

本文首先簡單介紹了垃圾收集的常見方式,然後再分析了G1收集器的收集原理,相比其他垃圾收集器的優勢,最後給出了一些調優實踐。
首先,在了解G1之前,我們需要清楚的知道,垃圾回收是什麼?簡單的說垃圾回收就是回收記憶體中不再使用的物件。
垃圾回收的基本步驟
回收的步驟有2步驟:
#尋找記憶體中不再使用的物件
釋放這些物件所佔用的記憶體
1,找出記憶體中不再使用的物件
那麼問題來了,如何判斷哪些物件不再被使用呢?引用指向,則可視之為垃圾。名為」GC Roots」的物件作為起始點,從這些節點開始向下搜索,搜索所走過的路徑稱為引用鏈(Reference Chain),當一個物件到GC Roots沒有任何引用鏈相連時,則證明此物件是不可用的。 ##常見的方式有複製或直接清理,但直接清理會存在記憶體碎片,於是就會產生了清理再壓縮的方式。
##1.標記-複製到另外一塊上面,然後在把已使用過的記憶體空間一次理掉。 。的優點是效率高,缺點是容易產生記憶體碎片。是在清理無用對象完成後讓所有存活的對像都向一端移動,並更新引用其對象的指針。 。就把記憶分成新生代和老年代,新生代存放剛創建的和存活時間比較短的對象,老年代存放存活時間比較長的對象。這樣每次只清理年輕代,老年代僅在必要時再做清理可以極大的提高GC效率,節省GC時間。 java垃圾收集器的歷史
在jdk1.3.1之前,java虛擬機器只能使用Serial收集器。 Serial收集器是一個單線程的收集器,但它的“單線程”的意義並不僅僅是說明它只會使用一個CPU或一條收集線程去完成垃圾收集工作,更重要的是在它進行垃圾收集時,必須暫停其他所有的工作線程,直到它收集結束。
PS:開啟Serial收集器的方式
-XX:+UseSerialGC
第二階段,Parallel(並行)收集器
Parallel收集器也稱為吞吐量收集器,相較於Serial收集器,Parallel最主要的優勢在於使用多執行緒去完成垃圾清理工作,這樣可以充分利用多核心的特性,大幅降低gc時間。
PS:開啟Parallel收集器的方式
-XX:+UseParallelGC -XX:+UseParallelOldGC
第三階段,CMS(並發)收集器
CMS收集器在Minor GC時會暫停所有的應用線程,並以多線程的方式進行垃圾回收。在Full GC時不再暫停應用線程,而是使用若干個後台線程定期的對老年代空間進行掃描,及時回收其中不再使用的物件。 PS:開啟CMS收集器的方式
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
##第四階段,G1(並發)收集器G1收集器(或垃圾優先收集器)的設計初衷是為了盡量縮短處理超大堆(大於4GB)時產生的停頓。相對於CMS的優勢而言是記憶體碎片的產生率大大降低。 PS:開啟G1收集器的方式-XX:+UseG1GCG1的第一篇paper(附錄1)發表於2004年,在2012年才在jdk1.7u4中可用。 oracle官方計劃在jdk9中將G1變成預設的垃圾收集器,以取代CMS。為何oracle要極力推薦G1呢,G1有哪些優點?
首先,G1的設計原則就是簡單可行的效能調優
#開發人員只需要宣告下列參數:
-XX: +UseG1GC -Xmx32g -XX:MaxGCPauseMillis=200
#其中-XX:+UseG1GC為開啟G1垃圾收集器,-Xmx32g 設計堆記憶體的最大記憶體為32G,-XX:MaxGCPauseMillis=200設定GC的最大暫停時間為200ms。如果我們需要調優,在記憶體大小一定的情況下,我們只需要修改最大暫停時間。
其次,G1將新生代,老年代的物理空間劃分取消了。
這樣我們再也不用單獨的空間對每個代進行設定了,不用擔心每個代記憶體是否足夠。

取代的是,G1演算法將堆劃分為若干個區域(Region),它仍然屬於分代收集器。不過,這些區域的一部分包含新生代,新生代的垃圾收集依然採用暫停所有應用線程的方式,將存活物件拷貝到老年代或Survivor空間。老年代也分成許多區域,G1收集器透過將物件從一個區域複製到另一個區域,完成了清理工作。這就意味著,在正常的處理過程中,G1完成了堆的壓縮(至少是部分堆的壓縮),這樣也就不會有cms記憶體碎片問題的存在了。

在G1中,還有一種特殊的區域,叫Humongous區域。 如果一個物件佔用的空間超過了分割容量50%以上,G1收集器就認為這是一個巨型物件。這些巨型對象,預設直接會被分配在年老代,但是如果它是一個短期存在的巨型對象,就會對垃圾收集器造成負面影響。為了解決這個問題,G1劃分了一個Humongous區,它用來專門存放巨型物件。如果一個H區裝不下一個巨型對象,那麼G1就會尋找連續的H分區來存放。為了能找到連續的H區,有時候不得不啟動Full GC。
PS:在java 8中,持久代也移動到了普通的堆記憶體空間中,改為元空間。
物件分配策略
說起大物件的分配,我們不得不談談物件的分配策略。它分為3個階段:
TLAB(Thread Local Allocation Buffer)執行緒本地分配緩衝區
Eden區中分配
Humongous區分配
TLAB為執行緒本地分配緩衝區,它的目的為了使物件盡可能快的分配出來。如果物件在共享的空間中分配,我們需要採用一些同步機制來管理這些空間內的空閒空間指標。在Eden空間中,每個執行緒都有一個固定的分區用來分配對象,也就是一個TLAB。分配物件時,執行緒之間不再需要進行任何的同步。
對TLAB空間中無法指派的對象,JVM會嘗試在Eden空間中進行指派。如果Eden空間無法容納該對象,就只能在老年代中進行分配空間。
最後,G1提供了兩種GC模式,Young GC和Mixed GC,兩種都是Stop The World(STW)的。下面我們將分別介紹這2種模式。
Young GC主要是對Eden區進行GC,它在Eden空間耗盡時會被觸發。在這種情況下,Eden空間的資料移動到Survivor空間中,如果Survivor空間不夠,Eden空間的部分資料會直接晉升到年老代空間。 Survivor區的資料移動到新的Survivor區中,也有部分資料晉升到老年代空間。最終Eden空間的資料為空,GC停止運作,應用執行緒繼續執行。
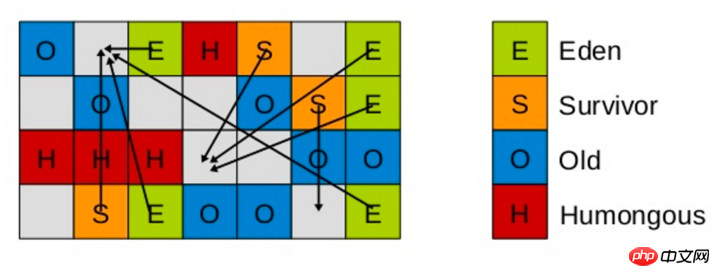

這時,我們需要考慮一個問題,如果僅僅GC 新生代對象,我們如何找到所有的根物件呢? 老年代的所有物件都是根呢?那這樣掃描下來會耗費大量的時間。於是,G1引進了RSet的概念。它的全名是Remembered Set,作用是追蹤指向某個heap區內的物件參考。

在CMS中,也有RSet的概念,在老年代中有一塊區域用來記錄指向新生代的引用。這是一種point-out,在進行Young GC時,掃描根時,只需掃描這一區域,而不需要掃描整個老年代。
但在G1中,並沒有使用point-out,這是由於一個分區太小,分區數量太多,如果是用point-out的話,會造成大量的掃描浪費,有些根本不需要GC的分區引用也掃描了。於是G1中使用point-in來解決。 point-in的意思是哪些分區引用了目前分區中的物件。這樣,僅僅將這些物件當作根來掃描就避免了無效的掃描。由於新生代有多個,那麼我們需要在新生代之間記錄引用嗎?這是不必要的,原因在於每次GC時,所有新生代都會被掃描,所以只需要記錄老年代到新生代之間的引用。
要注意的是,如果引用的物件很多,賦值器需要對每個參考做處理,賦值器開銷會很大,為了解決賦值器開銷這個問題,在G1 中又引入了另外一個概念,卡表(Card Table)。一個Card Table將一個分區在邏輯上劃分為固定大小的連續區域,每個區域稱之為卡片。卡片通常較小,介於128到512位元組之間。 Card Table通常為位元組陣列,由Card的索引(即陣列下標)來標識每個分區的空間位址。預設情況下,每個卡都未被引用。當一個位址空間被引用時,這個位址空間對應的陣列索引的值被標記為」0″,即標記為髒被引用,此外RSet也將這個陣列下標記錄下來。一般情況下,這個RSet其實是一個Hash Table,Key是別的Region的起始位址,Value是一個集合,裡面的元素是Card Table的Index。
Young GC 階段:
階段1:根掃描
靜態和本地物件被掃描
處理dirty card隊列更新RS
偵測從年輕代指向年老代的物件
拷貝存活的物件到survivor/old區域
軟引用,弱引用,虛引用處理
在此階段,G1 GC 對根進行標記。此階段與常規的 (STW) 年輕代垃圾回收密切相關。
G1 GC 在初始標記的存活區掃描對老年代的引用,並標記被引用的物件。該階段與應用程式(非 STW)同時運行,並且只有完成該階段後,才能開始下一次 STW 年輕代垃圾回收。
G1 GC 在整個堆疊中尋找可存取的(存活的)物件。此階段與應用程式同時運行,可以被 STW 年輕代垃圾回收中斷
該階段是 STW 回收,幫助完成標記週期。 G1 GC 清空 SATB 緩衝區,追蹤未被存取的存活對象,並執行引用處理。
在這個最後階段,G1 GC 執行統計和 RSet 淨化的 STW 操作。在統計期間,G1 GC 會識別完全空閒的區域和可供混合垃圾回收的區域。清理階段在將空白區域重設並返回空閒清單時為部分並發。
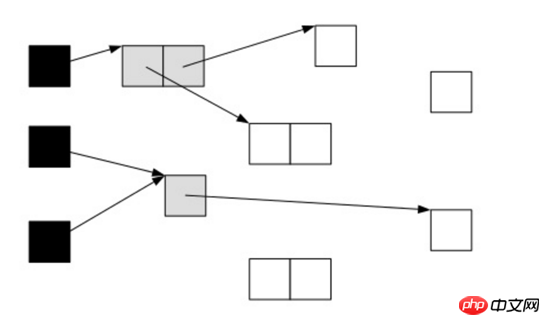

遍歷了所有可達的物件後,所有可達的物件都變成了黑色。不可達的物件即為白色,需要被清理。

這看起來很美好,但是如果在標記過程中,應用程式也在運行,那麼物件的指標就有可能改變。這樣的話,我們就會遇到一個問題:物件遺失問題
我們看下面一種情況,當垃圾收集器掃描到下面情況時:

這時候應用程式執行了以下操作:
A.c=C
B.c=null
這樣,物件的狀態圖變成如下情形:

這時候垃圾收集器再標記掃描的時候就會下圖成這樣:

很顯然,此時C是白色,被認為是垃圾需要清理掉,顯然這是不合理的。那我們如何保證應用程式在運作的時候,GC標記的物件不會遺失呢?有如下2可行的方式:
在插入的時候記錄物件
在刪除的時候記錄物件
剛好這對應CMS和G1的2種不同實作方式:
在CMS採用的是增量更新(Incremental update),只要在寫入屏障(write barrier)裡發現要有一個白物件的引用被賦值到一個黑物件的欄位裡,那就把這個白物件變成灰色的。即插入的時候記錄下來。
在G1中,使用的是STAB(snapshot-at-the-beginning)的方式,刪除的時候記錄所有的對象,它有3個步驟:
1,在開始標記的時候產生一個快照圖標記存活對象
2,在並發標記的時候所有被改變的對象入隊(在write barrier裡把所有舊的引用所指向的對像都變成非白的)
3,可能存在遊離的垃圾,將在下次被收集
這樣,G1到現在可以知道哪些老的分區可回收垃圾最多。 當全域並發標記完成後,在某個時刻,就開始了Mix GC。這些垃圾回收被稱為「混合式」是因為他們不僅進行正常的新生代垃圾收集,同時也回收部分後台掃描線程標記的分區。混合式垃圾收集如下圖:

混合式GC也是採用的複製的清理策略,當GC完成後,會重新釋放空間。

至此,混合式GC告一段落了。下一小節我們講進入調優實踐。
MaxGCPauseMillis調優
前面介紹過使用GC的最基本的參數:
##- XX:+UseG1GC -Xmx32g -XX:MaxGCPauseMillis=200前面2個參數都好理解,後面這個MaxGCPauseMillis參數該怎麼配置呢?這個參數從字面上的意思來看,就是允許的GC最大的暫停時間。 G1盡量確保每次GC暫停的時間都在設定的MaxGCPauseMillis範圍內。 那G1是如何做到最大暫停時間的呢?這牽涉到另一個概念,CSet(collection set)。它的意思是在一次垃圾收集器中被收集的區域集合。如果邏輯處理器不只八個,則將 n 的值設為邏輯處理器數的 5/8 左右。這適用於大多數情況,除非是較大的 SPARC 系統,其中 n 的值可以是邏輯處理器數的 5/16 左右。
-XX:ConcGCThreads=n
設定並行標記的執行緒數。將 n 設定為平行垃圾回收執行緒數 (ParallelGCThreads) 的 1/4 左右。
-XX:InitiatingHeapOccupancyPercent=45
設定觸發標記週期的 Java 堆佔用率閾值。預設佔用率是整個 Java 堆的 45%。
避免使用下列參數:
避免使用 -Xmn 選項或 -XX:NewRatio 等其他相關選項明確設定年輕代大小。固定年輕代的大小會覆蓋暫停時間目標。
觸發Full GC
在某些情況下,G1觸發了Full GC,這時G1會退化使用Serial收集器來完成垃圾的清理工作,它僅使用單一執行緒來完成GC工作,GC暫停時間將達到秒級別的。整個應用程式處於假死狀態,不能處理任何請求,我們的程式當然不希望看到這些。那麼發生Full GC的情況有哪些呢?
並發模式失敗
G1啟動標記週期,但在Mix GC之前,老年代就被填滿,這時候G1會放棄標記週期。在這種情況下,需要增加堆大小,或調整週期(例如增加執行緒數-XX:ConcGCThreads等)。
晉升失敗或疏散失敗
G1在進行GC的時候沒有足夠的記憶體供存活物件或晉升物件使用,由此觸發了Full GC。可以在日誌中看到(to-space exhausted)或(to-space overflow)。解決這種問題的方式是:
a,增加 -XX:G1ReservePercent 選項的值(並相應增加總的堆大小),為「目標空間」增加預留內存量。
b,透過減少 -XX:InitiatingHeapOccupancyPercent 提前啟動標記週期。
c,也可以透過增加 -XX:ConcGCThreads 選項的值來增加並行標記執行緒的數目。
巨型物件分配失敗
當巨型物件找不到適當的空間進行分配時,就會啟動Full GC,來釋放空間。在這種情況下,應該避免分配大量的巨型對象,增加記憶體或增大-XX:G1HeapRegionSize,使巨型物件不再是巨型物件。
由於篇幅有限,G1還有很多調優實踐,在此就不一一列出了,大家在平常的實踐中可以慢慢探索。最後,期待java 9能正式發布,預設使用G1為垃圾收集器的java效能會不會又進步呢?
以上是解析Java G1垃圾收集器的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































