
給大家講解了微信公眾號文章所收集的入口歷史消息頁資訊取得方法,有需要的朋友參考一下本內容。
採集微信文章和擷取網站內容一樣,都需要從一個清單頁開始。而微信文章的列表頁就是公眾號裡的查看歷史消息頁。現在網路上的其它微信採集器有的是利用搜狗搜索,採集方式雖然簡單多了,但是內容不全。所以我們還是要從最標準、最全面的公眾號歷史消息頁來收集。
因為微信的限制,我們能複製到的連結是不完整的,在瀏覽器中無法開啟看到內容。所以我們需要透過上一篇文章介紹的方法,使用anyproxy取得一個完整的微信公眾號歷史訊息頁面的連結位址。
http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=MjM5NDAwMTA2MA==&uin=NzM4MTk1ODgx&key=bf9387c4d02682e186a298a18276d8e058276d8 0edd80c9e1bfda66c2b62751511f7cc091a33a029709e94f0d1604e11220fc099a27b2e2d29db75cc0849d4&devicetype=android.1 ticket=Iox5ZdpRhrSxGYEeopVJwTBP7kZj51GYyEL24AT5Zyx+BoEMdPDBtOun1F/9ENSz&wx_header =1
前一篇文章提到過,biz參數是公眾號的ID,uin是使用者的ID,目前來看uin是在所有公眾號之間唯一的。其它兩個重要參數key和pass_ticket是微信客戶端補充上的參數。
所以在這個地址失效之前我們是可以透過瀏覽器查看原文的方法獲取到歷史消息的文章列表的,如果希望自動化分析內容,也可以製作一個程序,將這個帶有尚未失效的key和pass_ticket的連結位址提交進去,再透過例如php程式來取得到文章列表。
最近有朋友跟我說他的採集目標就是單一的一個公眾號,我覺得這樣就沒必要用上一篇文章寫的批量採集的方法了。所以我們接下來看看歷史消息頁裡面是怎麼取得到文章列表的,透過分析文章列表,就可以得到這個公眾號所有的內容連結地址,然後再採集內容就可以了。
在anyproxy的web介面中如果憑證配置正確,是可以顯示出https的內容的。 web介面的位址是http://localhost:8002 其中localhost可以替換成自己的IP位址或網域名稱。從清單中找到getmasssendmsg開頭的記錄,點擊之後右側就會顯示出這條記錄的詳情:
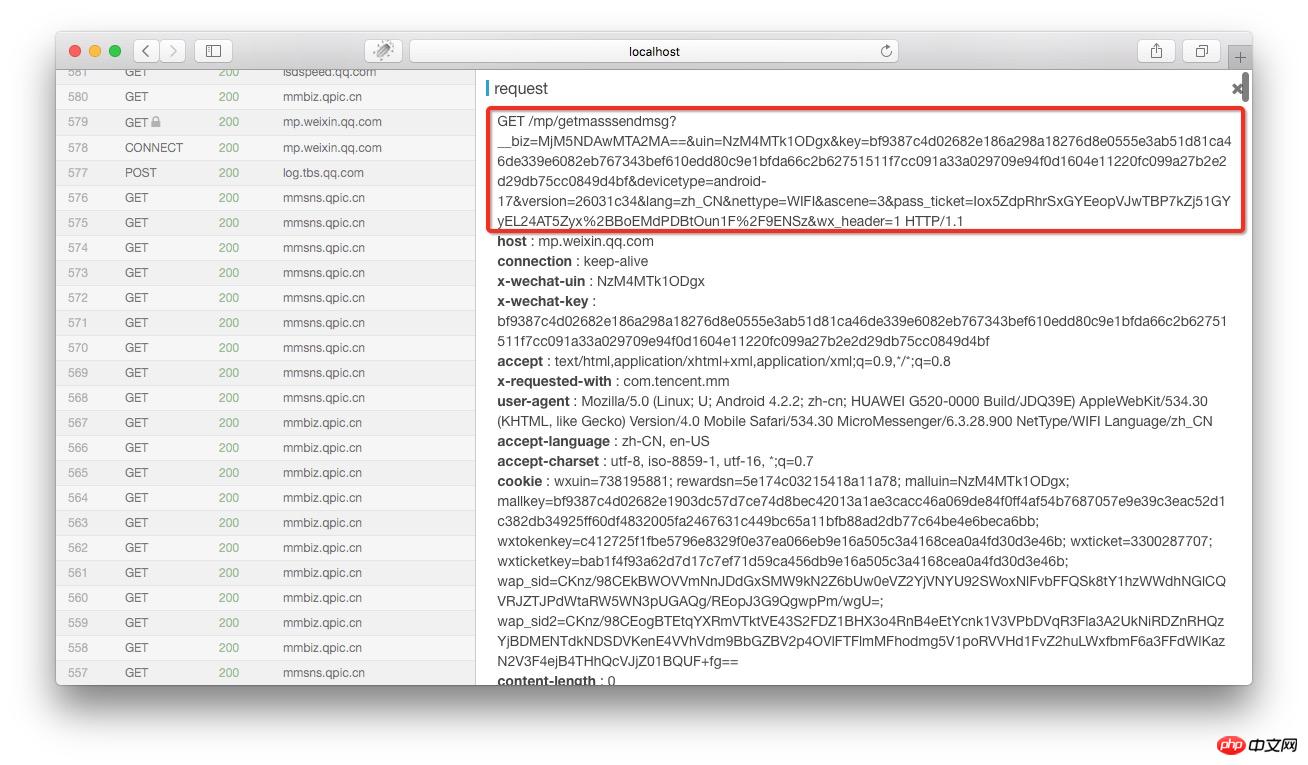
紅框部分就是完整的連結地址,將微信公眾平台這個網域拼接在前面之後就可以在瀏覽器中開啟了。
然後將頁面往下拉,到html內容的結尾部分,我們可以看到一個json的變數就是歷史訊息的文章列表:
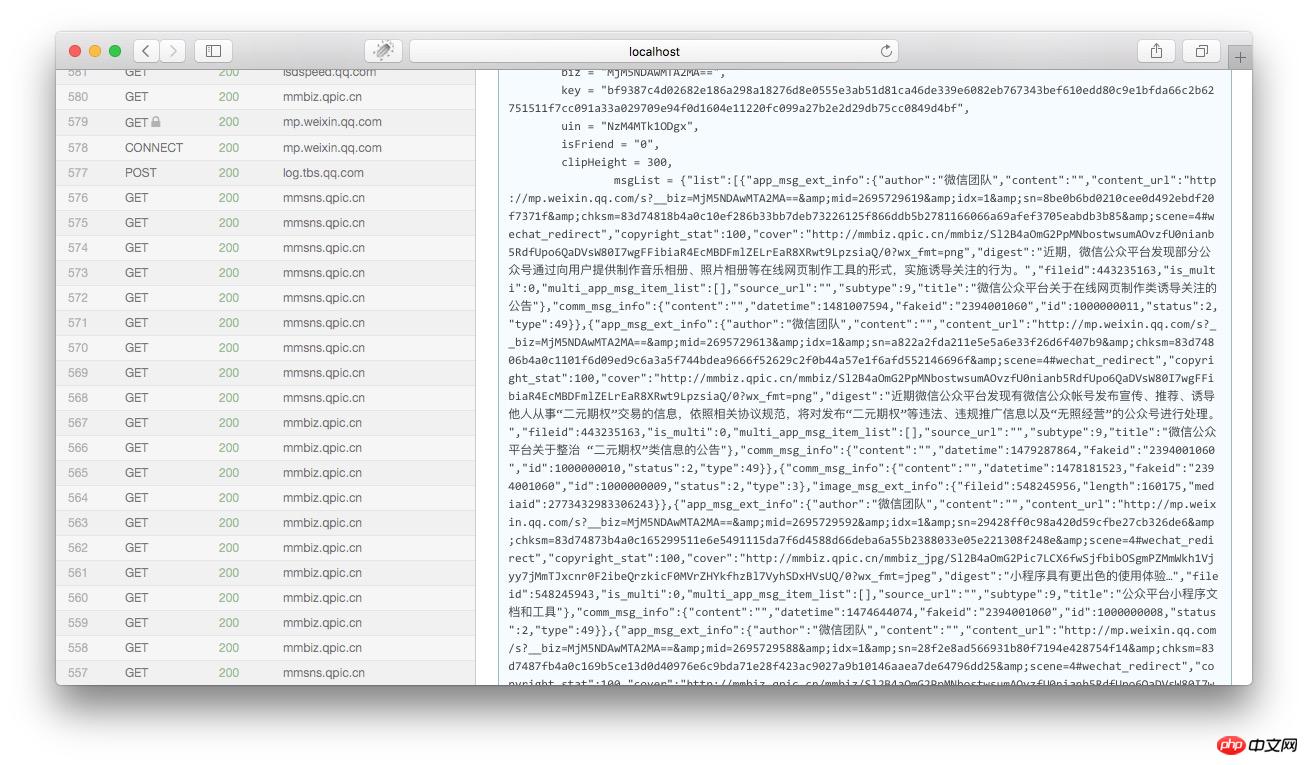
我們將msgList的變數值拷貝出來,用json格式化工具分析一下,我們就可以看到這個json是以下這個結構:
{ "list": [ { "app_msg_ext_info": { "author": "", "content": "", "content_url": "http://mp.weixin.qq.com/s?__biz=MzA5MzEzNDg3MQ==&mid=2652767427&idx=1&sn=37da0d7208283bf90e9a4a536e0af0ea&chksm=8b882dbbbcffa4ad2f0b8a141cc988d16bace564274018e68e5c53ee6f354f8ad56c9b98bade&scene=4#wechat_redirect", "copyright_stat": 100, "cover": "http://mmbiz.qpic.cn/mmbiz/MofBAcBsJ6X0xGrQ2XK5yQjzwb2eswxkRNBTgLtcqGziaFqwibzvtZAHCDkMeJU1fGZHpjoeibanPJ8rziaq68Akkg/0?wx_fmt=jpeg", "digest": "擦亮双眼,远离谣言。", "fileid": 505283695, "is_multi": 1, "multi_app_msg_item_list": [ { "author": "", "content": "", "content_url": "http://mp.weixin.qq.com/s?__biz=MzA5MzEzNDg3MQ==&mid=2652767427&idx=2&sn=449ef1a874a37fed2429e14f724b56ef&chksm=8b882dbbbcffa4ade48a7932cda4263687e34fca8ea3a5a6233d2589d448b9f6130d3890ce93&scene=4#wechat_redirect", "copyright_stat": 100, "cover": "http://mmbiz.qpic.cn/mmbiz_png/MofBAcBsJ6XyaIn0qEDSSicBUBZbMYHYrhibia89ZnksCsUiaia2TLI1fyqjclibGa1hw3icP6oXeSpaWMjiabaghHl7yw/0?wx_fmt=png", "digest": "12月28日,广州亚运城综合体育馆,内附购票入口~", "fileid": 0, "source_url": "http://wechat.show.wepiao.com/detail/ff764b0731b7465db03b56b998e1f2b8?detailReferrer=1&from=groupmessage&isappinstalled=0", "title": "2017微信公开课Pro版即将召开" }, ...//循环被省略 ], "source_url": "", "subtype": 9, "title": "谣言热榜 | 十一月朋友圈十大谣言" }, "comm_msg_info": { "content": "", "datetime": 1480933315, "fakeid": "3093134871", "id": 1000000010, "status": 2, "type": 49 //类型为49的时候是图文消息 } }, ...//循环被省略 ] }
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。 {//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里 "app_msg_ext_info":{//图文消息的扩展信息 "content_url": "图文消息的链接地址", "cover": "封面图片", "digest": "摘要", "is_multi": "是否多图文,值为1和0", "multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空 { "content_url": "图文消息的链接地址", "cover": "封面图片", "digest": ""摘要"", "source_url": "阅读原文的地址", "title": "子内容标题" }, ...//循环被省略 ], "source_url": "阅读原文的地址", "title": "头条标题" }, "comm_msg_info":{//图文消息的基本信息 "datetime": '发布时间,值为unix时间戳', "type": 49 //类型为49的时候是图文消息 } }, ...//循环被省略 ]
##
以上是如何擷取微信公眾號歷史消息頁的詳解的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































