本文我們主要和大家分享PHP底層運作機制詳解,首先我們會和大家分享PHP的設計理念及特點, PHP的四層體係等,希望能幫助大家。
多進程模型:由於PHP是多進程模型,不同請求間互不干涉,這樣保證了一個請求掛掉不會對全碟服務造成影響,當然,隨著時代發展,PHP也早已支援多執行緒模型。
弱型別語言:和C/C++、Java、C#等語言不同,PHP是一門弱型別語言。一個變數的類型並不是一開始就確定不變,運行中才會確定並可能發生隱式或顯式的類型轉換,這種機制的靈活性在web開發中非常方便、高效,具體會在後面PHP變數中詳述。
解釋語言:PHP正因為與C/C++、Java、C#等編譯性語言在運作步驟不同,PHP需要先經過詞法,語法分析等解析為編譯性語言,才能運行!所以在追求高效能等大型應用或大數據運算就不適合PHP,雖然0.001秒和0.1秒對瀏覽器使用者來說沒有什麼差別,但對於其它領域就不行
引擎(Zend)+元件(ext)的模式降低內部耦合。
中間層(sapi)隔絕web server和PHP。
文法簡單又靈活,沒有太多規範。缺點導致風格混雜,但再差的程式設計師也不會寫出太離譜危害全局的程式。
PHP的核心架構如下圖:
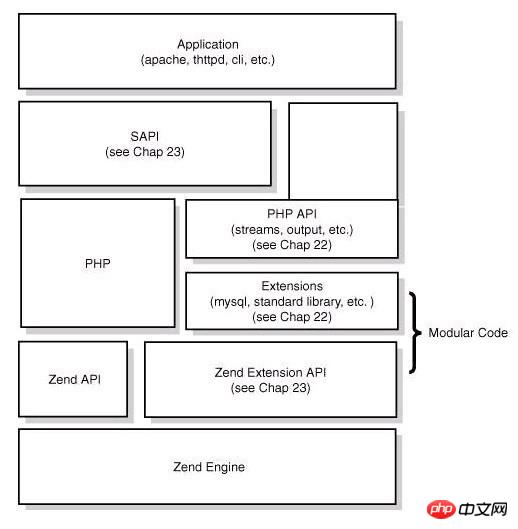
從圖上可以看出,PHP從下到上是一個4層體系:
Zend引擎:Zend整體用純C實現,是PHP的核心部分,它將PHP程式碼翻譯(詞法、語法解析等一系列編譯過程)為可執行opcode的處理並實現相應的處理方法、實現了基本的資料結構(如hashtable、oo)、記憶體分配及管理、提供了相應的api方法供外部調用,是一切的核心,所有的外圍功能均圍繞著Zend實現。
Extensions:圍繞著Zend引擎,extensions透過元件式的方式提供各種基礎服務,我們常見的各種內建函數(如array系列)、標準函式庫等都是透過extension來實現,使用者也可以根據需要實作自己的extension以達到功能擴充、效能最佳化等目的(如貼吧正在使用的PHP中間層、富文本解析就是extension的典型應用)。
Sapi:Sapi全名為Server Application Programming Interface,也就是服務端應用程式接口,Sapi透過一系列鉤子函數,使得PHP可以和外圍交互數據,這是PHP非常優雅和成功的一個設計,透過sapi成功的將PHP本身和上層應用解耦隔離,PHP可以不再考慮如何針對不同應用進行相容,而應用程式本身也可以針對自己的特點實現不同的處理方式。
上層應用程式:這就是我們平時編寫的PHP程序,透過不同的sapi方式得到各種各樣的應用模式,如透過webserver實現web應用程式、在命令列下以腳本方式運行等等。
如果PHP是一輛車,那麼車的框架就是PHP本身,Zend是車的引擎(引擎),Ext下面的各種組件就是車的輪子,Sapi可以看做是公路,車子可以跑在不同類型的公路上,而一次PHP程序的執行就是汽車跑在公路上。因此,我們需要:性能優異的引擎+合適的車輪+正確的跑道。
如前所述,Sapi透過透過一系列的接口,使得外部應用程式可以和PHP交換資料並可以根據不同應用特徵實現特定的處理方法,我們常見的一些sapi有:
apache2handler:這是以apache作為webserver,採用mod_PHP模式運行時的處理方式,也是現在應用最廣泛的一種。
cgi:這是webserver和PHP直接的另一種互動方式,也就是大名鼎鼎的fastcgi協議,在最近今年fastcgi+PHP得到越來越多的應用,也是異步webserver所唯一支援的方式。
cli:命令列呼叫的應用模式
我們先來看看PHP程式碼的執行所經過的流程。
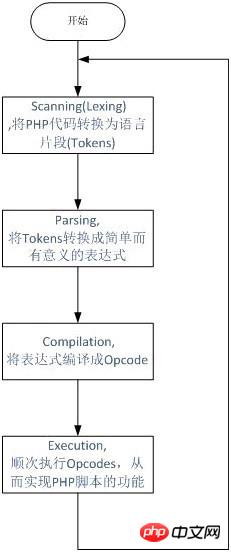
從圖上可以看到,PHP實作了一個典型的動態語言執行過程:拿到一段程式碼後,經過詞法解析、語法解析等階段後,原始程式會被翻譯成一個個指令(opcodes),然後ZEND虛擬機器順次執行這些指令完成操作。 PHP本身是用C來實現的,所以最後呼叫的也都是C的函數,實際上,我們可以把PHP看做是一個C開發的軟體。
PHP的執行的核心是翻譯出來的一條一條指令,也即opcode。
Opcode是PHP程式執行的最基本單位。一個opcode由兩個參數(op1,op2)、傳回值和處理函數組成。 PHP程式最終被翻譯為一組opcode處理函數的順序執行。
常見的幾個處理函數:
PHP
|
1 ##2#3456 |
ZEND_ASSIGN_SPEC_CV_CV_HANDLER : 變數分配($a=$b) ZEND_DO_FCALL_BY_NAME_SPEC_HANDLER:函數呼叫ZEND_CONCAT_SPEC_CV_CV_HANDLER:字串拼接$a.$bZEND_ADD_SPEC_CV_CONST_HANDLER: 加法運算 ##ZEND_ADD_SPEC_CV_CONST_HANDL_CV: 加法運算等運算元運算1 ZEND_IS_IDENTICAL_SPEC_CV_CONST:判斷相等$a===1 |
|
1 2 3 4 #5 6 7 8 9 10 |
#getKeyHashValueh; index=n&nTableMask ; Bucket*p=arBucket[index]; while(p){ if((p->h==h)&(p-> ;nKeyLength==nKeyLength)){ RETURNp->data; } p=p->next; } RETURNFALTURE; |
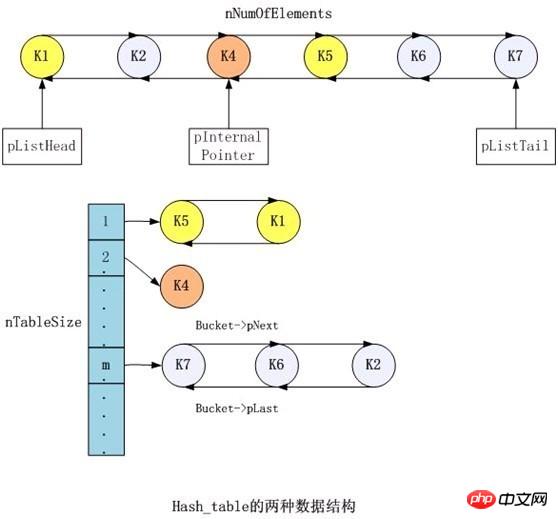
PHP索引數組:索引數組就是我們常見的數組,透過下標存取。例如 $arr[0],Zend HashTable內部進行了歸一化處理,對於index類型key同樣分配了hash值和nKeyLength(為0)。內部成員變數nNextFreeElement就是目前被指派的最大id,每次push後自動加一。正是這種歸一化處理,PHP才能夠實現關聯和非關聯的混合。由於push操作的特殊性,索引key在PHP數組中先後順序並不是透過下標大小來決定,而是由push的先後決定。例如
$arr[1] = 2; $arr[2] = 3;對於double類型的key,Zend HashTable會將他當做索引key處理
PHP是一門弱型別語言,本身不嚴格區分變項的型別。 PHP在變數申明的時候不需要指定型別。 PHP在程式運行期間可能會進行變數類型的隱示轉換。和其他強型別語言一樣,程式中也可以進行顯示的型別轉換。 PHP變數可以分為簡單型別(int、string、bool)、集合型別(array resource object)和常數(const)。以上所有的變數在底層都是同一種結構 zval。
Zval是zend中另一個非常重要的資料結構,用來識別並實作PHP變量,其資料結構如下:
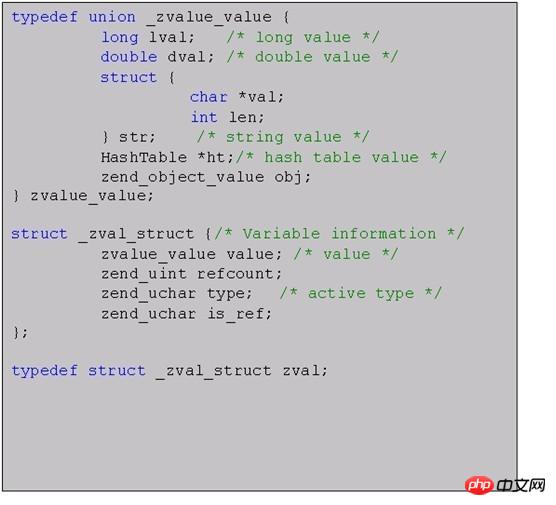
Zval主要由三部分組成:
type:指定了變數所述的類型(整數、字串、陣列等)
refcount&is_ref:用來實現引用計數(後面具體介紹)
value:核心部分,儲存了變數的實際資料
Zvalue是用來保存一個變數的實際數據。因為要儲存多種類型,所以zvalue是一個union,也因此實現了弱型別。
PHP變數類型和其實際儲存對應如下:
PHP
|
1 2 3 4 5 |
IS_LONG -> lvalue IS_DOUBLE -> dvalue IS_ARRAY -> ht IS_STRING -> str IS_RESOURCE -> lvalue |
引用計數在記憶體回收、字串操作等地方使用非常廣泛。 PHP中的變數就是引用計數的典型應用。 Zval的引用計數透過成員變數is_ref和ref_count實現,透過引用計數,多個變數可以共享同一份資料。避免頻繁拷貝帶來的大量消耗。
在進行賦值運算時,zend將變數指向相同的zval同時ref_count++,在unset運算時,對應的ref_count-1。只有ref_count減為0時才會真正執行銷毀操作。如果是引用賦值,則zend會修改is_ref為1。
PHP變數透過引用計數實現變數共享數據,那如果改變其中一個變數值呢?當試圖寫入一個變數時,Zend若發現該變數指向的zval被多個變數共享,則為其複製一份ref_count為1的zval,並遞減原zval的refcount,這個過程稱為「zval分離」。可見,只有在有寫入操作發生時zend才進行拷貝操作,因此也叫copy-on-write(寫時拷貝)
對於引用型變量,其要求和非引用型相反,引用賦值的變數間必須是捆綁的,修改一個變數就修改了所有捆綁變數。
整數、浮點數是PHP中的基礎型別之一,也是簡單型變數。對於整數和浮點數,在zvalue中直接儲存對應的值。其型別分別是long和double。
從zvalue結構可以看出,對於整數型,和c等強型別語言不同,PHP是不區分int、unsigned int、long、long long等型別的,對它來說,整數只有一種類型也就是long。由此,可以看出,在PHP裡面,整數的值範圍是由編譯器位數來決定而不是固定不變的。
對於浮點數,類似整數,它也不區分float和double而是統一隻有double一種型別。
在PHP中,如果整數範圍越界了怎麼辦?這種情況下會自動轉換為double類型,這個一定要小心,很多trick都是由此產生。
和整數一樣,字元變數也是PHP中的基礎型別和簡單型變數。透過zvalue結構可以看出,在PHP中,字串是由指向實際資料的指標和長度結構體組成,這點和c++中的string比較類似。由於透過一個實際變數表示長度,和c不同,它的字串可以是2進位資料(包含),同時在PHP中,求字串長度strlen是O(1)運算。
在新增、修改、追加字串操作時,PHP都會重新分配記憶體產生新的字串。最後,基於安全考慮,PHP在產生一個字串時結尾仍會加上
常見的字串拼接方式及速度比較:
假設有以下4個變數:$strA= '123'; $strB = '456'; $intA=123; intB=456;
現在對如下的幾個字串拼接方式做一個比較和說明:
#PH
|
1 2 #3 ##4##5 #6 7 8 | $res=$strA.$strB和$res=“$strA$strB” 這種情況下,zend會重新malloc一塊記憶體並進行對應處理,其速度一般 $strA=$strA.$strB 這種是速度最快的, zend會在目前strA基礎上直接relloc,避免重複拷貝 $res=$intA.$intB 這種速度較慢,因為需要做隱含的格式轉換,實際寫程式中也應該注意盡量避免 $strA=sprintf(“%s%s”,$strA.$strB); 這會是最慢的一種方式,因為sprintf在PHP中並不是語言結構,本身對於格式辨識與處理就需要耗費比較多時間,另外本身機制也是malloc。不過sprintf的方式最具可讀性,實際中可以根據具體情況靈活選擇。 |
以上是PHP底層運作機制詳解的詳細內容。更多資訊請關注PHP中文網其他相關文章!