

抓取四川大學公共管理學院官網()所有的新聞諮詢.
#1.確定抓取目標.
2.制定抓取規則.
3.'編寫/調試'抓取規則.
4.獲得抓取資料
我們這次需要抓取的目標為四川大學公共管理學院的所有新聞資訊.於是我們需要知道公管學院官網的佈局結構.
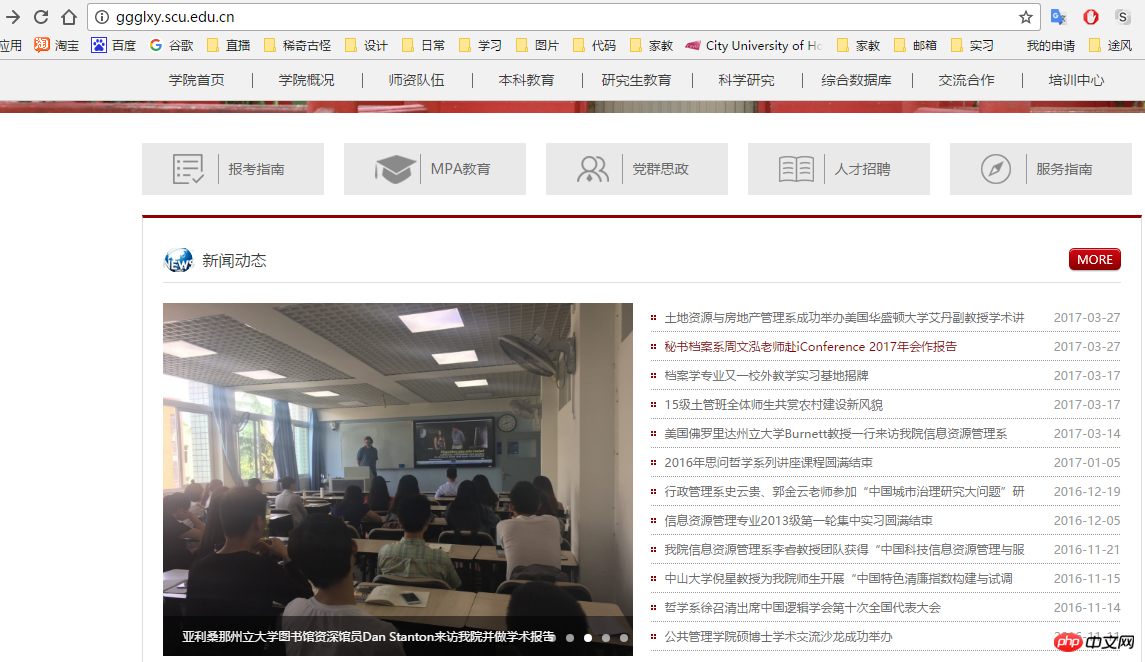
#這裡我們發現想要抓到全部的新聞資訊,不能直接在官網首頁進行抓取,需要點擊"more"進入到新聞總欄目裡面.

我們看到了具體的新聞欄位,但是這顯然不滿足我們的抓取需求: 當前新聞動態網頁只能抓取新聞的時間,標題和URL,但是並不能抓取新聞的內容.所以我們想要需要進入到新聞詳情頁抓取新聞的具體內容.
#透過第一部分的分析,我們會想到,如果我們要抓取一篇新聞的具體資訊,需要從新聞動態頁面點擊進入新聞詳情頁抓取到新聞的具體內容.我們點擊一篇新聞嘗試一下

我們發現,我們能夠直接在新聞詳情頁面抓取到我們需要的資料:標題,時間,內容.URL.
好,到現在我們清楚抓取一篇新聞的思路了.但是,如何抓取所有的新聞內容呢?
這顯然難不到我們.
 那麼整理一下思路,我們能夠想到一個顯而易見的抓取規則:
那麼整理一下思路,我們能夠想到一個顯而易見的抓取規則:通過抓取'新聞欄目下'所有的新聞鏈接,並且進入到新聞詳情鏈接裡面抓取所有的新聞內容.
在爬蟲中,我將實現以下幾個功能點:
1.爬出一頁新聞專欄下的所有新聞連結分別對應的知識點為:2.透過爬到的一頁新聞連結進入到新聞詳情爬取所需要資料(主要是新聞內容)
3 .透過循環爬取到所有的新聞.
1.爬出一個頁面下的基礎資料.話不多說,現在開幹.#3.1爬出一頁新聞欄位下的所有新聞連結2 .透過爬到的資料進行二次爬取.
3.透過循環對網頁進行所有資料的爬取.


import scrapyclass News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first()) ##Paste_Image.png
##Paste_Image.png編寫代碼
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):item = GgglxyItem()item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()item['href'] = responseitem['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")item['content'] = data[0].xpath('string(.)').extract()[0]
yield itemimport scrapyfrom ggglxy.items import GgglxyItemclass News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())#调用新闻抓取方法yield scrapy.Request(url, callback=self.parse_dir_contents)#进入新闻详情页的抓取方法 def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]yield item測試,通過!
 Paste_Image.png
Paste_Image.pngNEXT_PAGE_NUM = 1
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUM
yield scrapy.Request(next_url, callback=self.parse)加入原本程式碼:
import scrapyfrom ggglxy.items import GgglxyItem
NEXT_PAGE_NUM = 1class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
URL = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())yield scrapy.Request(URL, callback=self.parse_dir_contents)global NEXT_PAGE_NUM
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:
next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUMyield scrapy.Request(next_url, callback=self.parse) def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0] yield item測試:
 Paste_Image.png
Paste_Image.png抓到的数量为191,但是我们看官网发现有193条新闻,少了两条.
为啥呢?我们注意到log的error有两条:
定位问题:原来发现,学院的新闻栏目还有两条隐藏的二级栏目:
比如:

对应的URL为

URL都长的不一样,难怪抓不到了!
那么我们还得为这两条二级栏目的URL设定专门的规则,只需要加入判断是否为二级栏目:
if URL.find('type') != -1: yield scrapy.Request(URL, callback=self.parse)
组装原函数:
import scrapy
from ggglxy.items import GgglxyItem
NEXT_PAGE_NUM = 1class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
URL = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())if URL.find('type') != -1:yield scrapy.Request(URL, callback=self.parse)yield scrapy.Request(URL, callback=self.parse_dir_contents)
global NEXT_PAGE_NUM
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:
next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUMyield scrapy.Request(next_url, callback=self.parse) def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0] yield item测试:

我们发现,抓取的数据由以前的193条增加到了238条,log里面也没有error了,说明我们的抓取规则OK!
<code class="haxe"> scrapy crawl <span class="hljs-keyword">new<span class="hljs-type">s_info_2 -o <span class="hljs-number">0016.json</span></span></span></code><br/><br/>
以上是scrapy抓取學院新聞報告實例的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















