


什麼是蒸餾型?

DeepSeek的蒸餾型模型,也可以在Ollama和Groq Cloud上看到,是原始LLM的較小,更有效的版本,旨在使用較少的資源時匹配較大的模型的性能。 Geoffrey Hinton在2015年引入了這種“蒸餾”過程,一種模型壓縮的一種形式。
目錄:
- 蒸餾型的好處
- 蒸餾型的起源
- 實施LLM蒸餾
- 了解模型蒸餾
- 挑戰和局限性
- 模型蒸餾的未來
- 現實世界應用
- 結論
蒸餾型的好處:
- 較低的內存使用和計算需求
- 培訓和推斷期間能源消耗降低
- 更快的處理速度
相關:使用DeepSeek R1蒸餾模型構建用於AI推理的抹布系統
蒸餾模型的起源:
Hinton的2015年論文“在神經網絡中提取知識”,探索了將大型神經網絡壓縮為較小的知識保護版本。一個較大的“老師”模型訓練了一個較小的“學生”模型,旨在使學生復制老師的鑰匙學習權重。
學生通過最大程度地減少針對兩個目標的錯誤來學習:地面真相(硬目標)和老師的預測(軟目標)。
雙重損失組件:
- 硬損失:針對真標籤的錯誤。
- 軟損失:對教師預測的錯誤。這提供了有關類概率的細微信息。
總損失是這些損失的加權總和,由參數λ(lambda)控制。使用溫度參數(t)修改的軟磁性功能會軟化概率分佈,改善學習。軟損失乘以T²來補償這一點。




Distilbert和Distilgpt2:
Distilbert使用Hinton的方法具有餘弦嵌入損失。它明顯小於伯特基鹼,但精度略有降低。蒸餾2雖然比GPT-2快,但在大型文本數據集上顯示出更高的困惑(性能較低)。
實施LLM蒸餾:
這涉及數據準備,教師模型的選擇以及使用框架,例如擁抱臉部變壓器,張量型模型優化,Pytorch Distiller或DeepSpeed等框架。評估指標包括準確性,推理速度,模型大小和資源利用率。
了解模型蒸餾:
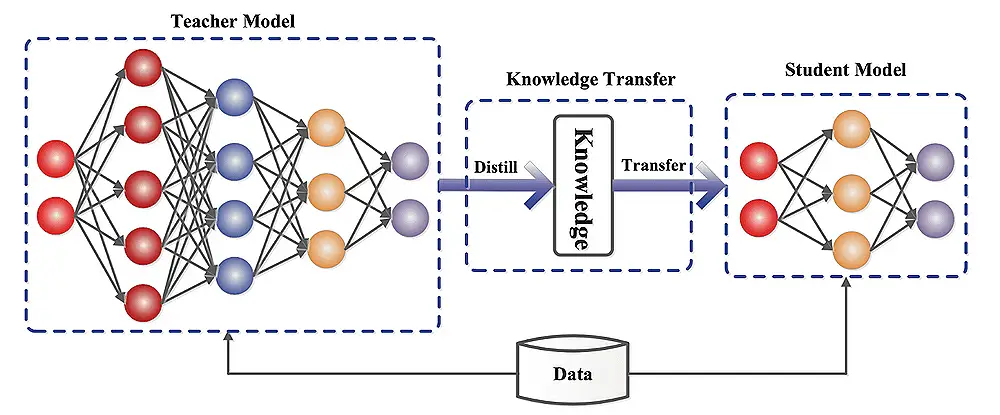
學生模型可以是簡化的教師模型或具有不同的體系結構。蒸餾過程訓練學生通過最大程度地減少預測之間的差異來模仿老師的行為。


挑戰和局限性:
- 與原始模型相比,潛在的準確性損失。
- 配置蒸餾過程和超參數的複雜性。
- 可變有效性取決於域或任務。
模型蒸餾的未來方向:
- 改進的蒸餾技術以減少性能差距。
- 自動蒸餾過程,以便於實施。
- 跨不同機器學習領域的更廣泛應用。
現實世界應用:
- 移動和邊緣計算。
- 節能雲服務。
- 初創企業和研究人員更快的原型製作。
結論:
蒸餾型在性能和效率之間提供了寶貴的平衡。儘管它們可能無法超過原始模型,但其資源需求減少使它們在各種應用中都非常有益。蒸餾模型和原始模型之間的選擇取決於可接受的性能權衡和可用的計算資源。
以上是什麼是蒸餾型?的詳細內容。更多資訊請關注PHP中文網其他相關文章!