

這次爬取的是喜馬拉雅的熱門專欄下全部電台的每個頻道的信息和頻道中的每個音頻數據的各種信息,然後把爬取的數據儲存到mongodb以備後續使用。這次數據量在70萬左右。音訊資料包括音訊下載位址,頻道訊息,簡介等等,非常多。
昨天進行了人生中第一次面試,對方是一家人工智慧大數據公司,我準備在這大二的暑假去實習,他們就要求有爬取過音頻數據,所以我就來分析一下喜馬拉雅的音訊資料爬下來。目前我還在等待三面中,或是通知最終面試訊息。 (因為能得到一定肯定,不管成功與否都很開心)
IDE:Pycharm 2017
lxml 3.7.2


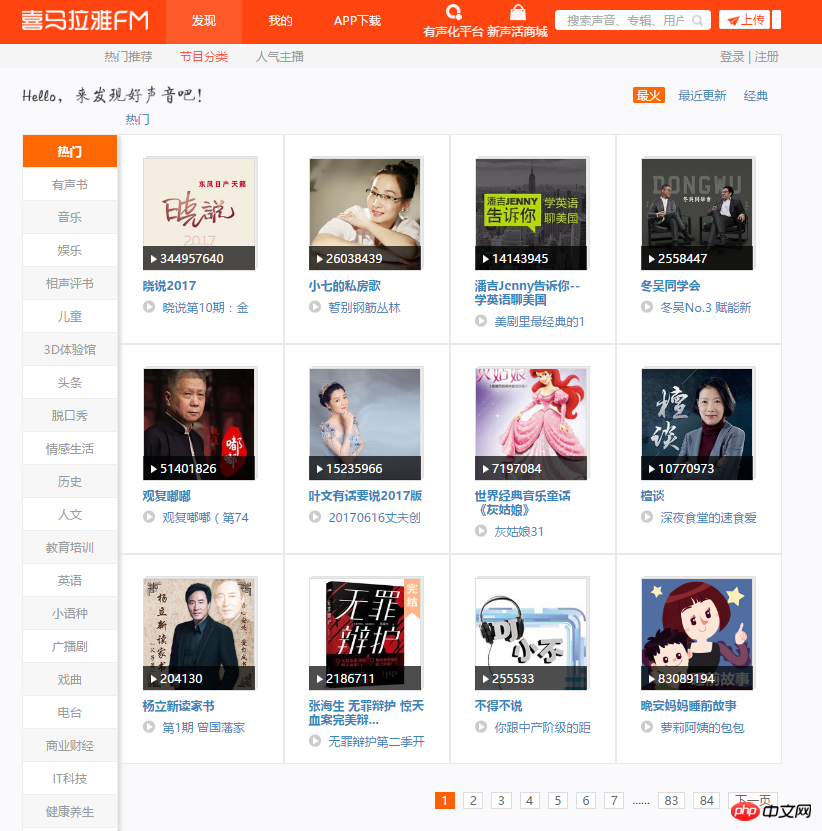
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]for start_url in start_urls:html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')for item in soup.find_all(class_="albumfaceOutter"):content = {'href': item.a['href'],'title': item.img['alt'],'img_url': item.img['src']
}
print(content)
分析頻道
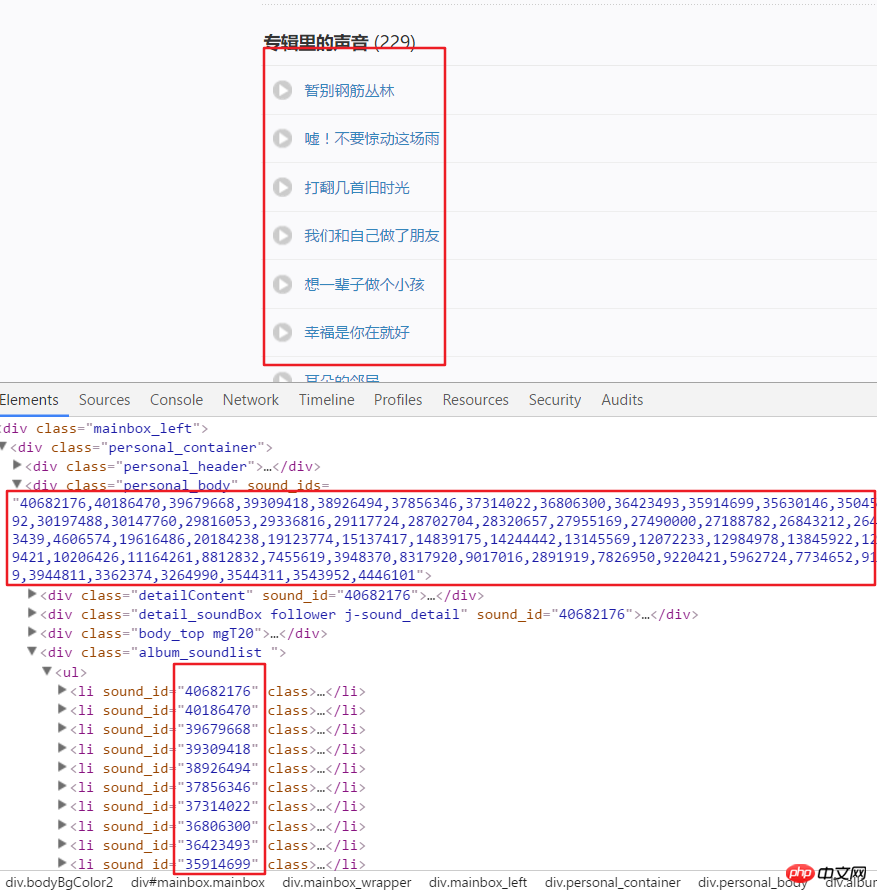
 3.以下就是開始取得每個頻道中的全部音訊資料了,前面透過解析頁面取得了美國頻道的連結。例如我們進入 這個連結後分析頁面結構。可以看出每個音訊都有特定的ID,這個ID可以在一個div中的屬性中取得。使用split()和int()來轉換為單獨的ID。
3.以下就是開始取得每個頻道中的全部音訊資料了,前面透過解析頁面取得了美國頻道的連結。例如我們進入 這個連結後分析頁面結構。可以看出每個音訊都有特定的ID,這個ID可以在一個div中的屬性中取得。使用split()和int()來轉換為單獨的ID。 頻道頁面分析
4.接著點擊一個音訊鏈接,進入開發者模式後刷新頁面然後點擊XHR,再點擊一個json連結可以看到這個就包括這個音訊的全部詳細資訊。
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)html = requests.get(murl, headers=headers1).text
dic = json.loads(html)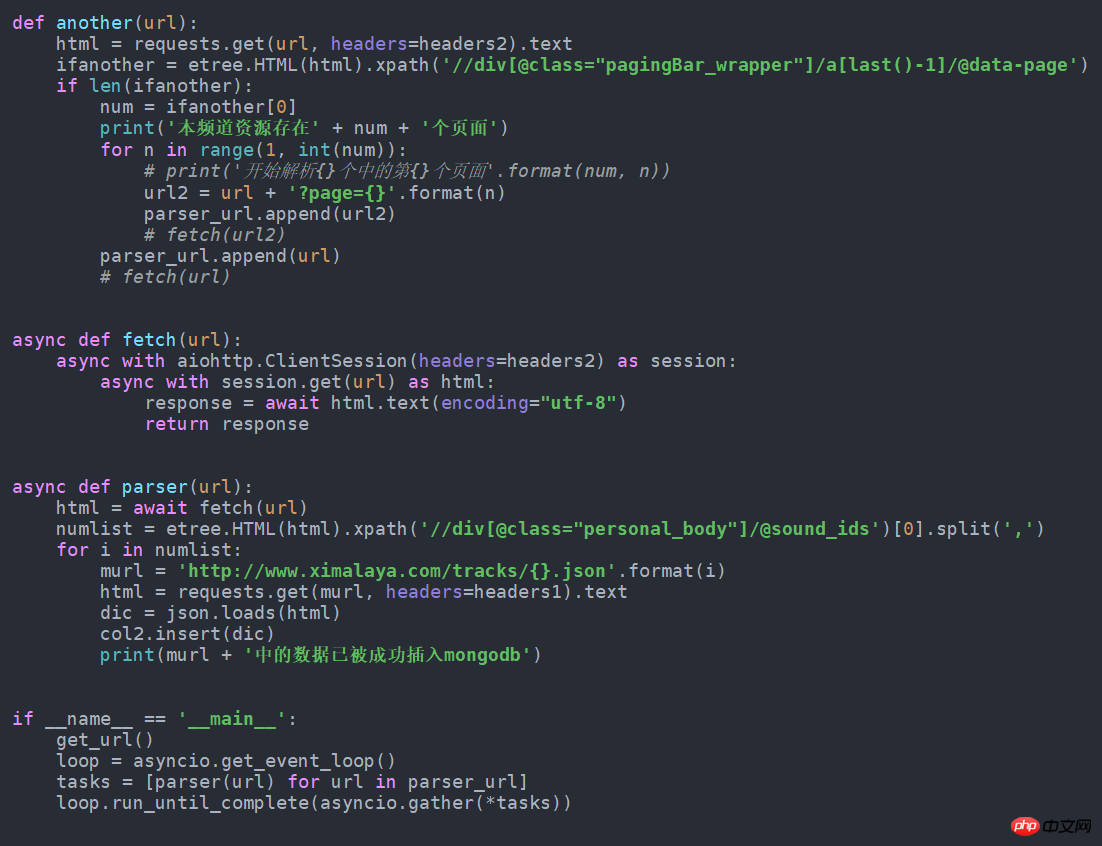
html = requests.get(url, headers=headers2).text
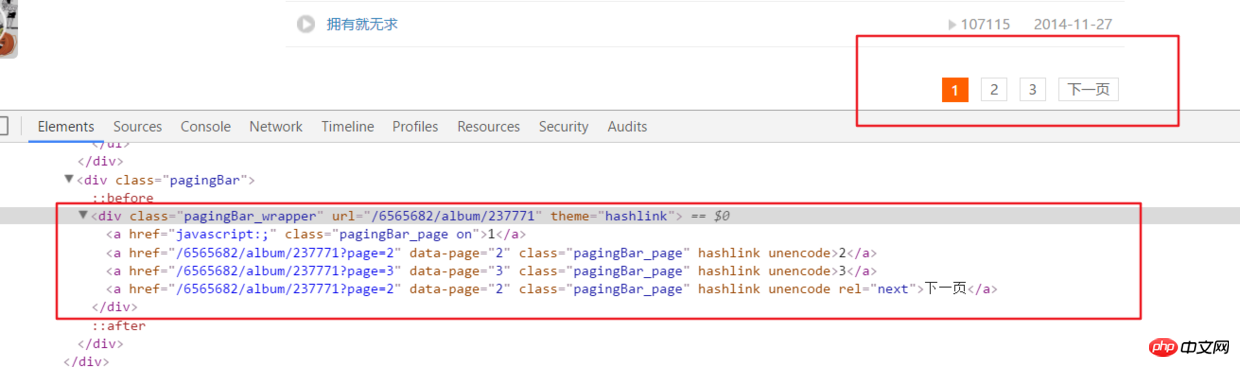
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')if len(ifanother):num = ifanother[0]
print('本频道资源存在' + num + '个页面')for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)# 之后就接解析音频页函数就行,后面有完整代码说明__author__ = '布咯咯_rieuse'import jsonimport randomimport timeimport pymongoimport requestsfrom bs4 import BeautifulSoupfrom lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')for item in soup.find_all(class_="albumfaceOutter"):
content = {'href': item.a['href'],'title': item.img['alt'],'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')if __name__ == '__main__':
get_url()以上是Python爬蟲之音頻資料實例的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















