

最近一直在做訂單類別的項目,使用了事務。我們的資料庫選用的是MySql,儲存引擎選用innoDB,innoDB對交易有著良好的支援。這篇文章我們一起來扒一扒事務相關的知識。
為什麼要有事務?
事務廣泛的運用於訂單系統、銀行系統等多種場景。如果有以下一個場景:A用戶和B用戶是銀行的存戶。現在A要給B轉帳500元。那麼需要做以下幾件事:
1. 檢查A的帳戶餘額>500元;
2. A帳戶扣除500元;
3. B帳戶增加500元;
正常的流程走下來,A帳戶扣了500,B帳戶加了500,皆大歡喜。那如果A帳戶扣了錢之後,系統出故障了呢? A白白損失了500,而B也沒有收到本該屬於他的500。以上的案例中,隱藏著一個前提條件:A扣錢和B加錢,要嘛同時成功,要嘛同時失敗。事務的需求就在於此。
事務是什麼?
與其給事務定義,不如說一說事務的特性。眾所周知,事務需要滿足ACID四個特性。
1. A(atomicity) 原子性。一個事務的執行被視為一個不可分割的最小單元。事務裡面的操作,要麼全部成功執行,要麼全部失敗回滾,不可以只執行其中的一部分。
2. C(consistency) 一致性。一個事務的執行不應該破壞資料庫的完整性約束。如果上述例子中第2個操作執行後系統崩潰,保證A和B的金錢總和是不會改變的。
3. I(isolation) 隔離性。通常來說,事務之間的行為不應該互相影響。然而實際情況中,事務相互影響的程度受到隔離等級的影響。文章後面會詳述。
4. D(durability) 持久性。事務提交之後,需要將提交的交易持久化到磁碟。即使系統崩潰,提交的資料也不應該遺失。
交易的四個隔離等級
前文中提到,交易的隔離性受到隔離等級的影響。那麼事務的隔離等級是什麼呢?事務的隔離等級可以認為是事務的"自私"程度,它定義了事務之間的可見性。隔離等級分為以下幾種:
1.READ UNCOMMITTED(未提交讀取)。在RU的隔離等級下,交易A對資料做的修改,即使沒有提交,對交易B來說也是可見的,這種問題叫做髒讀。這是隔離程度較低的一種隔離級別,在實際運用上會造成很多問題,因此一般不常用。
2.READ COMMITTED(提交讀取)。在RC的隔離等級下,不會出現髒讀的問題。事務A對數據做的修改,提交之後會對事務B可見,舉例,事務B開啟時讀到數據1,接下來事務A開啟,把這個數據改成2,提交,B再次讀取這個數據,會讀到最新的數據2。在RC的隔離等級下,會出現不可重複讀取的問題。這個隔離等級是許多資料庫的預設隔離等級。
3.REPEATABLE READ(可重複讀取)。在RR的隔離等級下,不會出現不可重複讀取的問題。事務A對資料做的修改,提交之後,對於先於事務A開啟的事務是不可見的。舉例,事務B開啟時讀到數據1,接下來事務A開啟,把這個數據改成2,提交,B再次讀取這個數據,仍然只能讀到1。在RR的隔離等級下,會出現幻讀的問題。幻讀的意思是,當某個事務在讀取某個範圍內的值的時候,另外一個事務在這個範圍內插入了新記錄,那麼之前的事務再次讀取這個範圍的值,會讀取到新插入的資料。 Mysql預設的隔離等級是RR,然而mysql的innoDB引擎間隙鎖定成功解決了幻讀的問題。
4.SERIALIZABLE(可串列化)。可串行化是最高的隔離等級。這種隔離等級強制要求所有事物串列執行,在這種隔離等級下,讀取的每行資料都加鎖,會導致大量的鎖徵用問題,效能最差。
為了幫助理解四種隔離級別,這裡舉個例子。如圖1,事務A和事務B先後開啟,並對資料1進行多次更新。四個小人在不同的時刻開啟事務,可能看到資料1的哪些值呢? 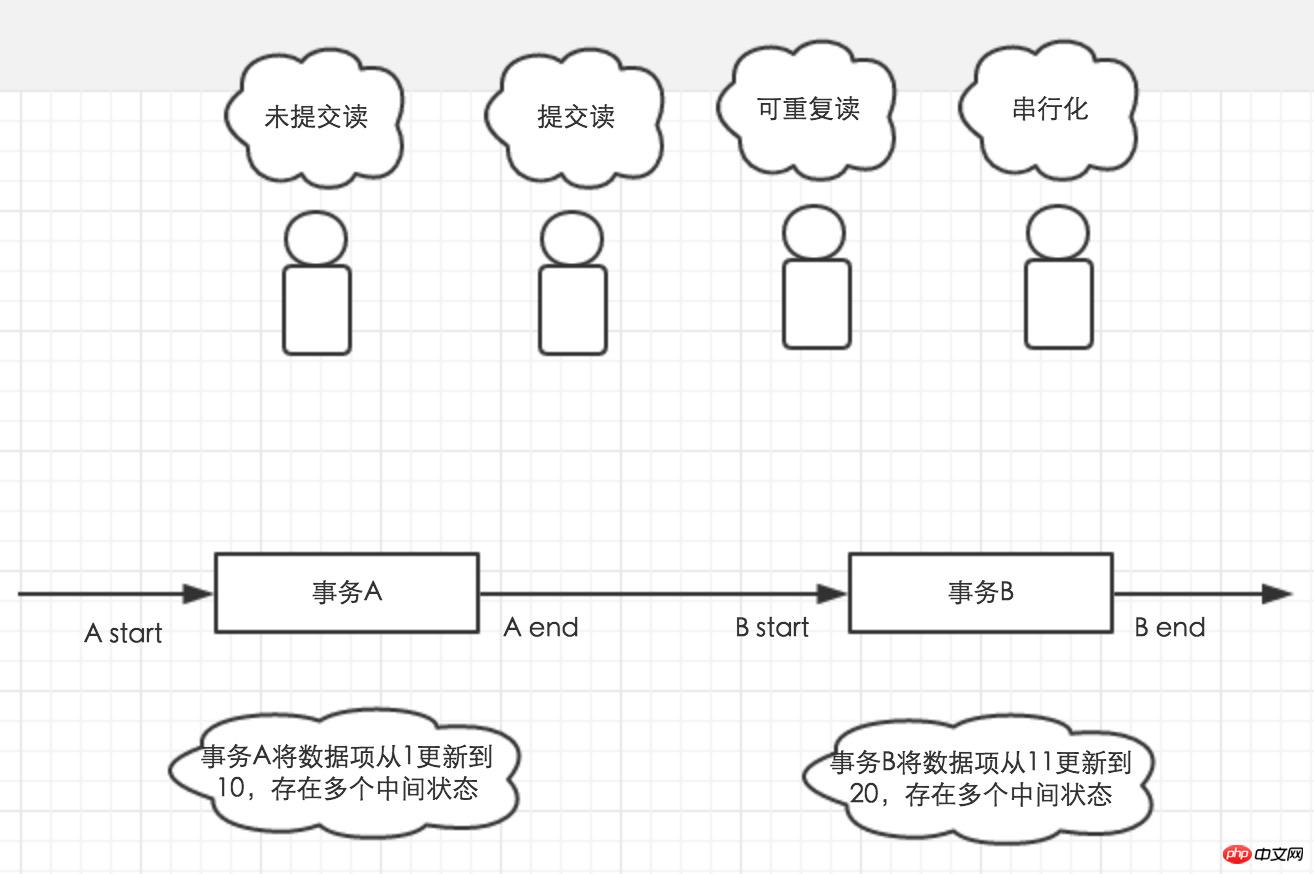
圖1
#第一個小人,可能讀到1-20之間的任何一個。因為未提交讀取的隔離等級下,其他交易對資料的修改也是對目前交易可見的。第二個小人可能讀到1,10和20,他只能讀到其他事務已經提交了的資料。第三個小人所讀到的資料去決於自身事務開啟的時間點。在事務開啟時,讀到的是多少,那麼在事務提交之前讀到的值就是多少。第四個小人,只有在A end 到B start之間開啟,才有可能讀到數據,而在事務A和事務B執行的期間是讀不到數據的。因為第四小人讀取資料是需要加鎖的,在事務A和B執行期間,會佔用資料的寫鎖,導致第四個小人等待鎖。
圖2羅列了不同隔離等級所面對的問題。 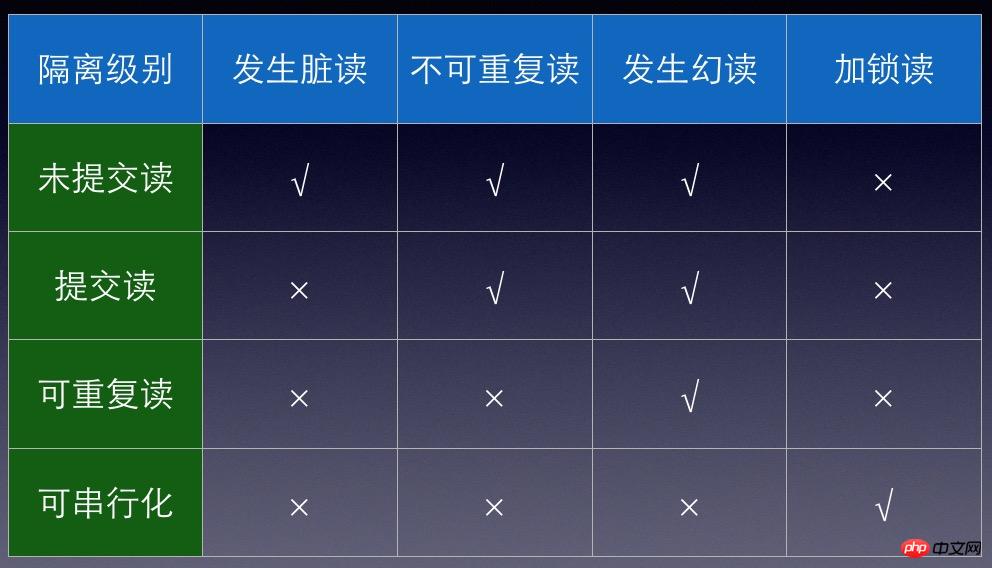
圖2
很顯然,隔離等級越高,它所帶來的資源消耗也就越大(鎖),因此它的並發性能越低。準確的說,在可串列化的隔離等級下,是沒有並發的。 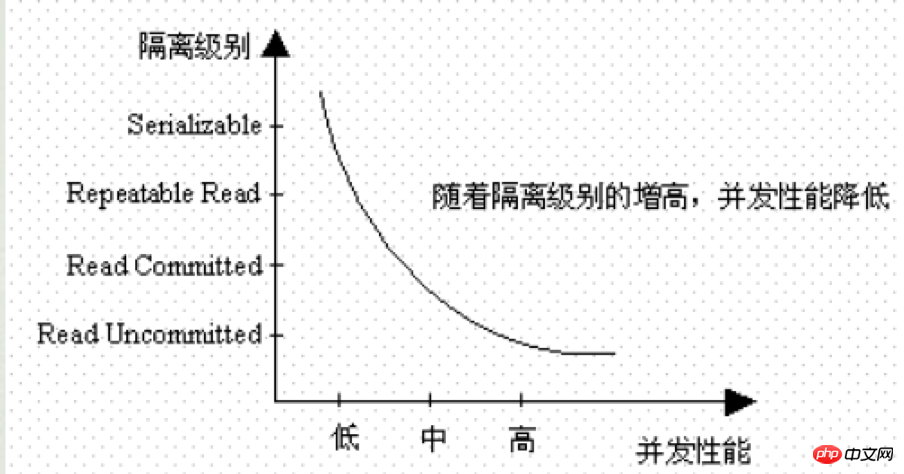
圖3
MySql中的交易
事務的實作是基於資料庫的儲存引擎。不同的儲存引擎對事務的支援程度不一樣。 mysql中支援事務的儲存引擎有innoDB和NDB。 innoDB是mysql預設的儲存引擎,預設的隔離等級是RR,並且在RR的隔離等級下更進一步,透過多版本並發控制(MVCC,Multiversion Concurrency Control )解決不可重複讀取問題,加上間隙鎖(也就是並發控制)解決幻讀問題。因此innoDB的RR隔離等級其實實現了串列化等級的效果,而且保留了比較好的並發效能。
交易的隔離性是透過鎖定實現,而交易的原子性、一致性和持久性則是透過交易日誌實現。說到交易日誌,不得不說的就是redo和undo。
1.redo log
在innoDB的儲存引擎中,交易日誌透過重做(redo)日誌和innoDB儲存引擎的日誌緩衝(InnoDB Log Buffer)實現。當交易開啟時,交易中的操作,都會先寫入儲存引擎的日誌緩衝中,在交易提交之前,這些緩衝的日誌都需要提前刷新到磁碟上持久化,這就是DBA們口中常說的「日誌先行”(Write-Ahead Logging)。當交易提交之後,在Buffer Pool中對應的資料檔案才會慢慢刷新到磁碟。此時如果資料庫崩潰或當機,那麼當系統重新啟動進行復原時,就可以根據redo log中記錄的日誌,把資料庫還原到崩潰前的一個狀態。未完成的事務,可以繼續提交,也可以選擇回滾,這基於恢復的策略而定。
在系統啟動的時候,就已經為redo log分配了一塊連續的儲存空間,以順序追加的方式記錄Redo Log,透過順序IO來改善效能。所有的交易共享redo log的儲存空間,它們的Redo Log依照語句的執行順序,依序交替的記錄在一起。如下一個簡單範例:
記錄1:
記錄2:
#記錄3:
記錄4:
記錄5:
2.undo log
undo log主要為交易的回溯服務。在事務執行的過程中,除了記錄redo log,也會記錄一定量的undo log。 undo log記錄了資料在每個操作前的狀態,如果事務執行過程中需要回滾,就可以根據undo log進行回滾操作。單一事務的回滾,只會回滾目前交易做的操作,並不會影響到其他的事務做的操作。
以下是undo+redo事務的簡化過程
假設有2個數值,分別為A和B,值為1,2
1. start transaction;
2. 記錄A=1 到undo log;
3. update A = 3;
4. 記錄A=3 到redo log;
5. 記錄B=2 到undo log;
6. update B = 4;
7.記錄B = 4 到redo log;
8. 將redo log刷新到磁碟
9. commit
在1-8的任一步驟系統宕機,交易未提交,該交易就不會對磁碟上的資料做任何影響。如果在8-9之間宕機,恢復之後可以選擇回滾,也可以選擇繼續完成交易提交,因為此時redo log已經持久化。若在9之後系統當機,記憶體映射中變更的資料還來不及刷回磁碟,那麼系統恢復之後,可以根據redo log把資料刷回磁碟。
所以,redo log其實保障的是事務的持久性和一致性,而undo log則保障了事務的原子性。
分散式事務
分散式事務的實作方式有很多,既可以採用innoDB提供的原生的事務支持,也可以採用訊息佇列來實現分散式事務的最終一致性。這裡我們主要聊聊innoDB對分散式事務的支援。 
如圖,mysql的分散式交易模型。模型中分三塊:應用程式(AP)、資源管理器(RM)、事務管理器(TM)。
應用程式定義了交易的邊界,指定需要做哪些事務;
資源管理器提供了存取事務的方法,通常一個資料庫就是一個資源管理器;
#事務管理器協調參與了全域事務中的各個事務。
分散式事務採用兩段式提交(two-phase commit)的方式。第一階段所有的事務節點開始準備,告訴事務管理器ready。第二階段事務管理器告訴每個節點是commit還是rollback。如果有一個節點失敗,就需要全域的節點全部rollback,以此保障事務的原子性。
總結
什麼時候需要使用事務呢?我想,只要業務中需要滿足ACID的場景,都需要事務的支援。尤其在訂單系統、銀行系統中,事務是不可或缺的。這篇文章主要介紹了事務的特性,以及mysql innoDB對事務的支援。與事務相關的知識遠不止文中所說,本文僅作拋磚引玉,不足之處還望讀者多多見諒。
以上是圖文詳解MySql中的事務的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















