

查詢其實就是一系列的子任務組成,優化查詢其實就是:要嘛消除一些子任務,要嘛減少子任務執行的次數。
#1)查詢了不需要的資料:
例如我們透過select 查詢出了大量的結果,取得前面的N行之後就關閉結果集,實際上MySQL會查詢出所有的結果集,客戶端接收部分資料後丟棄剩餘的數據,這裡就存在查詢冗餘。所以我們只需要查詢前面n筆的記錄就好,利用 limit 關鍵字限制。
2)多表關聯時回傳全部的列
我們在進行多表查詢時,常常會碰到
mysql>select * from …….
這樣的查詢其實是非常非常影響效能的,應該用具體的字段名來代替通配符 *
#3)總是取出全部的列
禁止寫出select * 這樣的語句。
在確定了查詢只回傳了所需的資料之後(也就是自訂查詢的特定欄位不要使用通配符* )
接下來關注的應該是回傳結果是否掃描了過多的資料。對於MySQL最簡單的三個指標如下:
(1)回應時間
(2)掃描的行數
(3)傳回的行數。
回應時間
回應時間:包含服務時間(真正的查詢時間)和排隊時間(阻塞等待的時間)。
掃描行數和傳回的行數
分析查詢時,查看該查詢掃描的行數是非常有幫助的,一定程度上說明該查詢的效率高不高。
掃描的行數和存取類型
MySQL有好幾種存取方式可以找到並傳回一行結果:全表掃描、索引掃描、範圍掃描、唯一索引查詢、常數引用等。
這裡加索引的作用就出來了,索引可以讓MySQL以最有效率、掃描行數最少的方式找到記錄。
目的是:找到一個更優的方法來獲得實際需要的結果。
(1)一個複雜查詢還是多個簡單查詢
我們在寫SQL的時候常常需要考慮的一個問題就是:是否需要將一個複雜的查詢分成多個簡單的查詢?
對於MySQL來說,連線和斷開都是非常輕量級的,在傳回一個小的查詢結果方面很有效率。雖然說盡可能少的查詢當然好,但是在衡量了工作量是否明顯減少之後,將大的查詢分解成小的查詢有時還是很有必要的。
(2)切分查詢
分而治之的想法。有時候我們需要將一個大的查詢切分成片,分部分執行,而且分步之間做一個延時,這樣避免了長時間的鎖住很多的資料。
例如我們在刪除數據時delete, 如果一次刪除所有需要刪除的數據,可能長時間佔用事務,但是我們可以分片,將一個大的delete,通過條件限制,分成多個delete執行,這樣就能提高效率。
(3)分解關聯查詢
許多高效能的應用程式都會對關聯查詢拆分,例如:
mysql>select * from tag left join tag_post on tag_post.tag_id=tag.id left join post on tag_post.post_id = post.idwhere tag.tag='mysql';
可以分解成
mysql>select * from tag where tag='mysql';mysql>select * from tag_post where tag_id=1234; mysql>select * from post where post.id in (123,345,456,8933);
這麼分解的原因是什麼呢?
(1)讓快取的效率更高;(例如上面查詢的tag已經被快取了,那麼應用程式就可以跳過第一個查詢了。)
( 2)將查詢分解後,執行單一查詢可以減少鎖定的競爭。
(3)某些情況下效率也會更高,例如上面的分解後用 in 關鍵字查詢,效率更高。
首先來看看查詢執行的路徑的示意圖: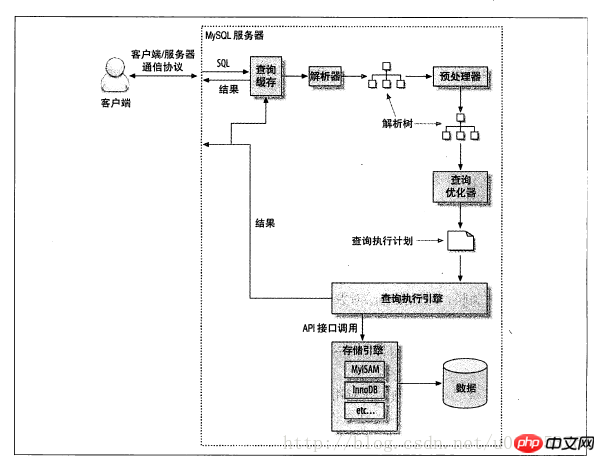
步驟如下:
(1)客戶端發送一條查詢給伺服器;
(2)伺服器先檢查查詢緩存,如果命中了緩存,則立刻返回存在緩存中的結果,否則進入下一步。
(3)伺服器對SQL進行解析、預處理、再由最佳化器產生對應的執行計畫。
(4)MySQL會根據最佳化器產生的執行計畫、呼叫儲存引擎的API來執行查詢。
(5)將結果傳回給客戶端。
我們不需要了解通訊協定內部是如何實現的,只要理解通訊協定是如何運作的。
MySQL的客戶端和伺服器通訊協定是半雙工的,意味著同一時刻,只能有一方向另一方傳送資料。
在解析一個SQL語句之前,如果快取是開啟的,MySQL會優先檢查這個查詢是否會命中查詢快取中的資料。如果命中了快取就會直接從快取中拿到結果集並回傳給客戶端。如果沒有命中緩存就會進入下一階段。
在這部分最重要的就是查詢最佳化器了,一條查詢語句可以有很多種執行方式,最後都會傳回相同的結果,優化器的作用就是找到最高效的執行計劃。
下面給出MySQL查詢優化器能夠自動處理的最佳化類型:
(1)重新定義關聯表的順序:資料表的關聯順序並不總是按照在查詢中指定的順序進行,這與最佳化器有關。(2)將外連接轉換成內連接:
(3)使用等價轉換規則:可以減少一些比較或則移除一些恆等的判斷。例如(5=5 and a>5)將被改寫成(a > 5)。
(4)最佳化COUNT()、 MIN() 和MAX() 函數:索引和列是否允許為空可以幫助優化這類表達式:例如求最小值,利用B-Tree結構特點,只需要查詢B-Tree的最左端記錄就OK了。同理對於求max()函數也是一樣。但是對於COUNT(*)這個函數,MyISAM儲存類型維護了一個變數來專門儲存表中記錄行的總數。
(5)覆寫索引掃描:當索引中的欄位包含所有查詢中需要使用的欄位時候,MySQL可以直接使用索引傳回所需的數據,而無需再查詢對應的資料行。
(6)子查詢最佳化
(8)提前終止查詢:在發現已經滿足查詢需求的時候,MySQL總是能夠立即終止查詢。如 limit 關鍵字。
(9)列表IN 的比較取代OR:MySQL會先將IN語句中的資料排序,再透過二分找出來確定清單中的資料是否滿足需求,這是一個O(logn)的複雜度的操作。 如果等價轉換成 OR 就會變成O(n)的時間複雜度。
不管怎麼說,排序都是一個成本很高的操作,一定要避免對大數據排序。所以我們一定要利用索引列來進行排序,當不能利用索引產生排序結果時候,一定就會存在回表查詢記錄的情況,這時候資料量龐大,會使用檔案排序。
以上是MySQL查詢效能優化詳情介紹的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















