

這篇文章為大家帶來了關於Python的相關知識,主要介紹了python爬蟲如何爬取網頁數據並解析數據,幫助大家更好的利用爬蟲分析網頁,下面一起來看一下,希望對大家有幫助。

【相關推薦:Python3影片教學 】
網路爬蟲(又稱網路蜘蛛,機器人),就是模擬客戶端發送網路請求,接收請求回應,一種依照一定的規則,自動地抓取網路資訊的程式。
只要瀏覽器能夠做的事情,原則上,爬蟲都能夠做到。
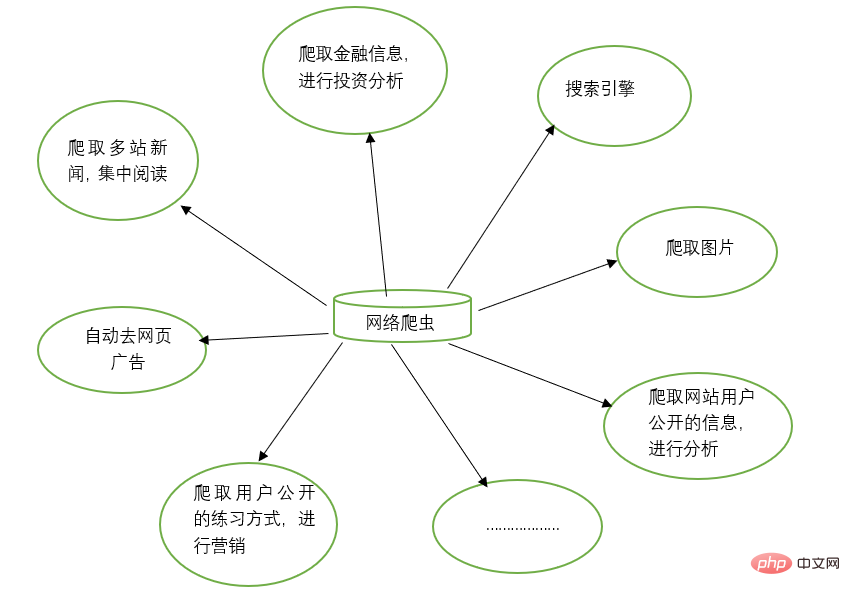
網路爬蟲可以取代手工做很多事情,例如可以用來做搜尋引擎,也可以爬取網站上面的圖片,例如有些朋友將某些網站上的圖片全部爬取下來,集中進行瀏覽,同時,網絡爬蟲也可以用於金融投資領域,比如可以自動爬取一些金融信息,並進行投資分析等。
有時,我們比較喜歡的新聞網站可能有幾個,每次都要分別打開這些新聞網站瀏覽,比較麻煩。此時可以利用網路爬蟲,將這多個新聞網站中的新聞資訊爬取下來,集中進行閱讀。
有時,我們在瀏覽網頁上的資訊的時候,會發現有很多廣告。此時同樣可以利用爬蟲將對應網頁上的資訊爬取過來,這樣就可以自動的過濾掉這些廣告,方便對資訊的閱讀與使用。
有時,我們需要進行行銷,那麼如何找到目標客戶以及目標客戶的聯繫方式是一個關鍵問題。我們可以手動地在網路中尋找,但是這樣的效率會很低。此時,我們利用爬蟲,可以設定對應的規則,自動地從網路中擷取目標使用者的聯絡資訊等數據,供我們進行行銷使用。
有時,我們想對某個網站的用戶資訊進行分析,例如分析該網站的用戶活躍度、發言數、熱門文章等信息,如果我們不是網站管理員,手工統計將是一個非常龐大的工程。此時,可以利用爬蟲輕鬆將這些資料採集到,以便進行進一步分析,而這一切爬取的操作,都是自動進行的,我們只需要編寫好對應的爬蟲,並設計好對應的規則即可。
除此之外,爬蟲還可以實現許多強大的功能。總而言之,爬蟲的出現,可以在一定程度上代替手工訪問網頁,從而,原先我們需要人工去訪問互聯網信息的操作,現在都可以用爬蟲自動化實現,這樣可以更高效率地利用好互聯網中的有效信息。
在進行爬取資料和解析資料前,需要在Python運作環境中下載安裝第三方函式庫requests。
在Windows系統中,開啟cmd(命令提示字元)介面,在該介面輸入pip install requests,按回車鍵進行安裝。 (注意連接網路)如下圖
安裝完成,如圖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
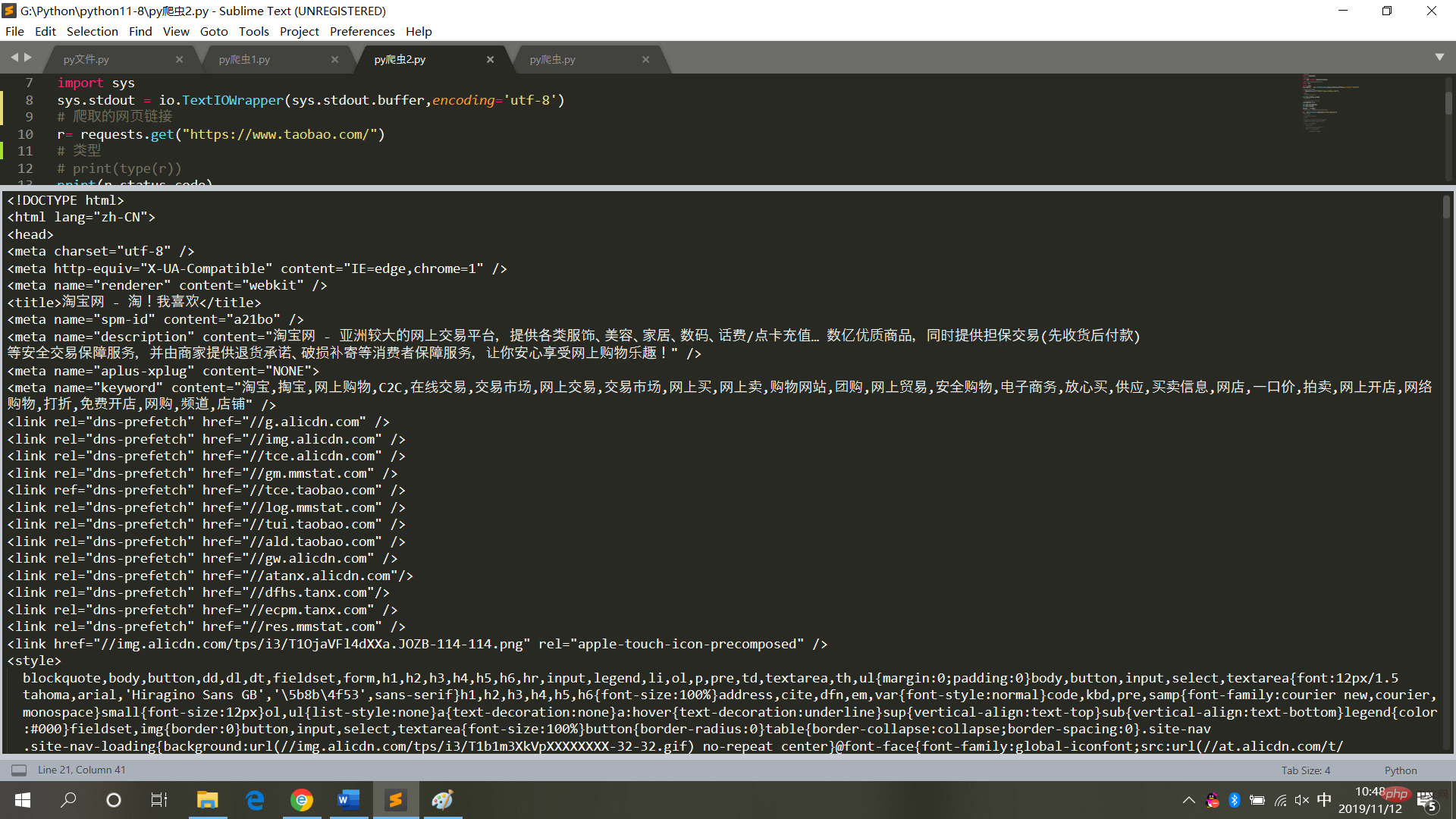
運行結果,如圖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|
運行結果,如圖
在對網頁程式碼進行爬取操作時,不能頻繁操作,更不要將其設定成死循環模式(每一次爬取則為對網頁的訪問,頻繁操作會導致系統崩潰,會追究其法律責任)。
所以在取得網頁資料後,將其儲存為本機文字模式,然後再解析(不再需要存取網頁)。
【相關推薦:Python3影片教學 】
以上是python爬蟲爬取網頁數據並解析數據的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















