Read Uncommitted(讀取未提交內容)
在該隔離級別,所有事務都可以看到其他未提交交易的執行結果。本隔離等級很少用於實際應用,因為它的效能也不比其他等級好多少。讀取未提交的數據,也稱為髒讀(Dirty Read)。
Read Committed(讀取提交內容)
這是大多數資料庫系統的預設隔離等級(但不是MySQL預設的)。它滿足了隔離的簡單定義:一個交易只能看見已經提交事務所所做的改變。這種隔離等級 也支援所謂的不可重複讀取(Nonrepeatable Read),因為同一事務的其他實例在該實例處理其間可能會有新的commit,所以同一select可能會傳回不同結果。
Repeatable Read(可重讀)
這是MySQL的預設事務隔離級別,它確保相同事務的多個實例在同時讀取資料時,會看到同樣的資料行。不過理論上,這會導致另一個棘手的問題:幻讀 (Phantom Read)。簡單的說,幻讀指當使用者讀取某一範圍的資料行時,另一個事務又在該範圍內插入了新行,當使用者再讀取該範圍的資料行時,會發現有新的“幻影” 行。 InnoDB和Falcon儲存引擎透過多版本並發控制(MVCC,Multiversion Concurrency Control)機制解決了這個問題。
Serializable(可串列化)
這是最高的隔離級別,它透過強制事務排序,使其不可能相互衝突,從而解決幻讀問題。簡言之,它是在每個讀取的資料行上加上共享鎖定。在這個級別,可能導致大量的超時現象和鎖定競爭。
這四種隔離等級採取不同的鎖定類型來實現,若讀取的是同一個資料的話,就容易發生問題。例如:
髒讀(Drity Read):某個事務已更新一份數據,另一個事務在此時讀取了同一份數據,由於某些原因,前一個RollBack了操作,則後者事務所讀取的資料就會是不正確的。
已無法重複讀取(Non-repeatable read):在一個事務的兩次查詢之中資料不一致,這可能是兩次查詢過程中間插入了一個事務更新的原有的數據。
幻讀(Phantom Read):在一個事務的兩次查詢中資料筆數不一致,例如有一個事務查詢了幾列(Row)數據,而另一個事務卻在此時插入了新的幾列數據,先前的事務在接下來的查詢中,就會發現有幾列數據是它先前所沒有的。
在MySQL中,實現了這四種隔離級別,分別有可能產生問題如下:

下面,將利用MySQL的用戶端程序,分別測試幾個隔離等級。測試資料庫為test,表為tx;表格結構:
num |
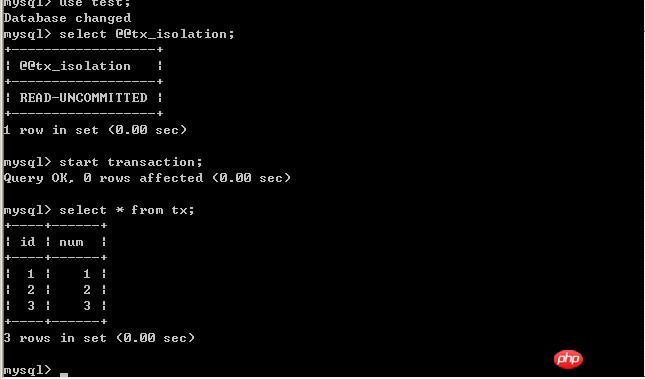
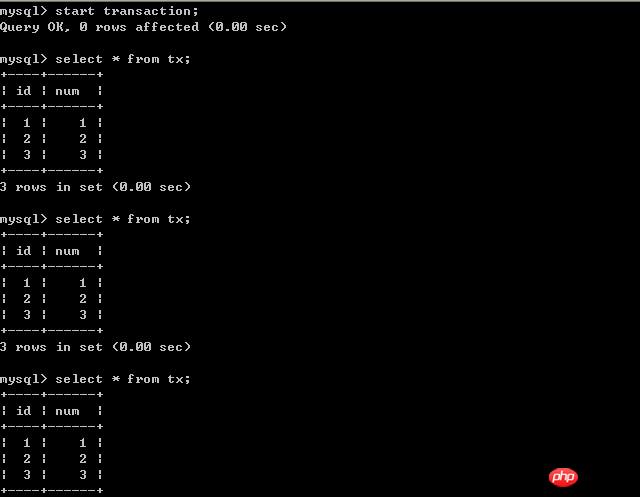
# 兩個命令列客戶端分別為A,B;不斷改變A的隔離級別,在B端修改資料。 (一)、將A的隔離等級設定為read uncommitted(未提交讀取) 在B未更新資料之前: 客戶端A: B更新資料: 客戶端B:
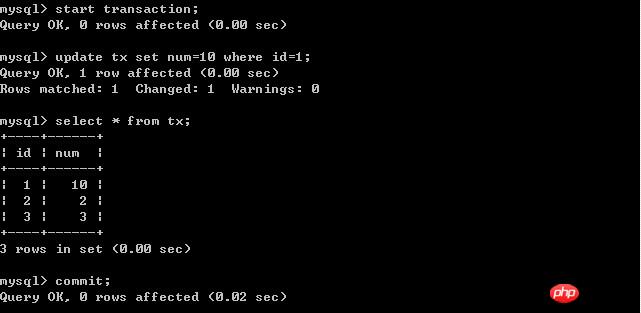
#客戶端A:
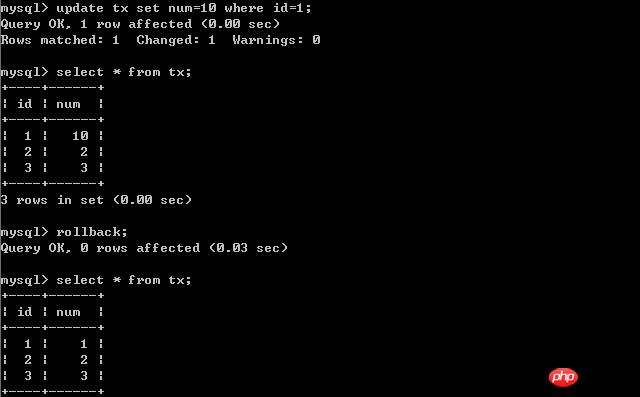
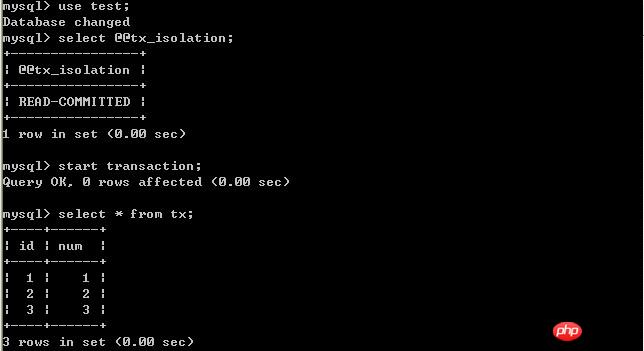
經過上面的實驗可以得出結論,事務B更新了一筆記錄,但是沒有提交,此時事務A可以查詢出未提交記錄。造成髒讀現象。未提交讀取是最低的隔離等級。 (二)、將客戶端A的交易隔離等級設定為read committed(已提交讀取) 在B未更新資料之前: 客戶端A:
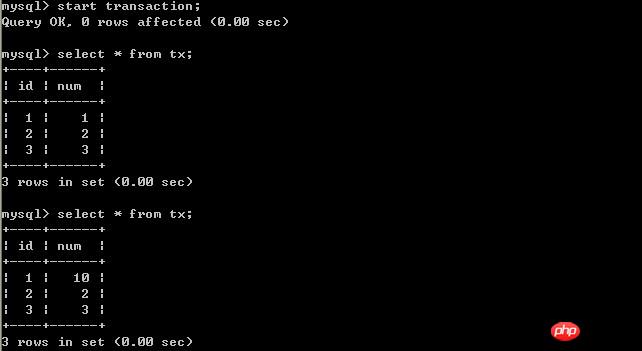
# #B更新資料: 客戶端B:
客戶端A:
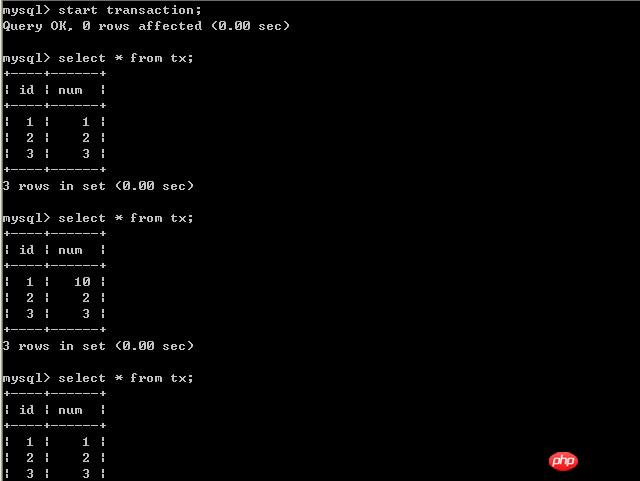
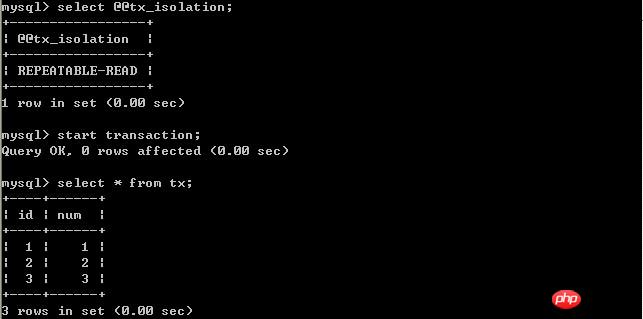
經過上面的實驗可以得出結論,已提交讀取隔離等級解決了髒讀的問題,但是出現了不可重複讀取的問題,即事務A在兩次查詢的資料不一致,因為在兩次查詢之間事務B更新了一條資料。已提交讀取只允許讀取已提交的記錄,但不要求可重複讀取。 (三)、將A的隔離等級設定為repeatable read(可重複讀取) 在B未更新資料之前: 客戶端A:
B更新數據: 客戶端B:
客戶端A:
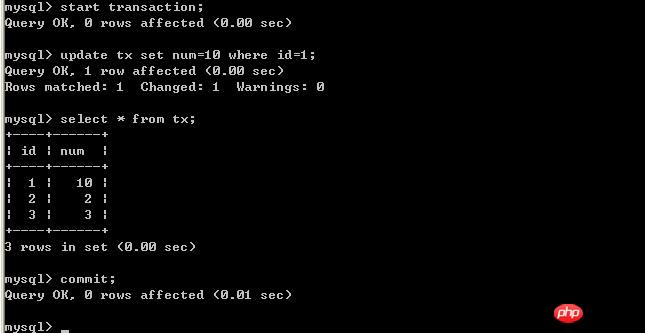
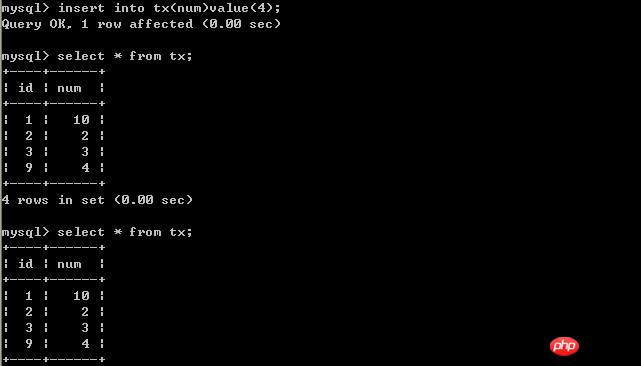
#B插入資料: #客戶端B:
#客戶端A:
以上的實驗可以得出結論,可重複讀取隔離等級只允許讀取已提交記錄,而且在一個事務兩次讀取一個記錄期間,其他事務部的更新該記錄。但該事務不要求與其他事務可串行化。例如,當一個交易可以找到由一個已提交交易更新的記錄,但是可能產生幻讀問題(注意是可能,因為資料庫對隔離等級的實作有所差別)。像以上的實驗,就沒有出現數據幻讀的問題。 (四)、將A的隔離等級設定為 可串列化 (Serializable) #A端開啟事務,B端插入一筆記錄 交易A端:
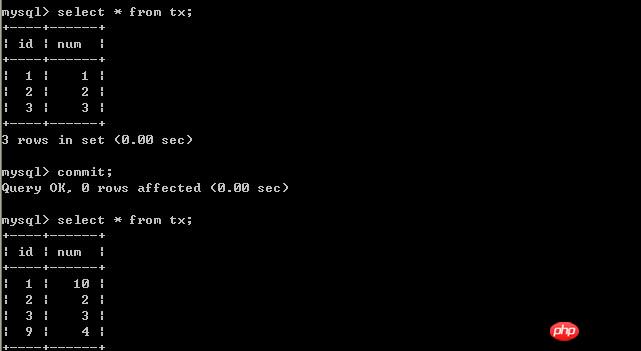
交易B端:
#因為此時事務A的隔離等級設定為serializable,開始事務後,並沒有提交,所以事務B只能等待。 交易A提交交易:
#交易A端
#交易B端 ################### ###################################################################################1 #serializable完全鎖定字段,若一個事務來查詢同一份資料就必須等待,直到前一個事務完成並解除鎖定為止 。 是完整的隔離級別,會鎖定對應的資料表格,因而會有效率的問題。 |
以上是深入了解mysql中4類隔離級別的詳細內容。更多資訊請關注PHP中文網其他相關文章!