

本文探討了檢索功能生成(RAG),這是一種尖端的AI技術,可通過合併檢索和發電能力來提高響應精度。 RAG通過在產生響應之前先從知識庫中首先檢索相關的當前信息來增強AI提供可靠的,上下文相關的答案的能力。討論涵蓋了詳細的抹布工作流程,包括使用矢量數據庫進行有效的數據檢索,距離指標對相似性匹配的重要性以及RAG如何減輕幻覺和造型等常見的AI陷阱。還提供了建立和實施抹布的實用步驟,這是旨在改善基於AI的知識檢索的任何人的綜合指南。
*本文是***數據科學博客馬拉鬆的一部分。
RAG是一種AI方法,可以通過在產生響應之前檢索相關信息來提高答案的準確性。與傳統的AI完全依靠培訓數據不同,RAG搜索數據庫或知識源以獲取最新信息或特定信息。然後,這些信息會告知生成更準確,更可靠的答案。 RAG方法結合了檢索和生成模型,以提高生成內容的質量和準確性,尤其是在NLP任務中。
進一步閱讀:用於知識密集型NLP任務的檢索效果
破布工作流程由兩個主要階段組成:檢索和發電。逐步過程在下面概述。
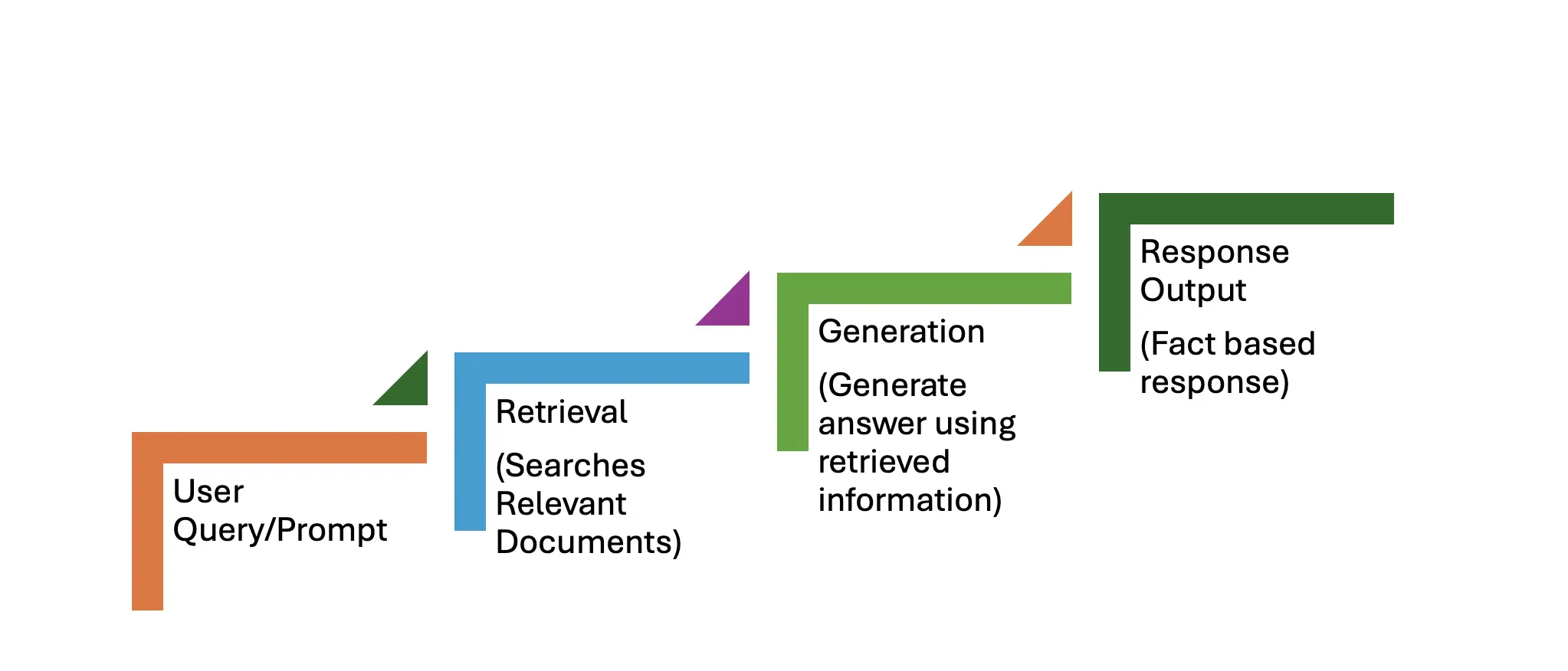
用戶查詢,例如:“量子計算的最新進步是什麼?”作為提示。
此階段涉及三個步驟:
此階段還涉及三個步驟:
該系統返回實際上準確且最新的響應,優於純粹的生成模型可以產生的響應。
在沒有抹布的情況下進行AI進行比較突出了抹布的變革力。傳統模型僅依賴於預訓練的數據,而RAG通過實時信息檢索增強了響應,從而彌合了靜態和動態,上下文意識到的輸出之間的差距。
| 與抹布 | 沒有抹布 |
|---|---|
| 從外部來源檢索當前信息。 | 僅依靠預先訓練的(可能過時的)知識。 |
| 提供特定的解決方案(例如,補丁版本,配置更改)。 | 產生模糊的,廣義的響應,缺乏可操作的細節。 |
| 通過將響應紮根的真實文件中的響應來最大程度地減少幻覺風險。 | 幻覺或不准確的風險更高,尤其是對於最近的信息。 |
| 包括最新的供應商諮詢或安全補丁。 | 可能不知道最近的諮詢或更新。 |
| 結合內部(特定組織)和外部(公共數據庫)信息。 | 無法檢索新的或特定於組織的信息。 |
基於語義相似性,向量數據庫對於在抹布中有效,準確的文檔或數據檢索至關重要。與基於關鍵字的搜索依賴於確切的術語匹配不同,向量數據庫表示文本是高維空間中的向量,將相似的含義聚集在一起。這使它們非常適合抹布系統。向量數據庫存儲了矢量化文檔,從而為AI模型提供了更精確的信息檢索。
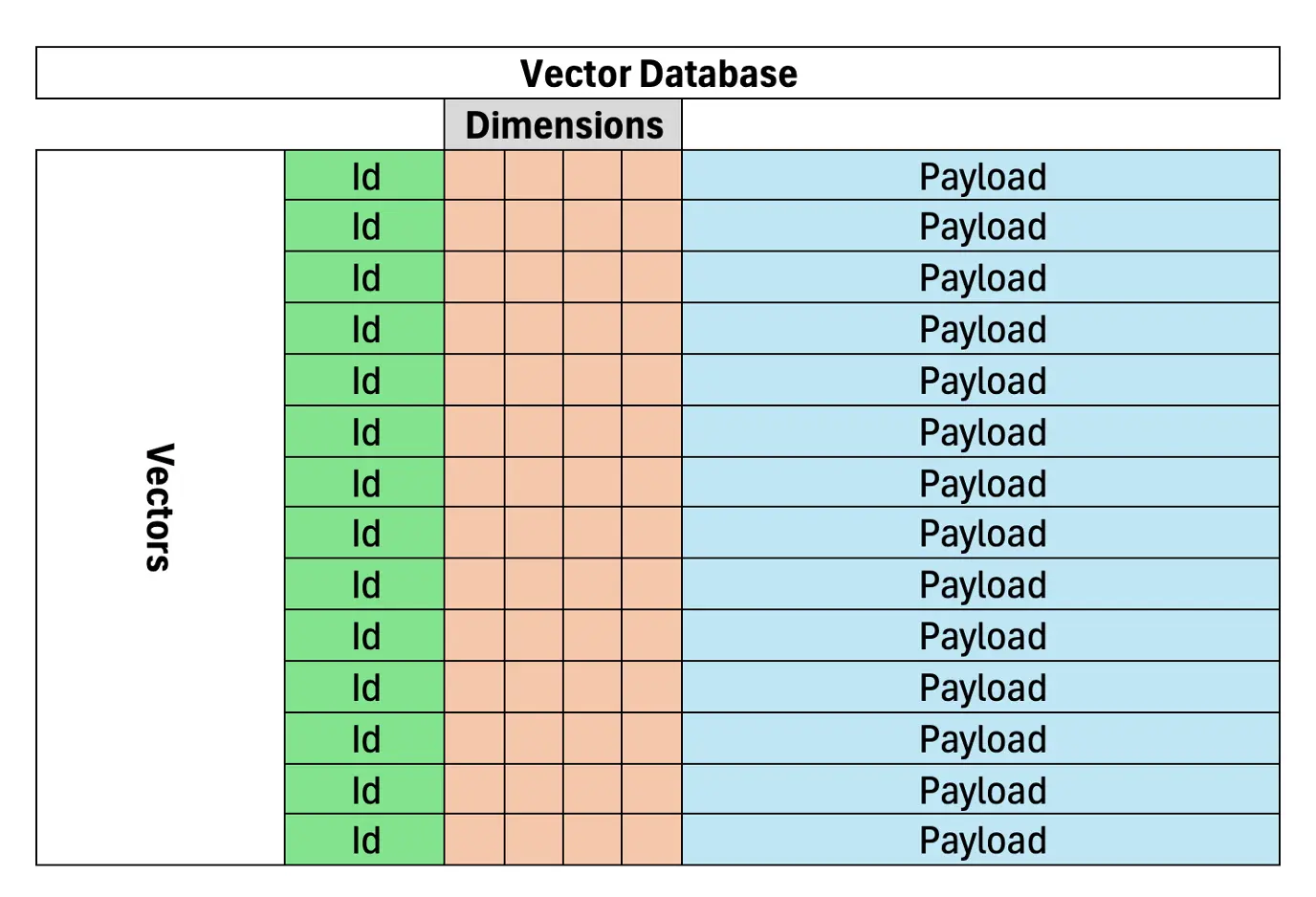
(其餘部分將遵循相似的重新構圖和重組模式,以維護原始信息和圖像放置。)
以上是改善AI幻覺的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















