

Dify 是一個開源 SaaS 平台,用於線上建立 LLM 工作流程。我正在使用 API 在我的應用程式上建立對話式 AI 體驗。我一直在努力獲取 TTS 串流作為 API 回應並播放它。這裡我示範如何處理音訊串流並正確播放。
我使用 API 端點 https://api.dify.ai/v1/chat-messages 進行文字聊天。如果我們在 Dify 應用程式中啟用「文字轉語音」功能,它會在與文字回應相同的串流中傳回音訊資料。
按下新增功能按鈕並新增文字轉語音功能。
您可以使用下列curl指令檢查API的回應。
我用 TypeScript / JavaScript 進行演示,但您可以將相同的邏輯套用到您的程式語言。
首先,讓我們來了解 Dify 的串流使用什麼樣的資料。
Dify 使用以下文字資料格式。它類似於 JSON 行,但並不完全相同。
在回應中,Dify 推送文字答案和音訊資料。
文本答案範例行
音訊資料範例行
我們可以透過檢查事件屬性來區分音訊資料的 JSON 行。音頻 JSON 將 tts_message 作為值。音訊 mp3 二進位檔案以 Base64 格式儲存在 JSON 的音訊屬性中。
即時播放 TTS 音訊時遇到的第一個問題是 JSON 行被分成資料包,並且每個資料包都不是有效的 JSON 資料。
從中間切開的範例包
封包從 JSON 行的中間開始。我們必須組合多個資料包才能獲得有效的 JSON 行。
第二個問題是 JSON 中的音訊資料塊不是有效的音訊資料。資料在 mp3 幀的中間被剪切。
為了處理 JSON 和 mp3 的分割數據,我們必須採取一些聰明的方法。流程如下:
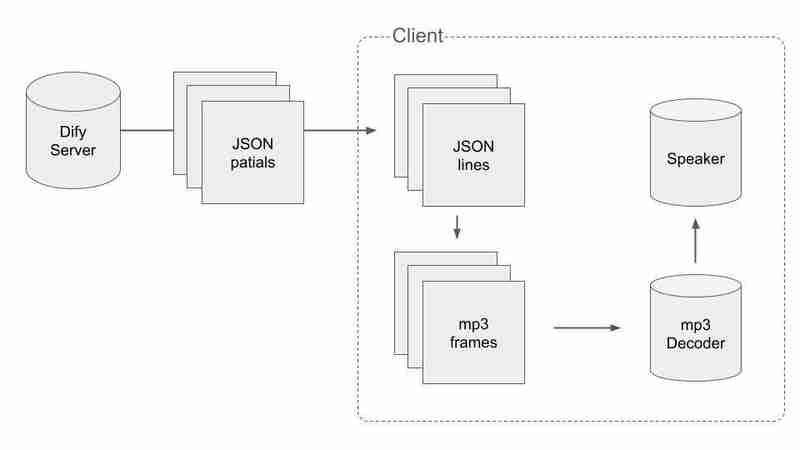
首先,我們必須取得有效的 JSON 數據,並在接收資料包時將其分割為 JSON。當我們得到一個以 n 結尾的資料包時,我們可以說到目前為止收到的資料包的串聯沒有在中間被切斷。偽代碼是這樣的。
其次,我們必須將音訊區塊分割成 mp3 幀。我們將音訊區塊連接成二進位檔案並找到其中的每個 mp3 幀。
這不是分割成 mp3 幀的完整實現。在實際過程中,我們必須考慮當我們從音訊二進位檔案中提取 mp3 幀時存在剩餘位元組並在下一次迭代中使用剩餘位元組作為音訊位元組的開頭的情況。請檢查我的 Github 儲存庫以了解完整的實作。
以上是如何使用Dify API實現即時語音的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































