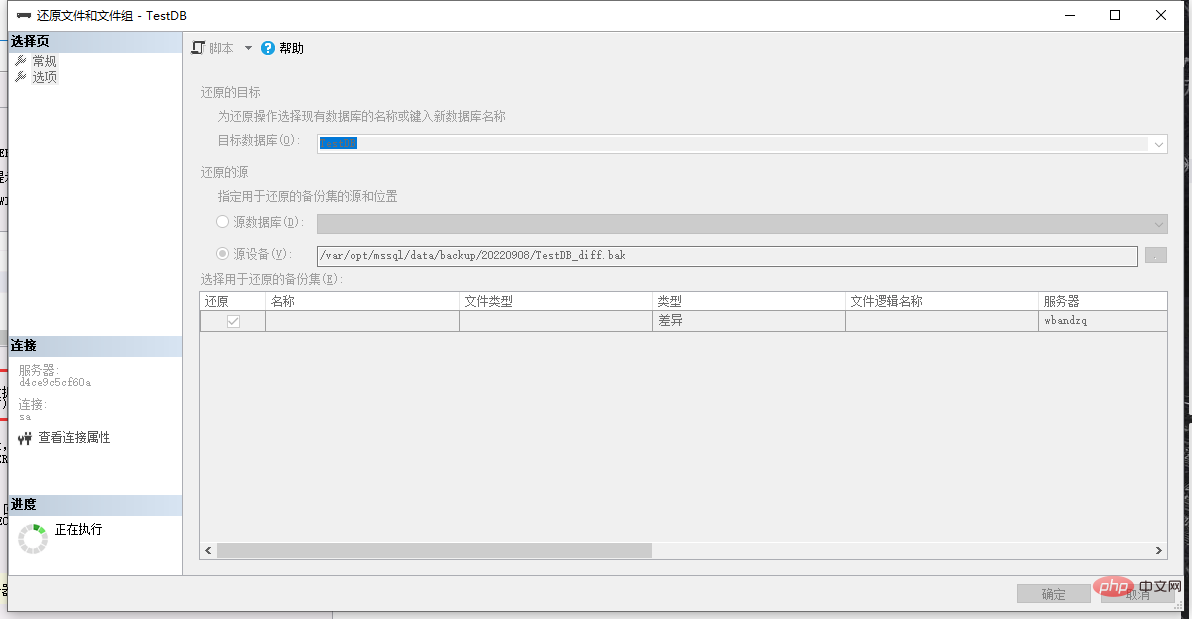
- #首先"來源" 選擇設備,並且選擇到完整備份的資料庫備份檔案
- 然後在"目標" 資料庫可直接填入還原以後的資料庫名稱
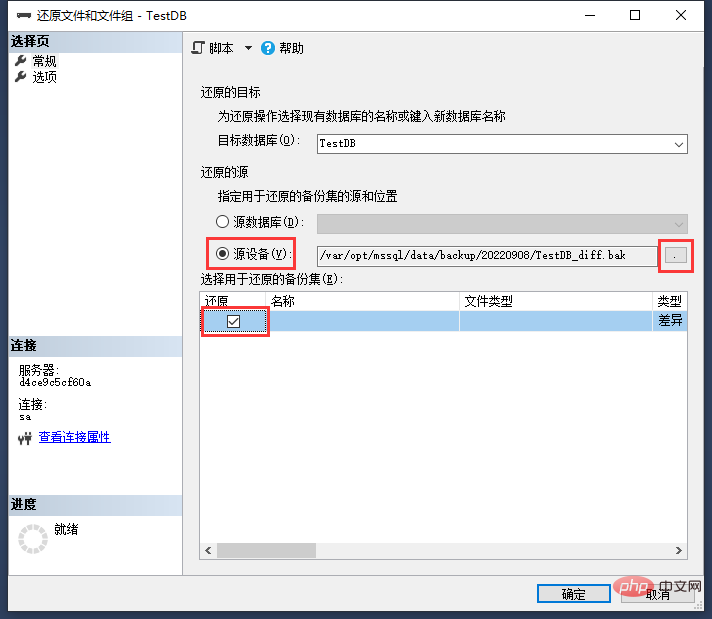
接著點選左側檔案:
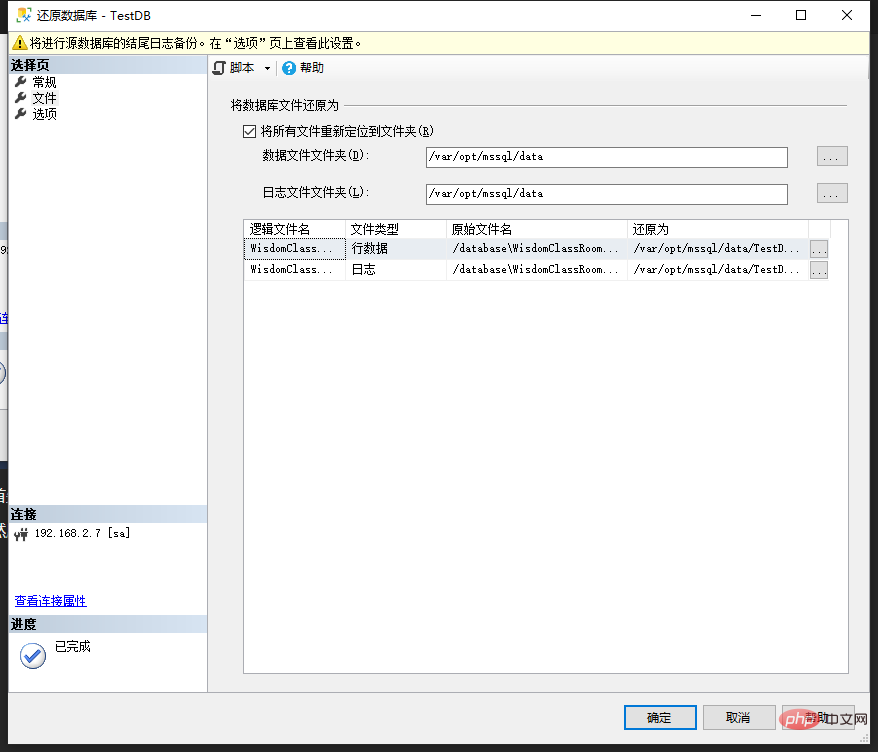
建議勾選選項"將所有檔案重新定位到資料夾",其實就是還原以後的資料庫儲存位置,當然不勾選也一樣能還原。
然後繼續點擊左側選項:
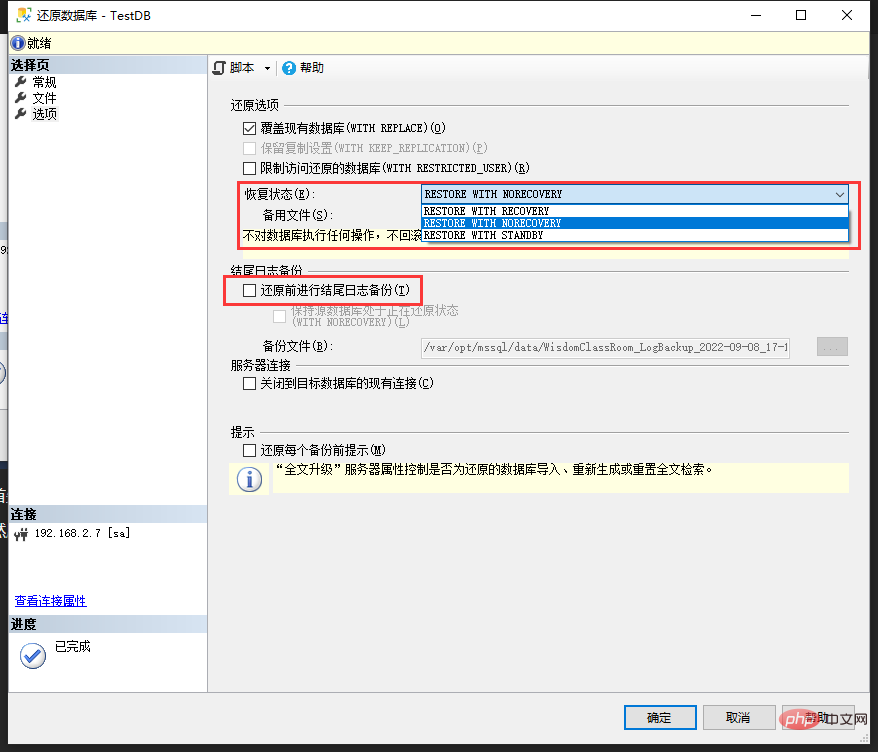
覆蓋現有資料庫可勾可不勾,如果是還原到已存在的資料庫,建議勾選。
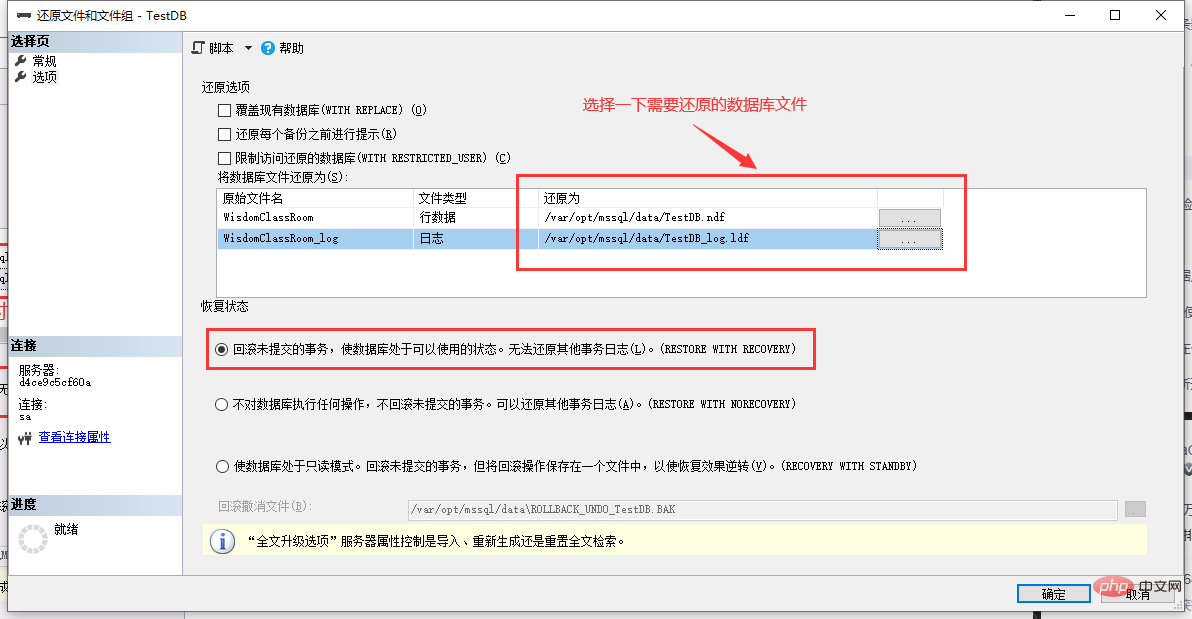
重點:
第一個紅框中的復原狀態選擇:
- ##如果只需要還原完整備份,選擇
- RESTORE WITH RECOVERY
- RESTORE WITH NORECOVERY
Exclusive access could not be obtained because the database is in use.
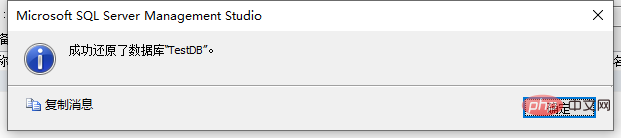
RESTORE WITH RECOVERY,那麼還原成功後就可以正常存取資料庫了。
RESTORE WITH NORECOVERY ,那麼在提示還原成功後,你可能會看到這種情況:

SQL教學》
以上是SQL Server還原完整備份與差異備份的作業過程的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undress AI Tool
免費脫衣圖片

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 SQL查詢中獨特關鍵字的目的是什麼?
Jul 02, 2025 am 01:25 AM
SQL查詢中獨特關鍵字的目的是什麼?
Jul 02, 2025 am 01:25 AM
DISTINCT關鍵字在SQL中用於去除查詢結果中的重複行。其核心作用是確保返回的每一行數據都是唯一的,適用於獲取單列或多列的唯一值列表,如部門、狀態或名稱等。使用時需注意DISTINCT作用於整行而非單列,且常與多列組合使用時返回所有列的唯一組合。基本語法為SELECTDISTINCTcolumn_nameFROMtable_name,可應用於單列或多列查詢。使用時需注意其性能影響,尤其是在大數據集上需進行排序或哈希操作。常見誤區包括誤以為DISTINCT僅作用於單列、在無需去重的場景下濫用D
 SQL中的何處和有子句之間有什麼區別?
Jul 03, 2025 am 01:58 AM
SQL中的何處和有子句之間有什麼區別?
Jul 03, 2025 am 01:58 AM
WHERE和HAVING的主要區別在於過濾時機:1.WHERE在分組前過濾行,作用於原始數據,不能使用聚合函數;2.HAVING在分組後過濾結果,作用於聚合後的數據,可以使用聚合函數。例如查詢中先用WHERE篩選高薪員工再分組統計,再用HAVING篩選平均薪資超6萬的部門時,兩者順序不可調換,WHERE始終先執行,確保僅符合條件的行參與分組,HAVING則根據分組結果進一步過濾最終輸出。
 聯盟和工會的所有區別是什麼?
Jun 14, 2025 am 12:37 AM
聯盟和工會的所有區別是什麼?
Jun 14, 2025 am 12:37 AM
ThemaindifferencebetweenUNIONandUNIONALLinSQListhatUNIONremovesduplicaterows,whileUNIONALLretainsallrowsincludingduplicates.1.UNIONperformsaDISTINCToperationacrossallcolumnsfrombothresultsets,whichinvolvessortingorhashingdatatoeliminateduplicates,mak
 如何執行通配符搜索,%和_之間有什麼區別?
Jun 13, 2025 am 12:20 AM
如何執行通配符搜索,%和_之間有什麼區別?
Jun 13, 2025 am 12:20 AM
%匹配任意數量字符適合寬泛搜索,\_匹配單個字符適合精准定位。例如:Li%匹配以Li開頭的所有內容,Li\_僅匹配三個字母的名字如Liu或Lia;使用LIKE觸發通配符,含特殊字符需轉義;不同環境通配符規則有差異需注意區分。
 如何計算表中的行總數?
Jun 13, 2025 am 12:30 AM
如何計算表中的行總數?
Jun 13, 2025 am 12:30 AM
統計表總行數的明確答案是使用數據庫的計數功能,最直接的方法是執行SQL的COUNT()函數,例如:SELECTCOUNT()AStotal_rowsFROMyour_table_name;其次對於大數據量表可查看系統表或信息模式獲取估算值,如PostgreSQL使用SELECTreltuplesFROMpg_classWHERErelname='your_table_name';MySQL使用SELECTTABLE_ROWSFROMinformation_schema.TABLESWHERETA
 如何使用與另一個表相同的結構創建空表?
Jul 11, 2025 am 01:51 AM
如何使用與另一個表相同的結構創建空表?
Jul 11, 2025 am 01:51 AM
你可以使用SQL的CREATETABLE語句和SELECT子句來創建一個與另一張表結構相同但為空的表。具體步驟如下:1.使用CREATETABLEnew_tableASSELECT*FROMexisting_tableWHERE1=0;創建空表。 2.必要時手動添加索引、外鍵和触發器等,以確保新表與原表結構完整一致。
 該小組的子句如何工作?
Jun 17, 2025 am 09:39 AM
該小組的子句如何工作?
Jun 17, 2025 am 09:39 AM
GROUPBY在SQL中用於將具有相同列值的行分組為聚合數據。它通常與COUNT、SUM、AVG、MAX或MIN等聚合函數一起使用,以對每組數據進行計算而非整個表。 1.當需要基於一個或多個類別匯總數據時應使用GROUPBY,例如計算每個地區的總銷售額;2.GROUPBY的工作原理是掃描指定列、將相同值的行分組並應用聚合函數;3.常見錯誤包括SELECT中包含未聚合或未分組的列、GROUPBY列過多導致分組過細以及誤解NULL值的處理;4.GROUPBY可以與多列一起使用以實現更細緻的分組,如按部
 SQL中的聚類和非聚類索引有什麼區別?
Jul 04, 2025 am 03:03 AM
SQL中的聚類和非聚類索引有什麼區別?
Jul 04, 2025 am 03:03 AM
clusteredandnon-clusteredIndexesdifferIndataOrganizationAndusage.1.ClusteredIndexesdefinEthephysicalOrderOrderOdicalOdicalOdicalOdicalOdicalOdicalOfdatastorage,允許onlyonyonepertable,Idealfornage.2.non-ClusteredIndexesccreateScreatEastreateStructurowithuctureWithPoInterStodatAtarows.Non-clusteredIndexeScreateScreateScreateScreateStodatAtaTarowSoblowsEblingMultiplei
