


一文了解大文件排序/外存排序問題

問題一:一個檔案含有5億行,每行是一個隨機整數,需要對該檔案所有整數排序。
分治(pide&Conquer),參考大數據演算法:對5億資料進行排序
對這個一個500000000行的total.txt 進行排序,該檔案大小4.6G。
每讀10000行就排序並寫入到一個新的子檔案裡(這裡使用的是快速排序)。
1.分割 & 排序
#!/usr/bin/python2.7
import time
def readline_by_yield(bfile):
with open(bfile, 'r') as rf:
for line in rf:
yield line
def quick_sort(lst):
if len(lst) < 2:
return lst
pivot = lst[0]
left = [ ele for ele in lst[1:] if ele < pivot ]
right = [ ele for ele in lst[1:] if ele >= pivot ]
return quick_sort(left) + [pivot,] + quick_sort(right)
def split_bfile(bfile):
count = 0
nums = []
for line in readline_by_yield(bfile):
num = int(line)
if num not in nums:
nums.append(num)
if 10000 == len(nums):
nums = quick_sort(nums)
with open('subfile/subfile{}.txt'.format(count+1),'w') as wf:
wf.write('\n'.join([ str(i) for i in nums ]))
nums[:] = []
count += 1
print count
now = time.time()
split_bfile('total.txt')
run_t = time.time()-now
print 'Runtime : {}'.format(run_t)會產生 50000 個小文件,每個小文件大小約在 96K左右。
程式在執行過程中,記憶體佔用一直處在 5424kB #左右

#整個檔案分割完耗時
 94146
94146
秒。 
#!/usr/bin/python2.7
# -*- coding: utf-8 -*-
import os
import time
testdir = '/ssd/subfile'
now = time.time()
# Step 1 : 获取全部文件描述符
fds = []
for f in os.listdir(testdir):
ff = os.path.join(testdir,f)
fds.append(open(ff,'r'))
# Step 2 : 每个文件获取第一行,即当前文件最小值
nums = []
tmp_nums = []
for fd in fds:
num = int(fd.readline())
tmp_nums.append(num)
# Step 3 : 获取当前最小值放入暂存区,并读取对应文件的下一行;循环遍历。
count = 0
while 1:
val = min(tmp_nums)
nums.append(val)
idx = tmp_nums.index(val)
next = fds[idx].readline()
# 文件读完了
if not next:
del fds[idx]
del tmp_nums[idx]
else:
tmp_nums[idx] = int(next)
# 暂存区保存1000个数,一次性写入硬盘,然后清空继续读。
if 1000 == len(nums):
with open('final_sorted.txt','a') as wf:
wf.write('\n'.join([ str(i) for i in nums ]) + '\n')
nums[:] = []
if 499999999 == count:
break
count += 1
with open('runtime.txt','w') as wf:
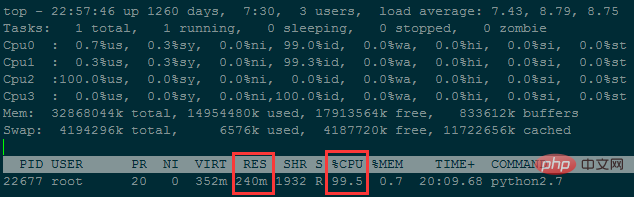
wf.write('Runtime : {}'.format(time.time()-now))程式在執行過程中,記憶體佔用一直處在240M左右
跑了38個小時左右,才合併完不到5千萬行資料...
雖然降低了記憶體使用,但時間複雜度太高了;可以透過減少檔案數(每個小檔案儲存行數增加)來進一步降低記憶體使用。
問題二:一個檔案有一千億行數據,每行是IP位址,需要對IP位址進行排序。 IP位址轉換成數字# 方法一:手动计算
In [62]: ip
Out[62]: '10.3.81.150'
In [63]: ip.split('.')[::-1]
Out[63]: ['150', '81', '3', '10']
In [64]: [ '{}-{}'.format(idx,num) for idx,num in enumerate(ip.split('.')[::-1]) ]
Out[64]: ['0-150', '1-81', '2-3', '3-10']
In [65]: [256**idx*int(num) for idx,num in enumerate(ip.split('.')[::-1])]
Out[65]: [150, 20736, 196608, 167772160]
In [66]: sum([256**idx*int(num) for idx,num in enumerate(ip.split('.')[::-1])])
Out[66]: 167989654
In [67]:
# 方法二:使用C扩展库来计算
In [71]: import socket,struct
In [72]: socket.inet_aton(ip)
Out[72]: b'\n\x03Q\x96'
In [73]: struct.unpack("!I", socket.inet_aton(ip))
# !表示使用网络字节顺序解析, 后面的I表示unsigned int, 对应Python里的integer or long
Out[73]: (167989654,)
In [74]: struct.unpack("!I", socket.inet_aton(ip))[0]
Out[74]: 167989654
In [75]: socket.inet_ntoa(struct.pack("!I", 167989654))
Out[75]: '10.3.81.150'
In [76]:問題三:有一個1.3GB的檔案(共一億行),裡面每一行都是一個字串,請在檔案中找出重複次數最多的字串。 基本概念
:迭代讀大文件,把大文件分割成多個小文件;最後再歸併這些小文件。分割的規則
:迭代讀取大文件,記憶體中維護字典,key是字串,value是該字串出現的次數;
當字典維護的字串種類達到10000(可自訂)的時候,把該字典依照key從小到大排序
,然後寫入小文件,每行是key\tvalue; 然後清空字典,繼續往下讀,直到大檔案讀完。歸併的規則:
首先取得全部小檔案的檔案描述子
,然後各自讀出第一行(即每個小檔案字串ascii值最小的字串),進行比較。 找出ascii值最小的字串,如果有重複的,這把各自出現的次數累加起來,然後把當前字串和總次數儲存到記憶體中的一個列表。 接著把最小字串所在的檔案的讀取指標向下移,也就是從對應小檔案再讀出一行進行下一輪比較。 當記憶體中的列表個數達到10000時,則一次把該列表內容寫到一個最終檔案儲存到硬碟上。同時清空列表,進行之後的比較。| , | 最後迭代去讀這個最終文件,找出重複次數最多的即可。 | 1. 分割 | 2. 歸併 | 歸併結果分析: | |
| 分割時記憶體中維護的字典大小 | 分割的小檔案個數 | 歸併時需維護的檔案描述子數 | 歸併時記憶體佔用 | 歸併耗時 | |
| 10000 | 9000 | 9000 ~ 0 | 200M | 歸併速度慢,暫未統計完成時間 |
900
900 ~ 027M######歸併速度快,只需2572秒#################3. 找出出現次數最多的字串及其次數######import time
def read_line(filepath):
with open(filepath,'r') as rf:
for line in rf:
yield line
start_ts = time.time()
max_str = None
max_count = 0
for line in read_line('merged.txt'):
string,count = line.strip().split('\t')
if int(count) > max_count:
max_count = int(count)
max_str = string
print(max_str,max_count)
print('Runtime {}'.format(time.time()-start_ts))###歸併後的檔案共9999788行,大小是256M;執行查找耗時27秒,記憶體佔用6480KB。 ###以上是一文了解大文件排序/外存排序問題的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undress AI Tool
免費脫衣圖片

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Python類中的多態性
Jul 05, 2025 am 02:58 AM
Python類中的多態性
Jul 05, 2025 am 02:58 AM
多態是Python面向對象編程中的核心概念,指“一種接口,多種實現”,允許統一處理不同類型的對象。 1.多態通過方法重寫實現,子類可重新定義父類方法,如Animal類的speak()方法在Dog和Cat子類中有不同實現。 2.多態的實際用途包括簡化代碼結構、增強可擴展性,例如圖形繪製程序中統一調用draw()方法,或遊戲開發中處理不同角色的共同行為。 3.Python實現多態需滿足:父類定義方法,子類重寫該方法,但不要求繼承同一父類,只要對象實現相同方法即可,這稱為“鴨子類型”。 4.注意事項包括保持方
 python`@classmethod'裝飾師解釋了
Jul 04, 2025 am 03:26 AM
python`@classmethod'裝飾師解釋了
Jul 04, 2025 am 03:26 AM
類方法是Python中通過@classmethod裝飾器定義的方法,其第一個參數為類本身(cls),用於訪問或修改類狀態。它可通過類或實例調用,影響的是整個類而非特定實例;例如在Person類中,show_count()方法統計創建的對像數量;定義類方法時需使用@classmethod裝飾器並將首參命名為cls,如change_var(new_value)方法可修改類變量;類方法與實例方法(self參數)、靜態方法(無自動參數)不同,適用於工廠方法、替代構造函數及管理類變量等場景;常見用途包括從
 Python函數參數和參數
Jul 04, 2025 am 03:26 AM
Python函數參數和參數
Jul 04, 2025 am 03:26 AM
參數(parameters)是定義函數時的佔位符,而傳參(arguments)是調用時傳入的具體值。 1.位置參數需按順序傳遞,順序錯誤會導致結果錯誤;2.關鍵字參數通過參數名指定,可改變順序且提高可讀性;3.默認參數值在定義時賦值,避免重複代碼,但應避免使用可變對像作為默認值;4.args和*kwargs可處理不定數量的參數,適用於通用接口或裝飾器,但應謹慎使用以保持可讀性。
 什麼是python的列表切片?
Jun 29, 2025 am 02:15 AM
什麼是python的列表切片?
Jun 29, 2025 am 02:15 AM
ListslicinginPythonextractsaportionofalistusingindices.1.Itusesthesyntaxlist[start:end:step],wherestartisinclusive,endisexclusive,andstepdefinestheinterval.2.Ifstartorendareomitted,Pythondefaultstothebeginningorendofthelist.3.Commonusesincludegetting
 解釋Python發電機和迭代器。
Jul 05, 2025 am 02:55 AM
解釋Python發電機和迭代器。
Jul 05, 2025 am 02:55 AM
迭代器是實現__iter__()和__next__()方法的對象,生成器是簡化版的迭代器,通過yield關鍵字自動實現這些方法。 1.迭代器每次調用next()返回一個元素,無更多元素時拋出StopIteration異常。 2.生成器通過函數定義,使用yield按需生成數據,節省內存且支持無限序列。 3.處理已有集合時用迭代器,動態生成大數據或需惰性求值時用生成器,如讀取大文件時逐行加載。注意:列表等可迭代對像不是迭代器,迭代器到盡頭後需重新創建,生成器只能遍歷一次。
 如何在Python中結合兩個列表?
Jun 30, 2025 am 02:04 AM
如何在Python中結合兩個列表?
Jun 30, 2025 am 02:04 AM
合併兩個列表有多種方法,選擇合適方式可提升效率。 1.使用 號拼接生成新列表,如list1 list2;2.使用 =修改原列表,如list1 =list2;3.使用extend()方法在原列表上操作,如list1.extend(list2);4.使用號解包合併(Python3.5 ),如[list1,*list2],支持靈活組合多個列表或添加元素。不同方法適用於不同場景,需根據是否修改原列表及Python版本進行選擇。
 如何處理Python中的API身份驗證
Jul 13, 2025 am 02:22 AM
如何處理Python中的API身份驗證
Jul 13, 2025 am 02:22 AM
處理API認證的關鍵在於理解並正確使用認證方式。 1.APIKey是最簡單的認證方式,通常放在請求頭或URL參數中;2.BasicAuth使用用戶名和密碼進行Base64編碼傳輸,適合內部系統;3.OAuth2需先通過client_id和client_secret獲取Token,再在請求頭中帶上BearerToken;4.為應對Token過期,可封裝Token管理類自動刷新Token;總之,根據文檔選擇合適方式,並安全存儲密鑰信息是關鍵。
 什麼是python魔法方法或dunder方法?
Jul 04, 2025 am 03:20 AM
什麼是python魔法方法或dunder方法?
Jul 04, 2025 am 03:20 AM
Python的magicmethods(或稱dunder方法)是用於定義對象行為的特殊方法,它們以雙下劃線開頭和結尾。 1.它們使對象能夠響應內置操作,如加法、比較、字符串表示等;2.常見用例包括對像初始化與表示(__init__、__repr__、__str__)、算術運算(__add__、__sub__、__mul__)及比較運算(__eq__、__lt__);3.使用時應確保其行為符合預期,例如__repr__應返回可重構對象的表達式,算術方法應返回新實例;4.應避免過度使用或以令人困惑的方
